
来自爱可可AI前沿推介
[CV] SinDDM: A Single Image Denoising Diffusion Model
V Kulikov, S Yadin, M Kleiner, T Michaeli
[Technion – Israel Institute of Technology]
SinDDM: 单图像去噪扩散模型
要点:
-
去噪扩散模型(DDM)为图像生成、编辑和恢复带来了显著的性能提升; -
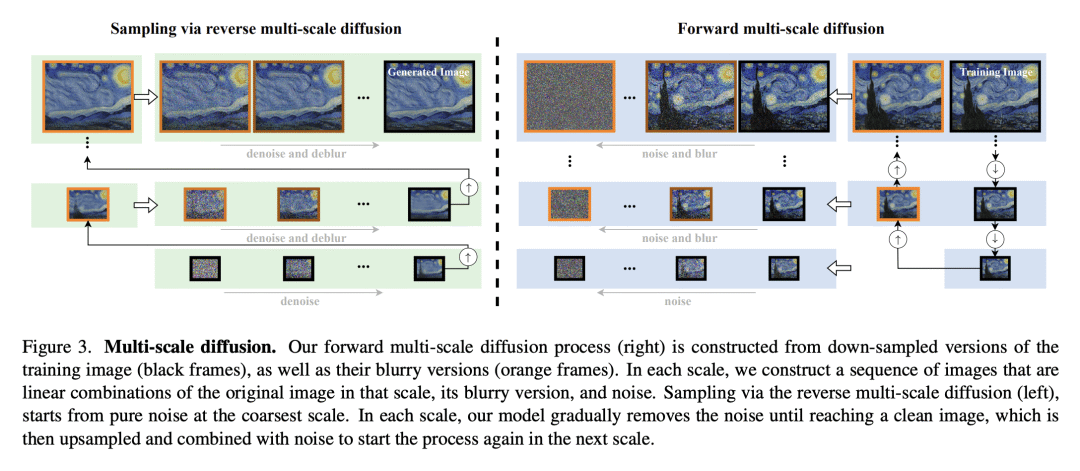
提出一种在单幅图像上训练DDM的框架SinDDM,用多尺度扩散过程和轻量去噪器来驱动反向扩散过程; -
SinDDM适用于各种任务,如风格迁移和用单幅图像引导生成,并且能生成任意维的多样高质量样本。
摘要:
去噪扩散模型(DDM)带来了图像生成、编辑和恢复方面的惊人性能飞跃。然而,现有的DDM用非常大的数据集进行训练。本文提出一种在单幅图像上训练DDM的框架。创建SinDDM的方法通过用多尺度扩散过程学习训练图像的内部统计信息。为了推动反向扩散过程,用全卷积轻量去噪器,该去噪器取决于噪音水平和规模。该架构允许以从粗到细的方式生成任意维的样本。SinDDM可生成各种高质量样本,并适用于各种任务,包括样式迁移和协调。此外,它很容易受到外部监督的指导。特别是,用预训练的CLIP模型演示了从单幅图像进行文本引导生成。
https://arxiv.org/abs/2211.16582
Denoising diffusion models (DDMs) have led to staggering performance leaps in image generation, editing and restoration. However, existing DDMs use very large datasets for training. Here, we introduce a framework for training a DDM on a single image. Our method, which we coin SinDDM, learns the internal statistics of the training image by using a multi-scale diffusion process. To drive the reverse diffusion process, we use a fully-convolutional light-weight denoiser, which is conditioned on both the noise level and the scale. This architecture allows generating samples of arbitrary dimensions, in a coarse-to-fine manner. As we illustrate, SinDDM generates diverse high-quality samples, and is applicable in a wide array of tasks, including style transfer and harmonization. Furthermore, it can be easily guided by external supervision. Particularly, we demonstrate text-guided generation from a single image using a pre-trained CLIP model.
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢