
来自今天的爱可可AI前沿推介
[CV] Multi-Realism Image Compression with a Conditional Generator
E Agustsson, D Minnen, G Toderici, F Mentzer
[Google Research]
基于条件生成器的多(感知)真实性图像压缩
要点:
-
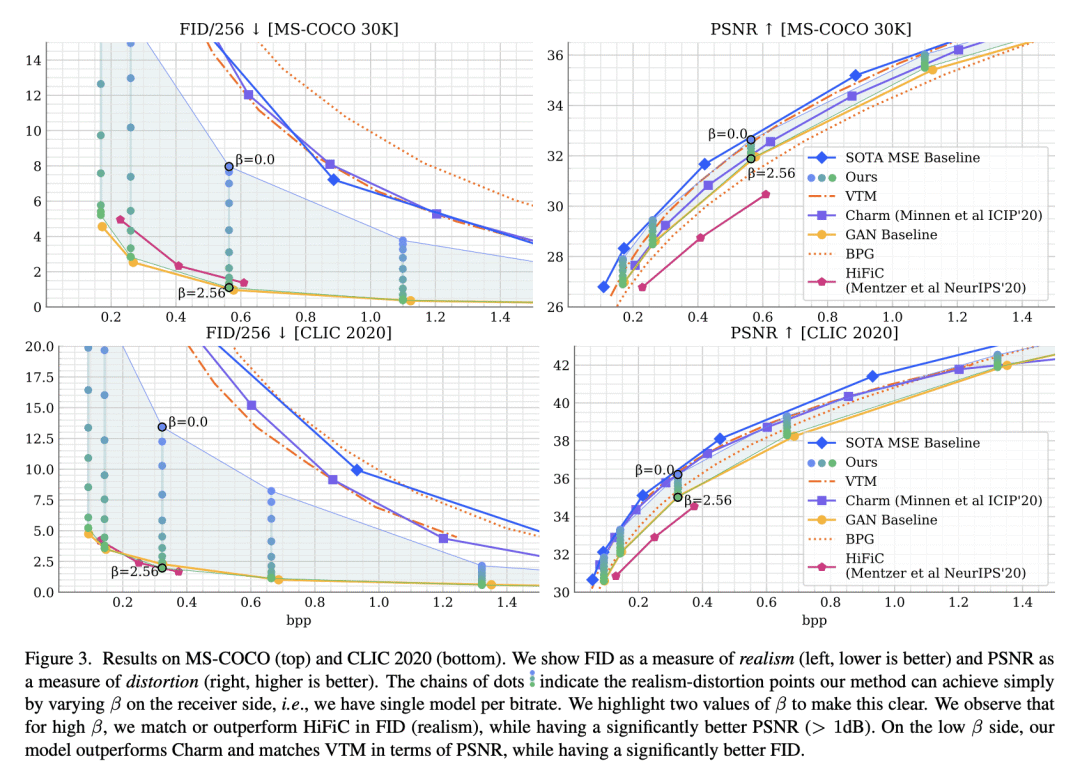
通过优化速率-失真-(感知)真实性权衡,即使是在低比特率下,生成式压缩方法也可以产生细节丰富、逼真的图像; -
针对用户担心产生远离输入图像的误导性重建的问题,通过训练一个可以弥补两个域的解码器来引导失真-(感知)真实性权衡; -
在高分辨率基准数据集中达到了新水平,可在高(感知)真实性(低FID)情况下实现更好的失真,在低失真(高PSNR)的情况下获得更好的(感知)真实性。
摘要:
通过优化速率-失真-(感知)真实性的权衡,生成式压缩方法即使在低速率下也能产生详细、逼真的图像,而不是速率-失真优化模型产生的模糊重建。然而,之前的方法没有明确控制合成了多少细节,这导致了对这些方法的普遍批评:用户可能会担心会产生远离输入图像的误导性重建。本文通过训练一个解码器来缓解这些担忧,该解码器可以连接两种域,并驾驭失真-(感知)真实性权衡。从单个压缩表示中,接收器可以决定重建靠近输入的低MSE重建,重建具有高感知质量的逼真重建,或介于两者之间的任意内容。通过该方法,在失真-(感知)真实性方面开创了一种新的最先进的境界,推动了可实现的失真-(感知)真实性对的前沿,在高真实性时实现了比以往更好的失真,在低失真时实现了更好的真实性。
By optimizing the rate-distortion-realism trade-off, generative compression approaches produce detailed, realistic images, even at low bit rates, instead of the blurry reconstructions produced by rate-distortion optimized models. However, previous methods do not explicitly control how much detail is synthesized, which results in a common criticism of these methods: users might be worried that a misleading reconstruction far from the input image is generated. In this work, we alleviate these concerns by training a decoder that can bridge the two regimes and navigate the distortion-realism trade-off. From a single compressed representation, the receiver can decide to either reconstruct a low mean squared error reconstruction that is close to the input, a realistic reconstruction with high perceptual quality, or anything in between. With our method, we set a new state-of-the-art in distortion-realism, pushing the frontier of achievable distortion-realism pairs, i.e., our method achieves better distortions at high realism and better realism at low distortion than ever before.
论文链接:https://arxiv.org/abs/2212.13824


内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢