
作者:Damai Dai, Yutao Sun, Li Dong, Yaru Hao,等
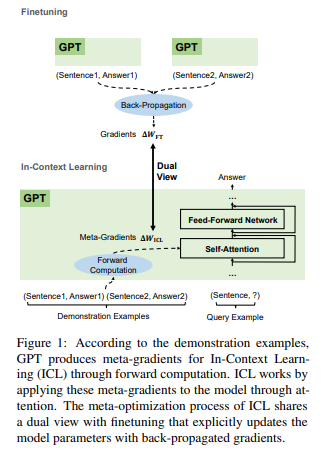
简介:大型预训练语言模型显示出令人惊讶的上下文学习 (ICL) 能力。通过一些演示输入标签对,他们可以预测未见输入的标签,而无需额外的参数更新。尽管在性能上取得了巨大成功,但 ICL 的工作机制仍然是一个悬而未决的问题。为了更好地理解 ICL 的工作原理,本文将语言模型解释为元优化器,并将 ICL 理解为一种隐式微调。从理论上讲,作者发现 Transformer 注意力具有基于梯度下降的双重优化形式。在此之上,作者对ICL的理解是这样的:GPT首先根据demonstration examples产生meta-gradients,然后将这些meta-gradients应用到原来的GPT中来构建ICL模型。实验上,作者基于实际任务综合比较 ICL 和显式微调的行为,以提供支持作者理解的经验证据。结果证明,ICL 在预测级别、表示级别和注意行为级别的行为类似于显式微调。此外,受作者对元优化的理解的启发,作者通过类比基于动量的梯度下降算法设计了一种基于动量的注意力。它始终优于 vanilla attention 的性能从另一个方面再次支持了作者的理解,更重要的是,它显示了将作者的理解用于未来模型设计的潜力。
论文下载:https://arxiv.org/pdf/2212.10559.pdf
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢