
In-Context Learning(ICL)在大型预训练语言模型上取得了巨大的成功,但其工作机制仍然是一个悬而未决的问题。本文中,来自北大、清华、微软的研究者将 ICL 理解为一种隐式微调,并提供了经验性证据来证明 ICL 和显式微调在多个层面上表现相似。
继 BERT 之后,研究者们注意到了大规模预训练模型的潜力,不同的预训练任务、模型架构、训练策略等被提出。但 BERT 类模型通常存在两大缺点:一是过分依赖有标签数据;二是存在过拟合现象。
具体而言,现在的语言模型都倾向于两段式框架,即预训练 + 下游任务微调,但是在针对下游任务的微调过程中又需要大量的样本,否则效果很差,然而标注数据的成本高昂。还有就是标注数据有限,模型只能拟合训练数据分布,但数据较少的话容易造成过拟合,致使模型的泛化能力下降。
作为大模型的开路先锋,大型预训练语言模型,特别是 GPT-3 已经显示出令人惊讶的 ICL(In-Context Learning)能力。与微调需要额外的参数更新不同,ICL 只需要一些演示「输入 - 标签」对,模型就可以预测标签甚至是没见过的输入标签。在许多下游任务中,一个大型 GPT 模型可以获得相当好的性能,甚至超过了一些经过监督微调的小型模型。
为何 ICL 的表现如此优秀,在来自 OpenAI 的一篇长达 70 多页的论文《Language Models are Few-Shot Learners》中,他们对 ICL 进行了探索,其目的是让 GPT-3 使用更少的领域数据、且不经过微调去解决问题。
如下图所示,ICL 包含三种分类:Few-shot learning,允许输入数条示例和一则任务说明;One-shot learning,只允许输入一条示例和一则任务说明;Zero-shot learning,不允许输入任何示例,只允许输入一则任务说明。结果显示 ICL 不需要进行反向传播,仅需要把少量标注样本放在输入文本的上下文中即可诱导 GPT-3 输出答案。
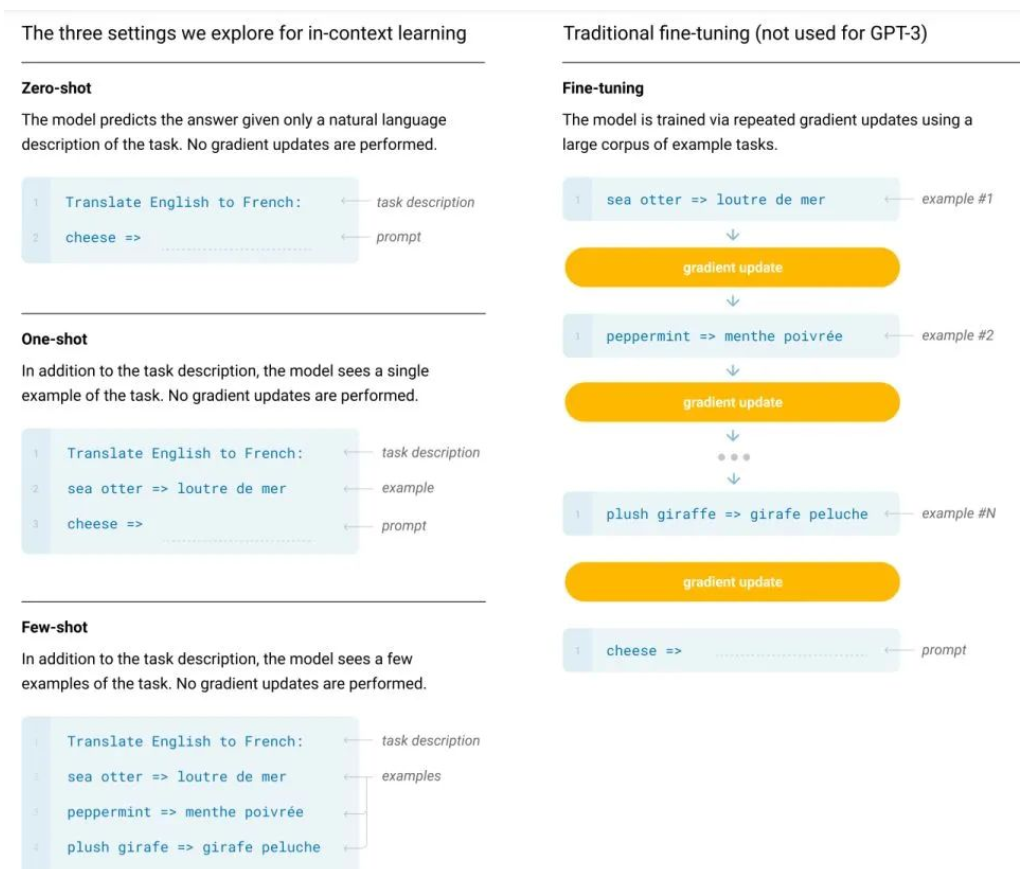 GPT-3 in-context learning
GPT-3 in-context learning
实验证明在 Few-shot 下 GPT-3 有很好的表现:

为什么 GPT 可以在 In-Context 中学习?
尽管 ICL 在性能上取得了巨大的成功,但其工作机制仍然是一个有待研究的开放性问题。为了更好地理解 ICL 是如何工作的,我们接下来介绍一篇来自北大、清华等机构的研究是如何解释的。

-
论文地址:https://arxiv.org/pdf/2212.10559v2.pdf
-
项目地址:https://github.com/microsoft/LMOps
用网友的话来总结,即:「这项工作表明,GPT 自然地学会了使用内部优化来执行某些运行。该研究同时提供了经验性证据来证明 In-Context Learning 和显式微调在多个层面上表现相似。」

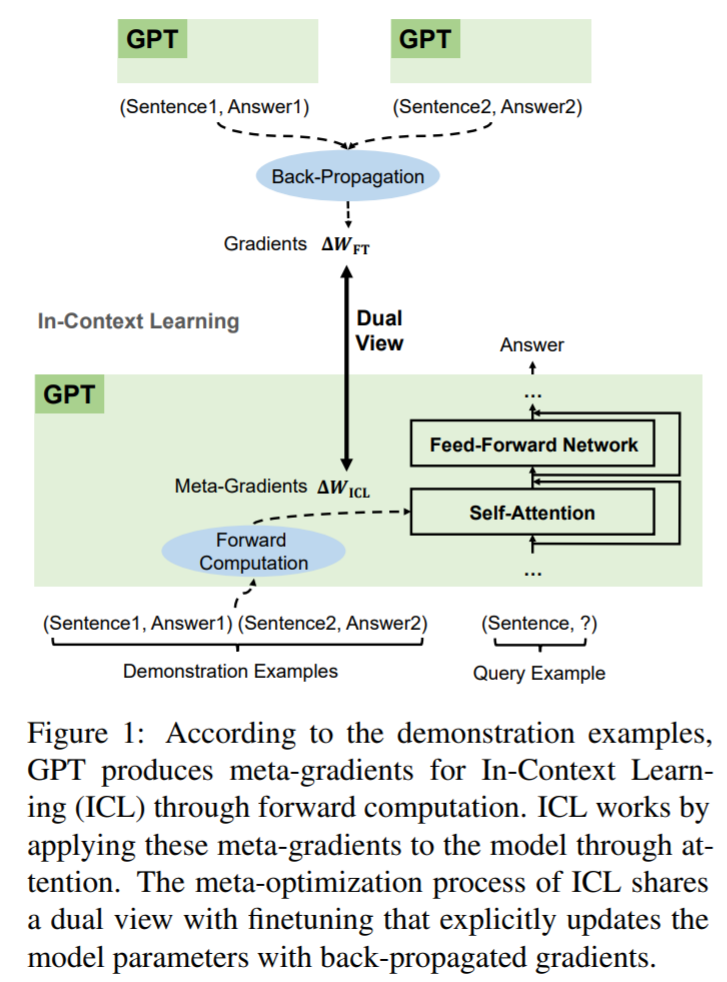
为了更好地理解 ICL 是如何工作的,该研究将语言模型解释为元优化器,ICL 解释为一个元优化过程,并将 ICL 理解为一种隐式微调,试图在基于 GPT 的 ICL 和微调之间建立联系。从理论上讲,该研究发现 Transformer 的注意力具有基于梯度下降的对偶优化形式。
在此基础上,该研究提出了一个新的视角来解释 ICL:GPT 首先根据演示示例生成元梯度,然后将这些元梯度应用于原始 GPT 以构建 ICL 模型。
如图 1 所示,ICL 和显式微调共享基于梯度下降的对偶优化形式。唯一的区别是 ICL 通过前向计算产生元梯度,而微调通过反向传播计算梯度。因此,将 ICL 理解为某种隐式微调是合理的。
内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢