
来自今天的爱可可AI前沿推介
[LG] Multi-modal Molecule Structure-text Model for Text-based Retrieval and Editing
S Liu, W Nie, C Wang, J Lu, Z Qiao, L Liu...
[Mila-Quebec Artificial Intelligence Institute & Nvidia Research & ...]
面向基于文本检索和编辑的多模态分子结构-文本模型
要点:
-
构建了迄今为止最大的多模态数据集PubChemSTM,包括超过280K的化学结构-文本对; -
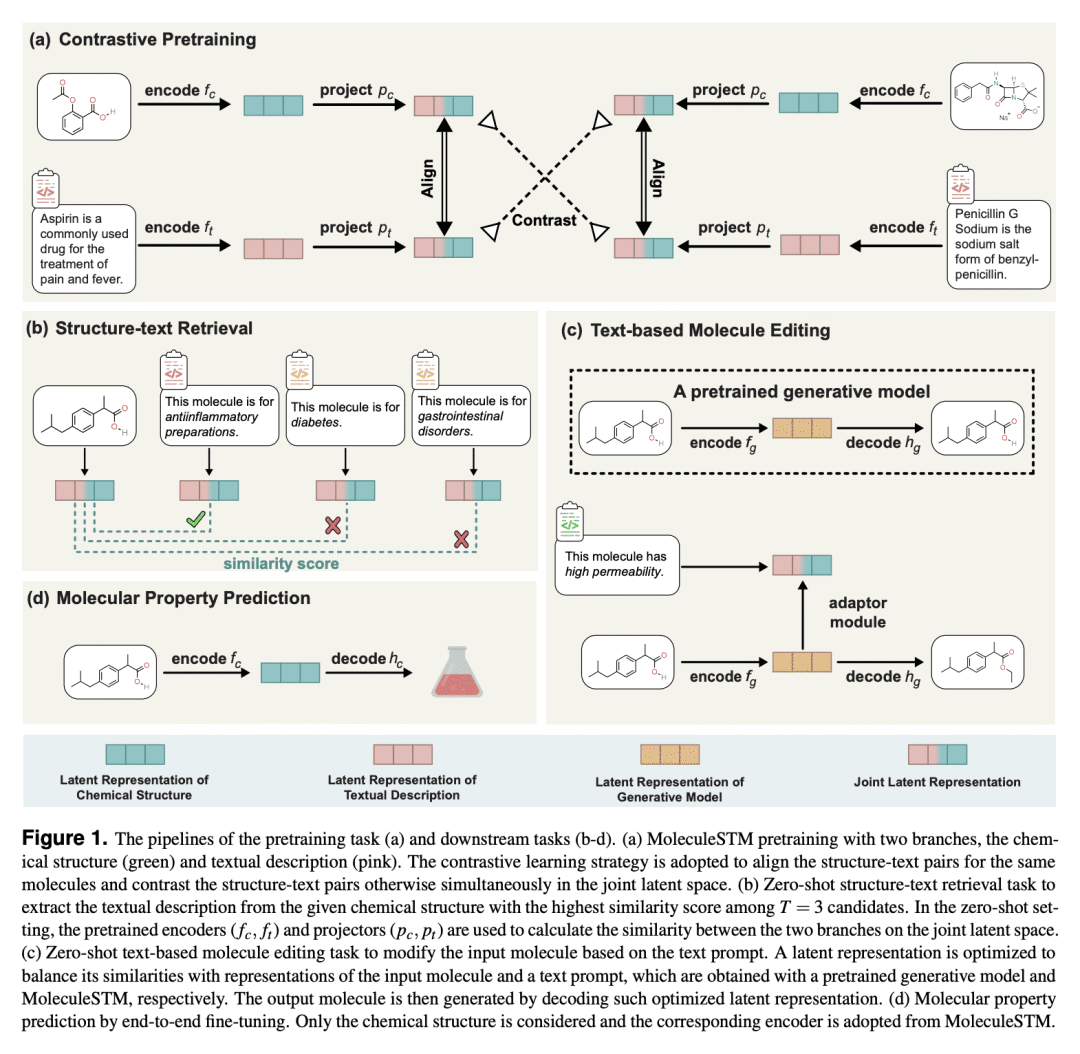
提出一种多模态分子结构-文本模型MoleculeSTM,通过对比学习策略来共同学习分子的化学结构和文本描述; -
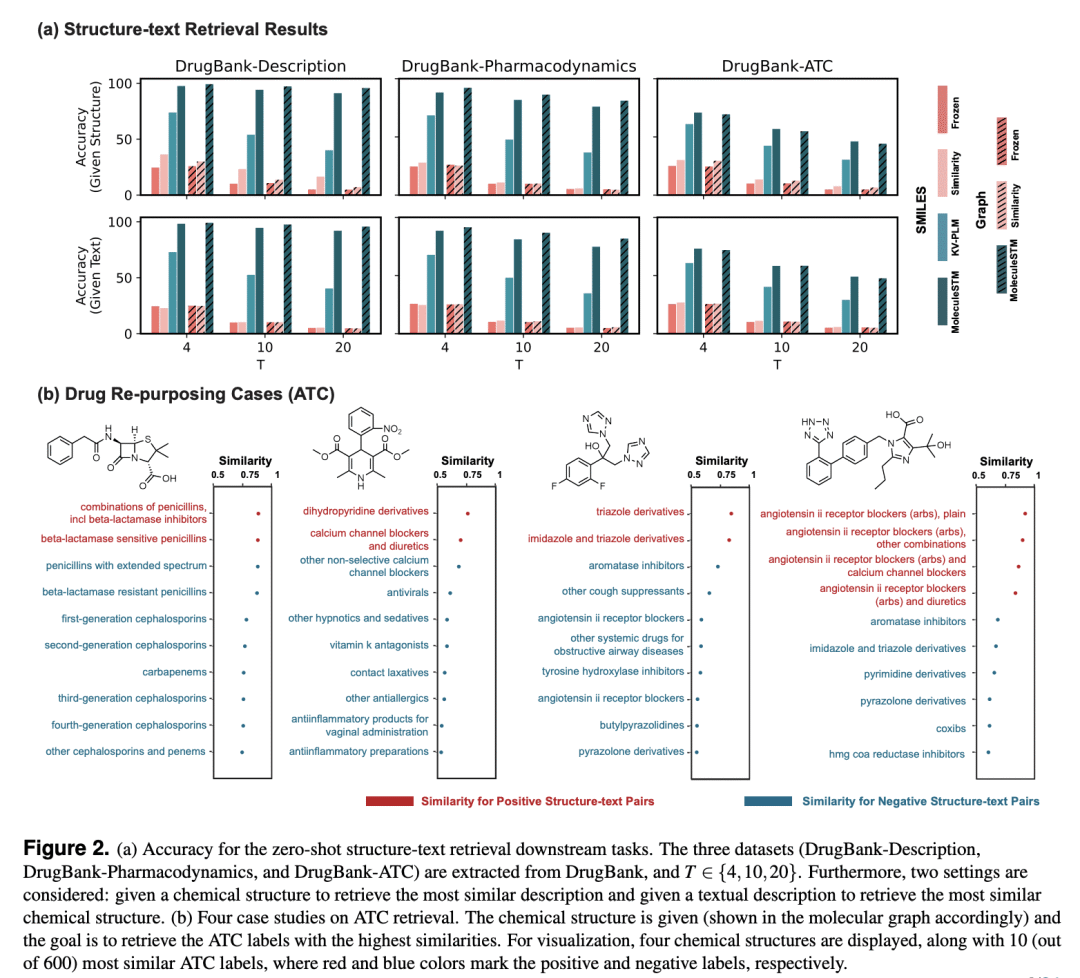
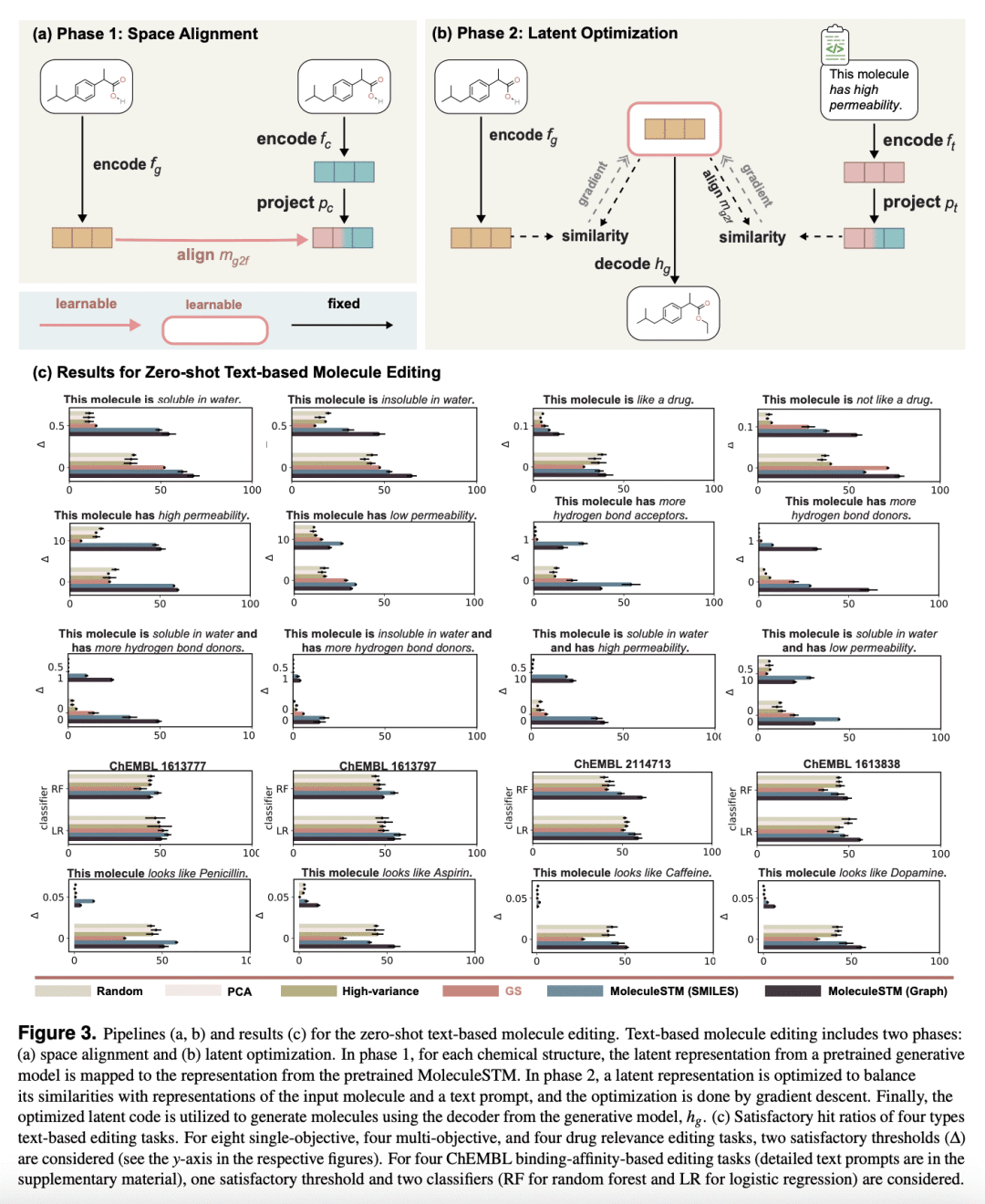
MoleculeSTM具有开放词汇和自然语言合成性两个主要特性,在各种基准测试中获得最先进的新生物化学概念泛化能力。
摘要: 人工智能越来越多地用来进行药物发现。然而,现有工作用机器学习来主要利用分子的化学结构,但忽视了化学中可用的大量文本知识。结合文本知识使得能够实现新的药物设计目标,适应基于文本的指令,并预测复杂的生物活动。本文通过对比学习策略联合学习分子的化学结构和文本描述,提出一种多模态分子结构-文本模型MoleCuleSTM。为训练MoleculeSTM,构建了迄今为止最大的多模态数据集PubChemSTM,包括超过280K的化学结构-文本对。为证明MoleculeSTM的有效性和实用性,根据文本指令设计了两个具有挑战性的零样本任务,包括结构文本检索和分子编辑。MoleculeSTM具有两个主要属性:开放词汇和通过自然语言的合成性。在实验中,MolecileSTM获得了跨越各种基准的新生化概念的最新泛化能力。
There is increasing adoption of artificial intelligence in drug discovery. However, existing works use machine learning to mainly utilize the chemical structures of molecules yet ignore the vast textual knowledge available in chemistry. Incorporating textual knowledge enables us to realize new drug design objectives, adapt to text-based instructions, and predict complex biological activities. We present a multi-modal molecule structure-text model, MoleculeSTM, by jointly learning molecule's chemical structures and textual descriptions via a contrastive learning strategy. To train MoleculeSTM, we construct the largest multi-modal dataset to date, namely PubChemSTM, with over 280K chemical structure-text pairs. To demonstrate the effectiveness and utility of MoleculeSTM, we design two challenging zero-shot tasks based on text instructions, including structure-text retrieval and molecule editing. MoleculeSTM possesses two main properties: open vocabulary and compositionality via natural language. In experiments, MoleculeSTM obtains the state-of-the-art generalization ability to novel biochemical concepts across various benchmarks.
论文链接:https://arxiv.org/abs/2212.10789
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢