
来自今天的爱可可AI前沿推介
[CL] FiDO: Fusion-in-Decoder optimized for stronger performance and faster inference
M d Jong, Y Zemlyanskiy, J Ainslie, N FitzGerald, S Sanghai...
[Google Research & University of Southern California]
FiDO: 面向更强性能和更快推理的解码器内融合优化
要点:
-
解码器内融合(FiD)是一种功能强大的检索增强语言模型,在许多知识稠密的NLP任务上达到了最佳指标; -
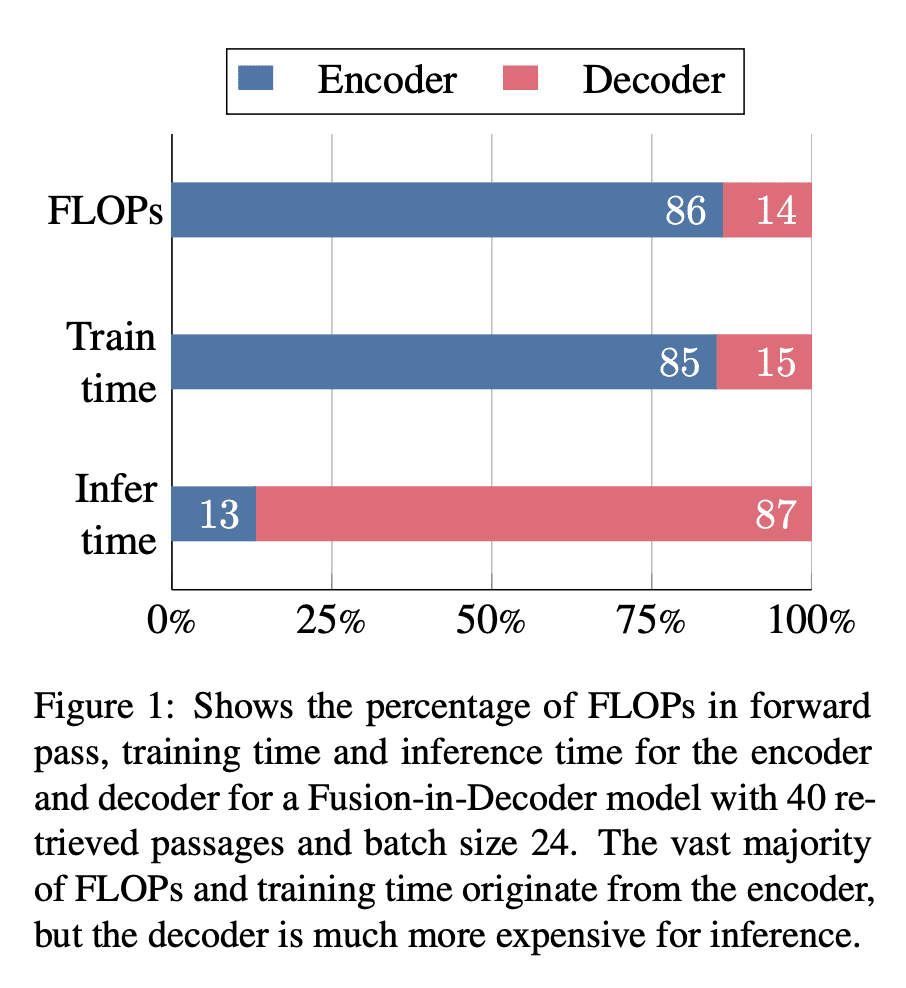
推理时间的大部分是由解码器中的内存带宽约束造成的,本文提出两种简单的FiD架构改进,可将推理加速7倍; -
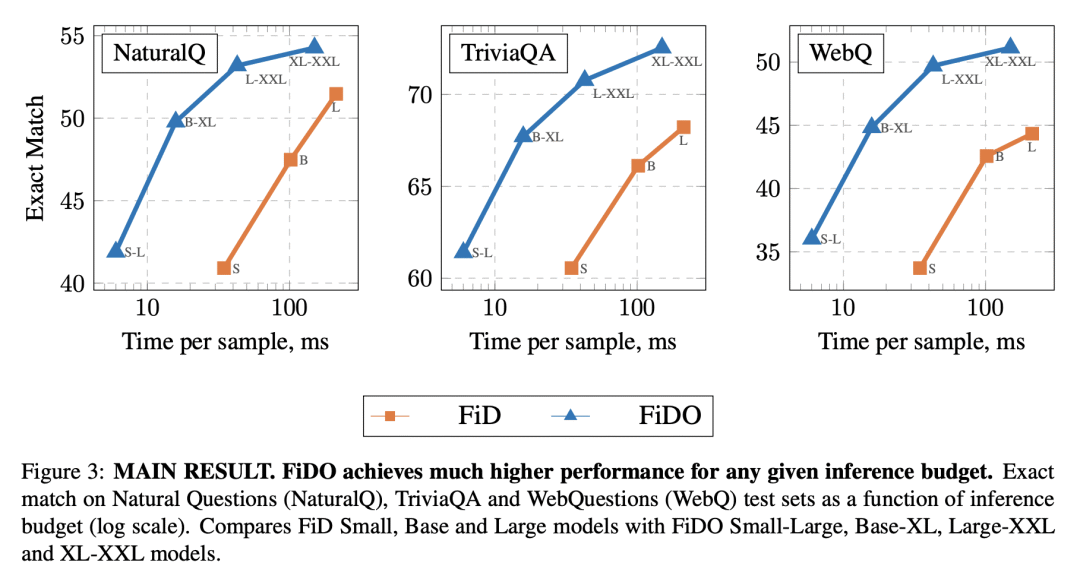
提出FiDO,一种FiD的扩展,移除了大部分交叉注意力层并采用多查询注意力来大大降低解码器的成本。
摘要:
解码器内融合(FiD)是一个强大的检索增强语言模型,在许多知识密集型NLP任务上达到了最佳指标。然而,FiD受到非常昂贵的推理的影响。大多数推理时间是由解码器中的内存带宽约束引起的,并提议对FiD架构进行两个简单的更改,以将推断速度提高7倍。更快的解码器推断允许使用更大的解码器。将上述修改的FiD表示为FiDO,并表明它比现有的FiD模型更能提高性能,用于广泛的推理预算。例如,FiDO-Large-XXL比FiD-Base执行更快的推理,并且比FiD-Large性能更好。
Fusion-in-Decoder (FiD) is a powerful retrieval-augmented language model that sets the state-of-the-art on many knowledge-intensive NLP tasks. However, FiD suffers from very expensive inference. We show that the majority of inference time results from memory bandwidth constraints in the decoder, and propose two simple changes to the FiD architecture to speed up inference by 7x. The faster decoder inference then allows for a much larger decoder. We denote FiD with the above modifications as FiDO, and show that it strongly improves performance over existing FiD models for a wide range of inference budgets. For example, FiDO-Large-XXL performs faster inference than FiD-Base and achieves better performance than FiD-Large.
论文链接:https://arxiv.org/abs/2212.08153

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢