
Transformer 作为 NLP 预训练模型架构,能够有效的在大型未标记的数据上进行学习,研究已经证明,Transformer 是自 BERT 以来 NLP 任务的核心架构。
最近的工作表明,状态空间模型(SSM)是长范围序列建模有利的竞争架构。SSM 在语音生成和 Long Range Arena 基准上取得了 SOTA 成果,甚至优于 Transformer 架构。除了提高准确率之外,基于 SSM 的 routing 层也不会随着序列长度的增长而呈现二次复杂性。
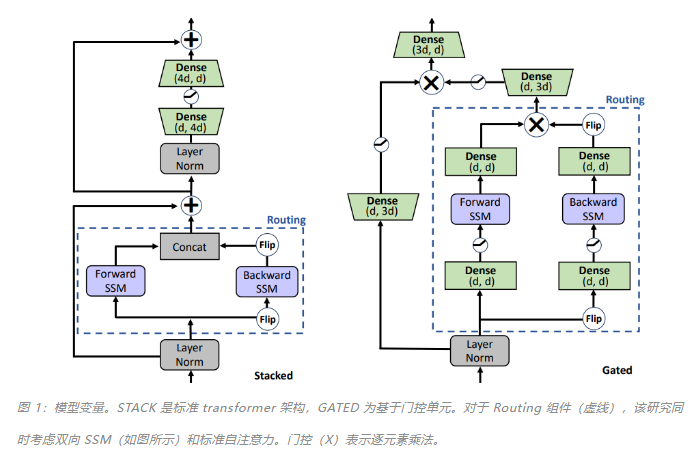
本文中,来自康奈尔大学、 DeepMind 等机构的研究者提出了双向门控 SSM (BiGS),用于无需注意力的预训练,其主要是将 SSM routing 与基于乘法门控(multiplicative gating)的架构相结合。该研究发现 SSM 本身在 NLP 的预训练中表现不佳,但集成到乘法门控架构中后,下游准确率便会提高。
实验表明,在受控设置下对相同数据进行训练,BiGS 能够与 BERT 模型的性能相匹配。通过在更长的实例上进行额外预训练,在将输入序列扩展到 4096 时,模型还能保持线性时间。分析表明,乘法门控是必要的,它修复了 SSM 模型在变长文本输入上的一些特定问题。

论文地址:https://arxiv.org/pdf/2212.10544.pdf
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢