
来自爱可可前沿推介
Dream3D: Zero-Shot Text-to-3D Synthesis Using 3D Shape Prior and Text-to-Image Diffusion Models
J Xu, X Wang, W Cheng, Y Cao, Y Shan, X Qie, S Gao
[ARC Lab & Tencent PCG & ShanghaiTech University]
Dream3D: 基于3D形状先验和文本到图像扩散模型的零样本文本到3D合成
要点:
-
将3D形状先验明确引入CLIP引导3D优化方法; -
提出一种简单而有效的方法,用强大的文本到图像扩散模型将文本和图像模态直接桥接起来; -
通过共同优化可学习文本提示和文本到图像扩散模型微调,实现渲染风格图像。 -
生成比现有技术更具想象力的3D内容,具有更好的视觉质量和形状精度。
摘要:
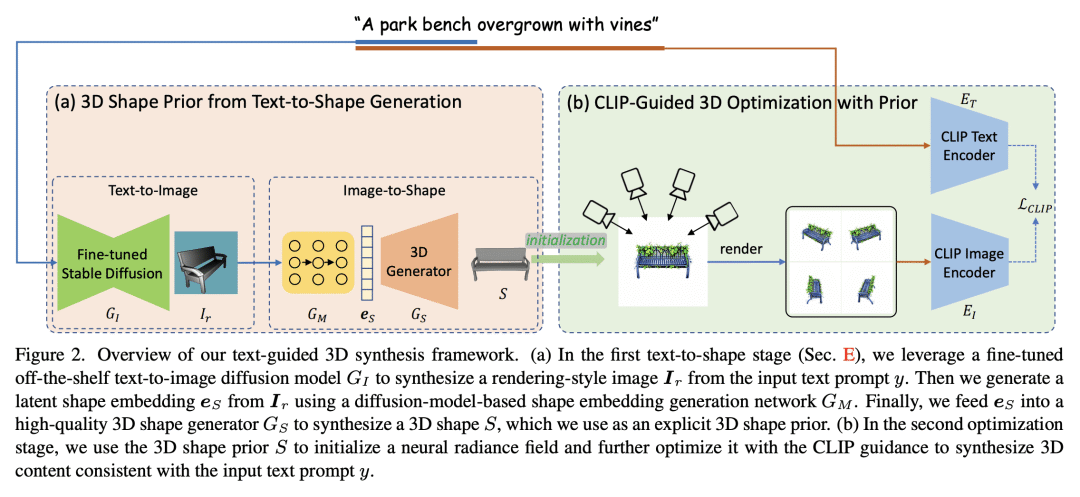
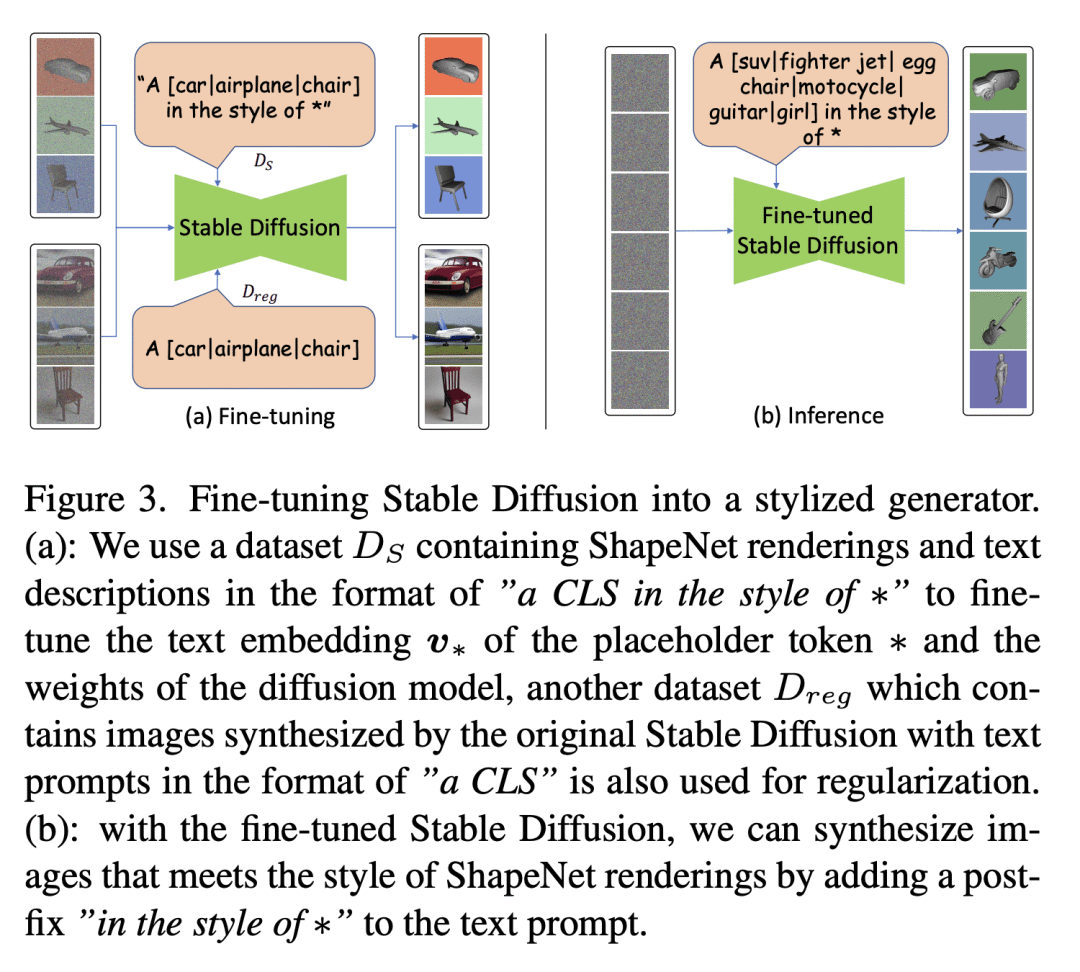
最近的CLIP引导3D优化方法,例如DreamFields和PureCLIPNeRF,在零样本文本引导3D合成中取得了巨大成功。然而,由于在没有任何先验情况下进行从头训练和随机初始化,这些方法通常无法生成符合相应文本的准确和忠实的3D结构。本文首次尝试在CLIP引导3D优化方法中引入明确的3D形状先验。首先从文本到形状阶段根据3D图形先验由输入文本生成高质量3D形状。将其用作神经辐射场的初始化,然后用完整的提示对其进行优化。对于文本到形状的生成,提出了一种简单而有效的方法,将文本和图像模态通过强大的文本到图像扩散模型直接联系起来。为了缩小文本到图像模型合成的图像与用于训练图像到形状生成器的形状渲染之间的样式域间隙,本文进一步建议联合优化可学习文本提示与文本到图像扩散模型微调,以生成渲染风格的图像。所提出方法Dream3D,能产生富有想象力的3D内容,具有比最先进的方法更好的视觉质量和形状准确性。
论文地址:https://arxiv.org/abs/2212.14704
Recent CLIP-guided 3D optimization methods, e.g., DreamFields and PureCLIPNeRF achieve great success in zero-shot text-guided 3D synthesis. However, due to the scratch training and random initialization without any prior knowledge, these methods usually fail to generate accurate and faithful 3D structures that conform to the corresponding text. In this paper, we make the first attempt to introduce the explicit 3D shape prior to CLIP-guided 3D optimization methods. Specifically, we first generate a high-quality 3D shape from input texts in the text-to-shape stage as the 3D shape prior. We then utilize it as the initialization of a neural radiance field and then optimize it with the full prompt. For the text-to-shape generation, we present a simple yet effective approach that directly bridges the text and image modalities with a powerful text-to-image diffusion model. To narrow the style domain gap between images synthesized by the text-to-image model and shape renderings used to train the image-to-shape generator, we further propose to jointly optimize a learnable text prompt and fine-tune the text-to-image diffusion model for rendering-style image generation. Our method, namely, Dream3D, is capable of generating imaginative 3D content with better visual quality and shape accuracy than state-of-the-art methods.


内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢