

来自爱可可前沿推介
[CL] Hungry Hungry Hippos: Towards Language Modeling with State Space Models
T Dao, D Y. Fu, K K. Saab, A W. Thomas, A Rudra, C Ré
[Stanford University]
基于状态空间模型的语言建模研究
要点:
-
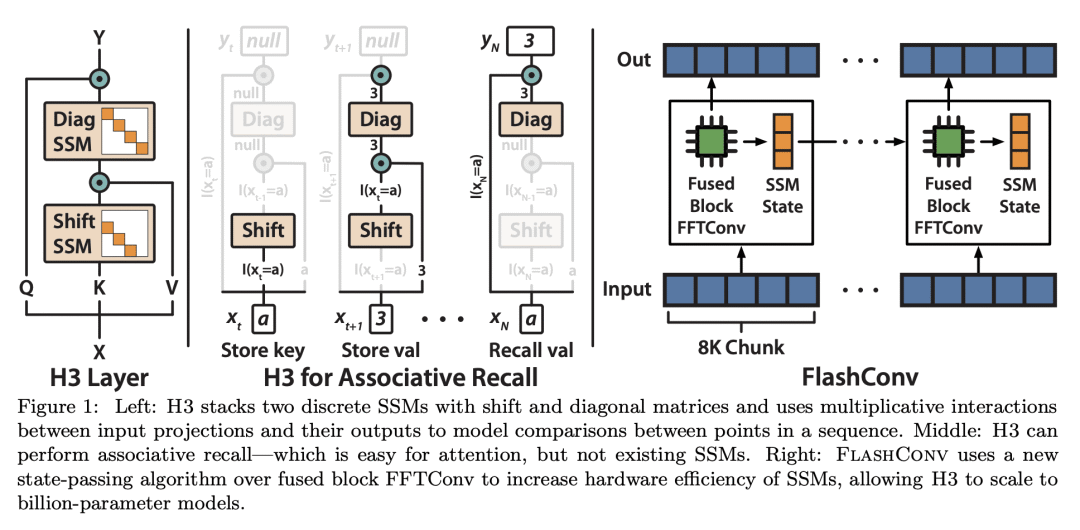
设计新的SSM层H3以匹配合成语言上的注意力,在OpenWebText上优于变形金刚;
-
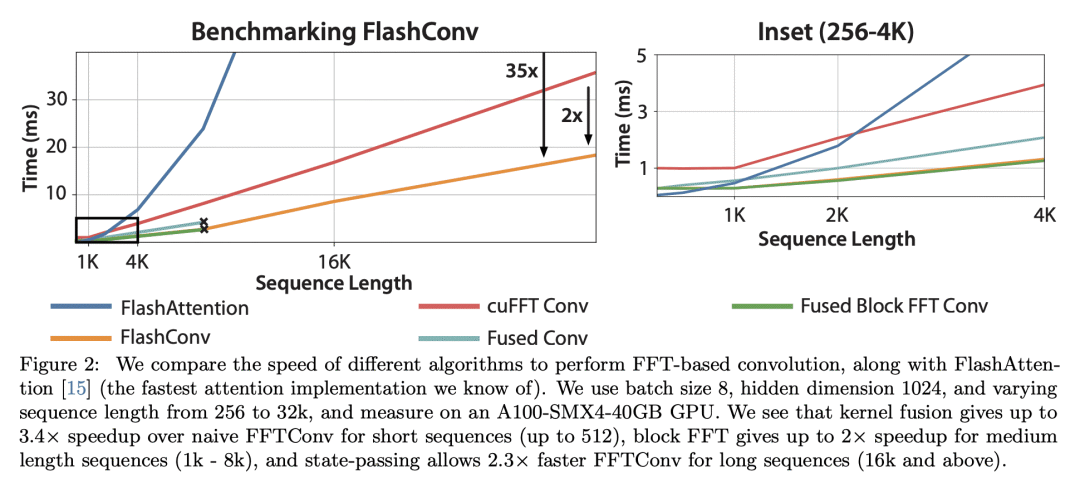
引入FlashConv以提高现代硬件SSM训练的效率;
-
在SuperGLUE基准测试的大多数任务上,扩展高达1.3B参数的混合H3注意力语言模型,并在零样本和少样本学习中优于Transformer。
摘要:
状态空间模型(SSM)在某些模态展示了最先进的序列建模性能,但在语言建模中表现不佳。尽管在序列长度上几乎是线性的,而不是二次缩放的,但由于硬件利用率差,SSM仍然比Transformer慢。本文在理解SSM与语言建模中的注意力之间的表达性差距,以及在减少SSM与注意力之间的硬件障碍方面取得了进展。首先,本文用合成语言建模任务来了解SSM与注意力之间的差距。发现现有的SSM在两种特性上存在不足:在序列中召回早前的token和比较整个序列中的token。为了了解对语言建模的影响,本文提出一种新的SSM层H3,该层是专门为这些能力设计的。为了提高现代硬件SSM训练的效率,本文提出FlashConv,用融合块FFT算法来提高高达8K序列的效率,并提出一种新的状态传递算法,利用SSM的重复特性扩展到更长的序列。FlashConv在long-range arena基准测试上产生2倍的加速,并允许混合语言模型比Transformer 1.6倍快地生成文本。
State space models (SSMs) have demonstrated state-of-the-art sequence modeling performance in some modalities, but underperform attention in language modeling. Moreover, despite scaling nearly linearly in sequence length instead of quadratically, SSMs are still slower than Transformers due to poor hardware utilization. In this paper, we make progress on understanding the expressivity gap between SSMs and attention in language modeling, and on reducing the hardware barrier between SSMs and attention. First, we use synthetic language modeling tasks to understand the gap between SSMs and attention. We find that existing SSMs struggle with two capabilities: recalling earlier tokens in the sequence and comparing tokens across the sequence. To understand the impact on language modeling, we propose a new SSM layer, H3, that is explicitly designed for these abilities. H3 matches attention on the synthetic languages and comes within 0.4 PPL of Transformers on OpenWebText. Furthermore, a hybrid 125M-parameter H3-attention model that retains two attention layers surprisingly outperforms Transformers on OpenWebText by 1.0 PPL. Next, to improve the efficiency of training SSMs on modern hardware, we propose FlashConv. FlashConv uses a fused block FFT algorithm to improve efficiency on sequences up to 8K, and introduces a novel state passing algorithm that exploits the recurrent properties of SSMs to scale to longer sequences. FlashConv yields 2× speedup on the long-range arena benchmark and allows hybrid language models to generate text 1.6× faster than Transformers. Using FlashConv, we scale hybrid H3-attention language models up to 1.3B parameters on the Pile and find promising initial results, achieving lower perplexity than Transformers and outperforming Transformers in zero- and few-shot learning on a majority of tasks in the SuperGLUE benchmark.
论文地址:https://arxiv.org/abs/2212.14052

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢