
来自今天的爱可可AI前沿推介
[CL] Tokenization Consistency Matters for Generative Models on Extractive NLP Tasks
K Sun, P Qi, Y Zhang, L Liu, W Y Wang, Z Huang
[University of Washington & AWS AI Labs]
提取式NLP任务生成模型的一致Tokenization
要点:
-
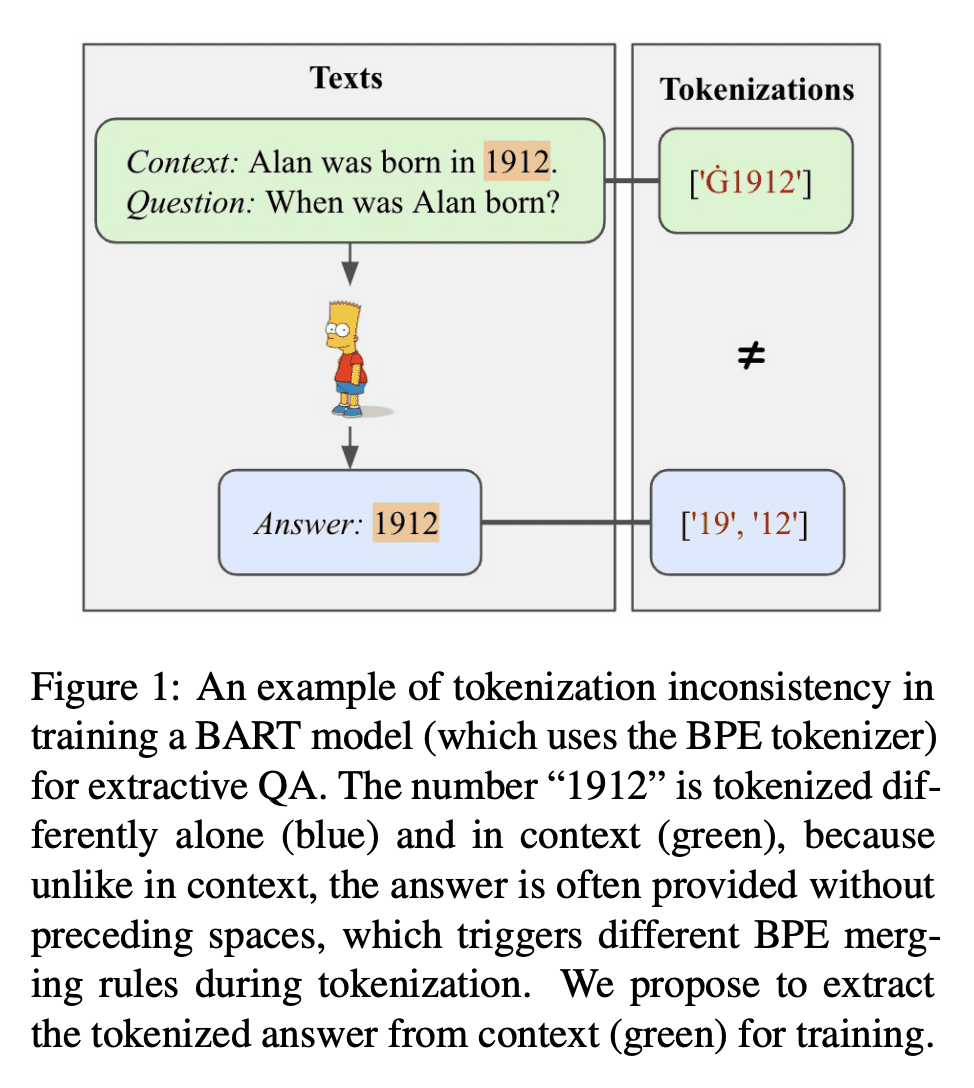
在训练生成模型以解决提取式任务(如提取式问答)时,Tokenization不一致是个往往被忽略的问题; -
提出一种简单的解决方案来保证输入和输出的一致性Tokenization; -
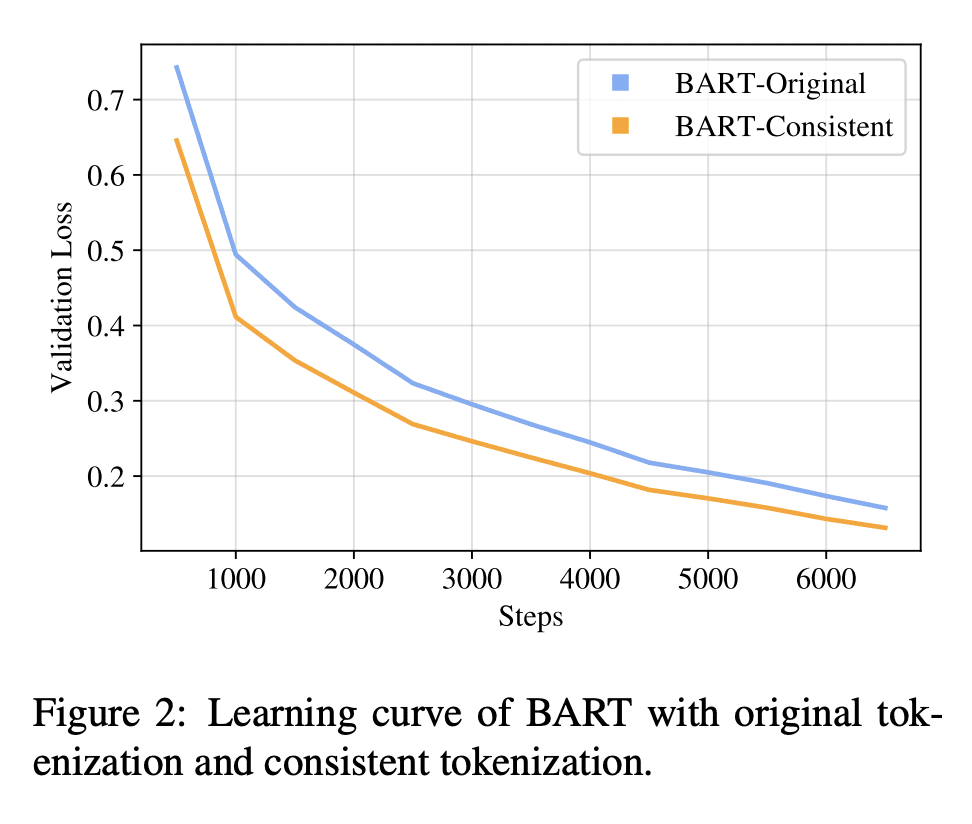
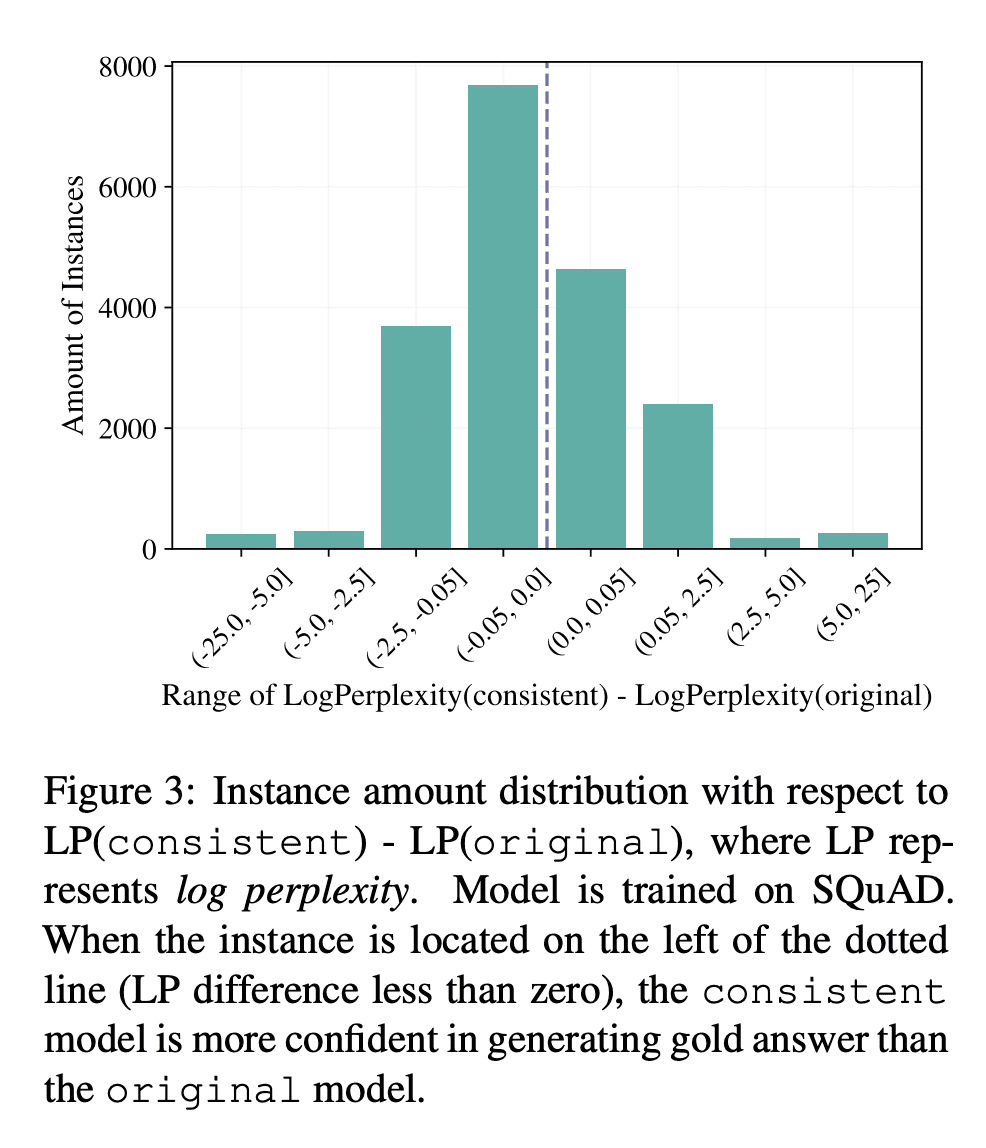
当使用一致tokenized实例训练时,模型在域内性能、收敛速度、跨域适应性和文本幻觉方面都有所收益。
摘要:
生成模型已被广泛应用于解决提取式任务,其中提取部分输入以形成所需的输出,并取得了显著成功。例如,在提取式问答(QA)中,生成模型不断产生最先进的结果。本文确定了在训练这些模型时往往被忽视的令牌化不一致问题。在输入和输出被tokenizer不一致tokenize后,这个问题会损害这些任务的提取性质,从而导致性能下降和幻觉。本文提出一个简单而有效的解决方案,并进行提取时问答的案例研究。通过一致tokenization,该模型在域内和域外数据集中的表现都更好,当BART模型在SQuAD上训练并在8个QA数据集上进行评估时,平均F2增益为+1.7。此外,模型收敛得更快,不太可能产生非上下文的答案。通过这些发现,希望更多地关注在解决提取式任务时应如何进行tokenization,并建议在训练期间应用一致的tokenization。
Generative models have been widely applied to solve extractive tasks, where parts of the input is extracted to form the desired output, and achieved significant success. For example, in extractive question answering (QA), generative models have constantly yielded state-of-the-art results. In this work, we identify the issue of tokenization inconsistency that is commonly neglected in training these models. This issue damages the extractive nature of these tasks after the input and output are tokenized inconsistently by the tokenizer, and thus leads to performance drop as well as hallucination. We propose a simple yet effective fix to this issue and conduct a case study on extractive QA. We show that, with consistent tokenization, the model performs better in both in-domain and out-of-domain datasets, with a notable average of +1.7 F2 gain when a BART model is trained on SQuAD and evaluated on 8 QA datasets. Further, the model converges faster, and becomes less likely to generate out-of-context answers. With these findings, we would like to call for more attention on how tokenization should be done when solving extractive tasks and recommend applying consistent tokenization during training.
论文链接:https://arxiv.org/abs/2212.09912
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢