
来自今天的爱可可AI前沿推介
[LG] On Implicit Bias in Overparameterized Bilevel Optimization
P Vicol, J Lorraine, F Pedregosa, D Duvenaud, R Grosse
[University of Toronto & Google Brain]
过参数化双层优化中的隐性偏差
要点:
-
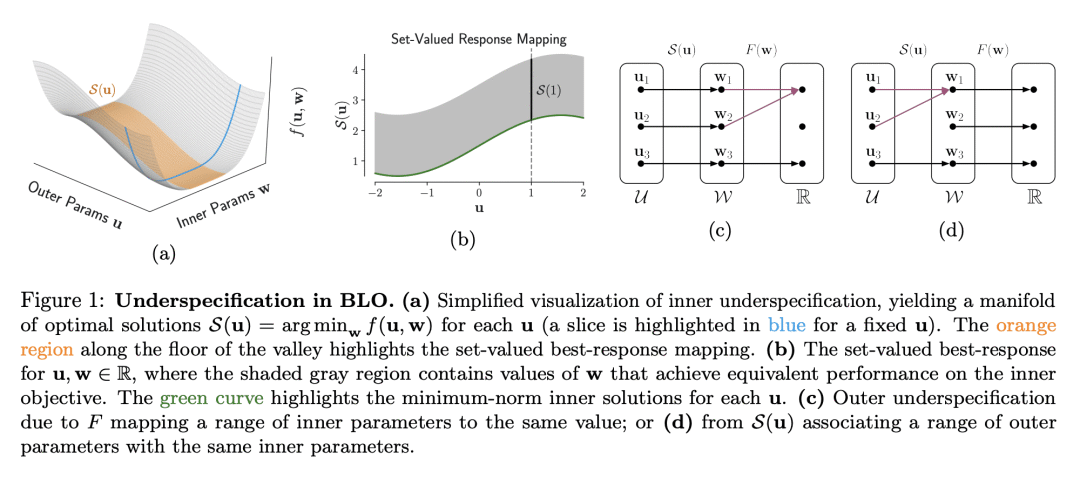
许多机器学习问题涉及双层优化(BLO),双层问题由两个嵌套的子问题组成; -
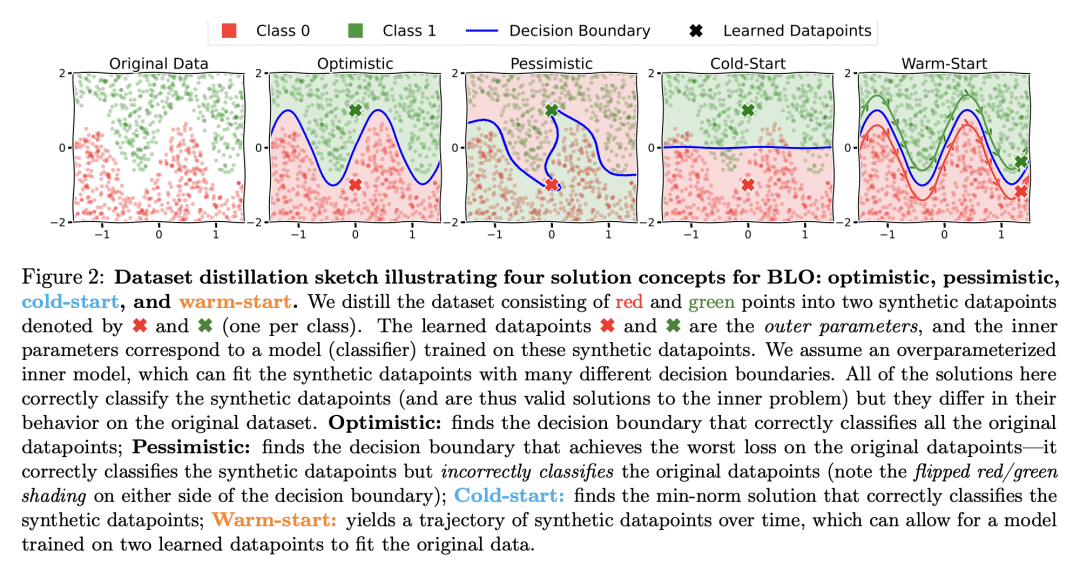
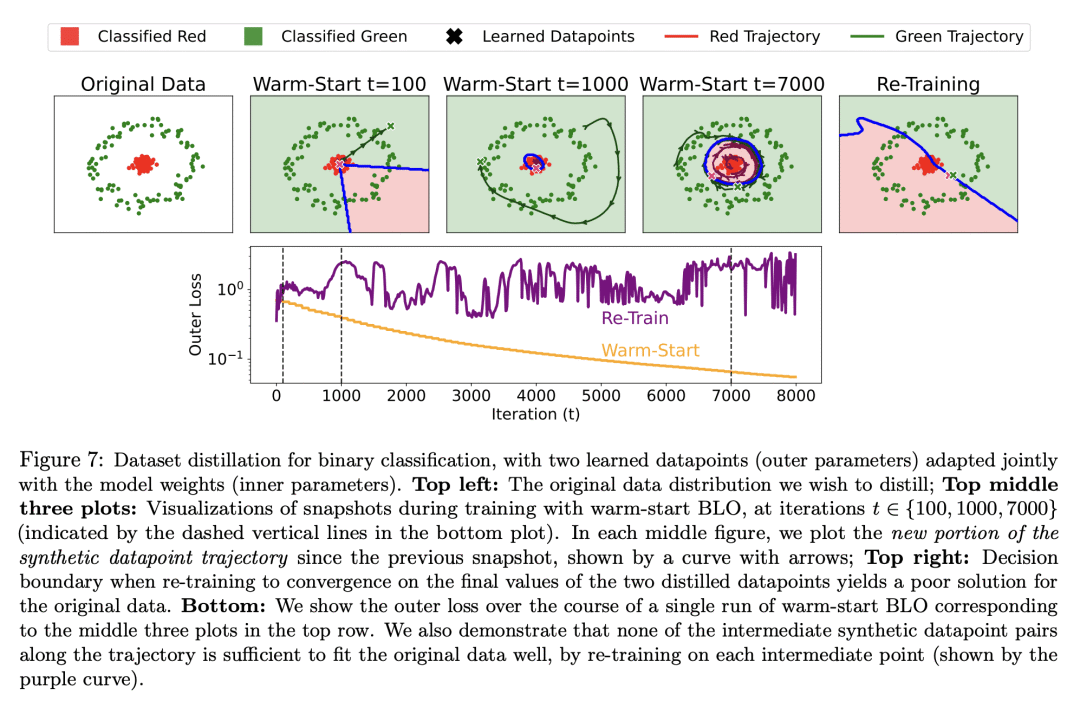
收敛解或长期运行行为在很大程度上取决于冷启动、热启动和其他算法选择; -
即使外部参数是低维的,热启动BLO获得的内部解也可以编码出惊人的关于外部目标的信息。
摘要:
机器学习中的许多问题涉及双层优化(BLO),包括超参数优化、元学习和数据集蒸馏。双层问题由两个嵌套的子问题组成,分别称为外部和内部问题。在实践中,这些子问题中通常至少有一个被过参数化。在这种情况下,在实现同等目标值的最佳选择中有很多方法可供选择。受最近对单层优化中优化算法归纳的隐式偏差的研究启发,本文研究了基于梯度的算法用于双层优化的隐性偏差。本文描述了两种标准的BLO方法——冷启动和热启动——并表明收敛解或长期运行行为在很大程度上取决于这些和其他算法选择,例如超梯度近似。本文还表明,即使外部参数是低维的,热启动BLO获得的内部解也可以编码出惊人的关于外部目标的信息。本文认为,隐性偏差在双层优化研究中应该发挥核心作用,就像在单级神经网络优化研究中一样。
Many problems in machine learning involve bilevel optimization (BLO), including hyperparameter optimization, meta-learning, and dataset distillation. Bilevel problems consist of two nested sub-problems, called the outer and inner problems, respectively. In practice, often at least one of these sub-problems is overparameterized. In this case, there are many ways to choose among optima that achieve equivalent objective values. Inspired by recent studies of the implicit bias induced by optimization algorithms in single-level optimization, we investigate the implicit bias of gradient-based algorithms for bilevel optimization. We delineate two standard BLO methods -- cold-start and warm-start -- and show that the converged solution or long-run behavior depends to a large degree on these and other algorithmic choices, such as the hypergradient approximation. We also show that the inner solutions obtained by warm-start BLO can encode a surprising amount of information about the outer objective, even when the outer parameters are low-dimensional. We believe that implicit bias deserves as central a role in the study of bilevel optimization as it has attained in the study of single-level neural net optimization.
论文链接:https://arxiv.org/abs/2212.14032
内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢