
来自今天的爱可可AI前沿推介
[CL] GPT Takes the Bar Exam
M B II, D M Katz
[Chicago Kent College of Law]
用GPT参加律师考试
要点:
-
记录了GPT-3.5在律师考试MBE部分的实验评估。 -
GPT-3.5显著优于随机猜测的基线水平,达到了证据和侵权的及格水平。 -
GPT-3.5可能选择的排序与正确率的强相关性超出了随机机会的正确性。
摘要:
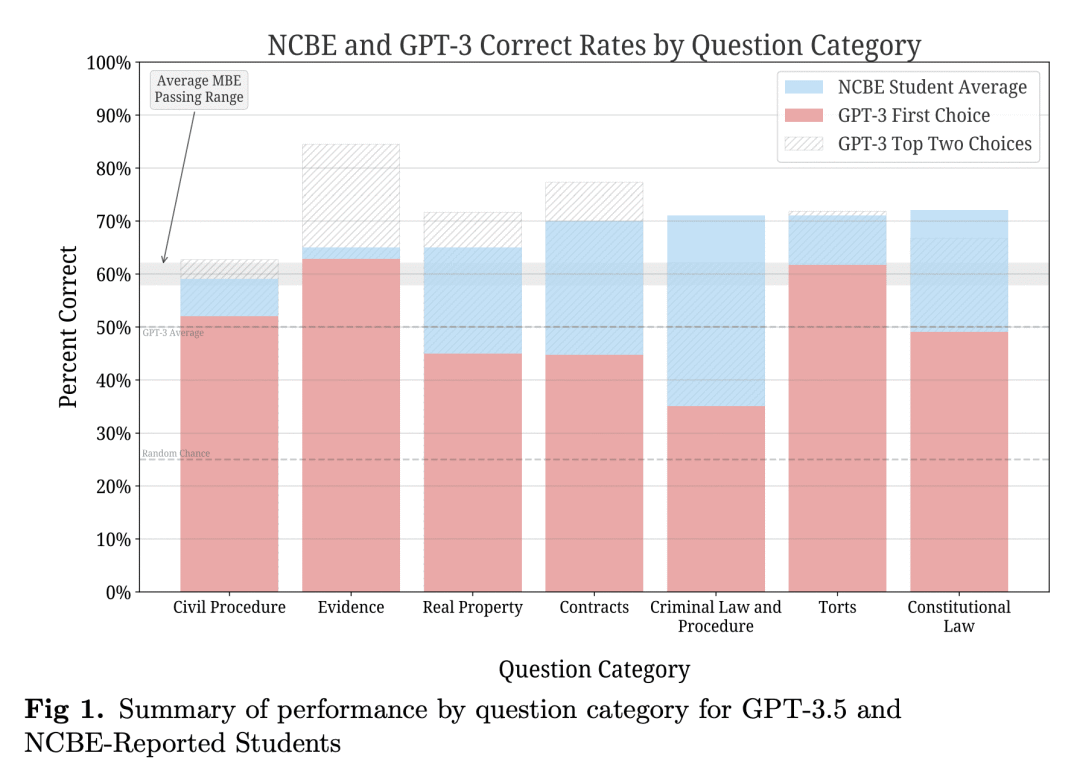
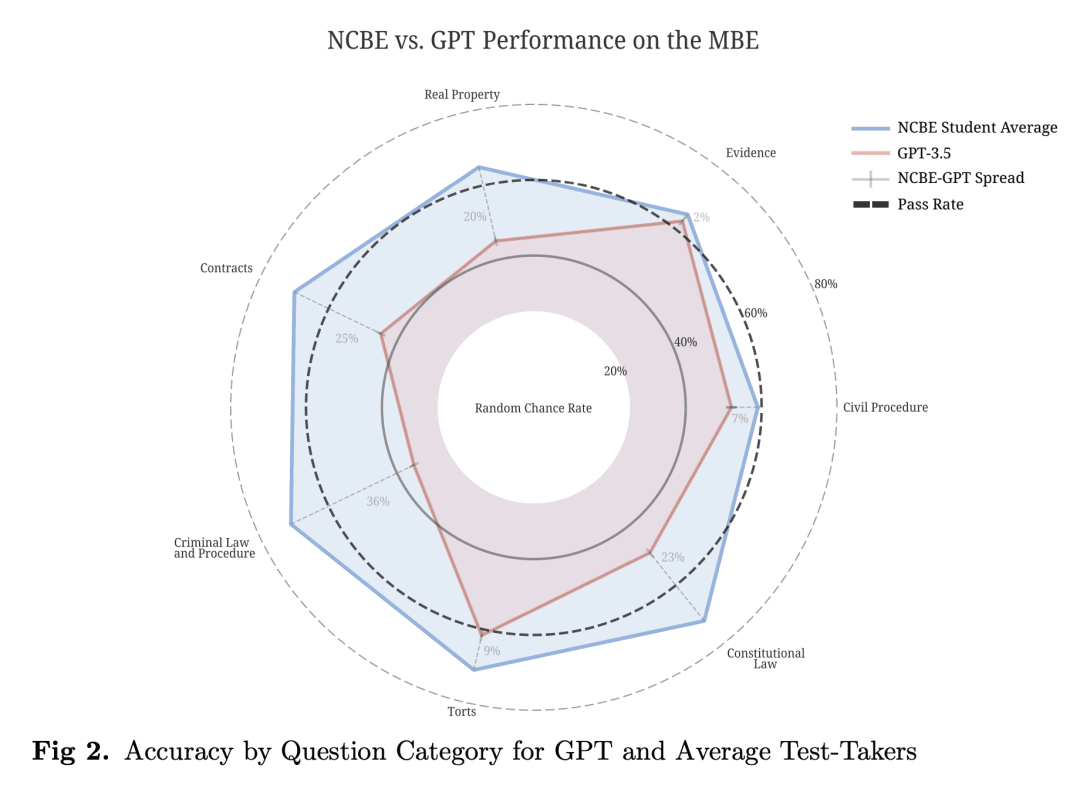
在美国,几乎所有司法管辖区都需要专业执照考试,通常被称为“律师考试(Bar Exam)”,作为法律实践的前提。为参加考试,大多数司法管辖区要求申请人完成至少七年的高等教育,包括在认定的法学院学习三年。此外,大多数考生还接受数周到数月的特定考试准备。尽管投入了大量时间和金钱,但大约五分之一的考生仍然低于第一次尝试通过考试所需的分数。面对一项需要如此深入知识的复杂任务,应该对"AI"的最新水平抱有什么期待呢?本文记录了对OpenAI的“text-davinci-003”模型(通常称为GPT-3.5)在考试的多州多项选择(MBE)部分性能的实验评估。虽然在训练数据规模上微调GPT-3.5的零样本性能没有好处,但确实发现超参优化和提示工程对GPT-3.5的零样本性能产生了积极影响。为了获得最佳提示和参数,GPT-3.5在完整的NCBE MBE实践考试中实现了50.3%的标题正确率,大大超过25%的基线猜测率,达到了证据和侵权的及格水平。GPT-3.5的响应排序也与正确性高度相关;其前二和前三的选择分别在71%和88%的时间是正确的,表明其非常强劲的非蕴含性能。b认为这些结果强烈表明,LLM将在不久的将来通过律师考试的MBE部分。 在美国,几乎所有司法管辖区都需要专业执照考试,通常被称为“律师考试(Bar Exam)”,作为法律实践的前提。为参加考试,大多数司法管辖区要求申请人完成至少七年的高等教育,包括在认定的法学院学习三年。此外,大多数考生还接受数周到数月的特定考试准备。尽管投入了大量时间和金钱,但大约五分之一的考生仍然低于第一次尝试通过考试所需的分数。面对一项需要如此深入知识的复杂任务,应该对"AI"的最新水平抱有什么期待呢?本文记录了对OpenAI的“text-davinci-003”模型(通常称为GPT-3.5)在考试的多州多项选择(MBE)部分性能的实验评估。虽然在训练数据规模上微调GPT-3.5的零样本性能没有好处,但确实发现超参优化和提示工程对GPT-3.5的零样本性能产生了积极影响。为了获得最佳提示和参数,GPT-3.5在完整的NCBE MBE实践考试中实现了50.3%的标题正确率,大大超过25%的基线猜测率,达到了证据和侵权的及格水平。GPT-3.5的响应排序也与正确性高度相关;其前二和前三的选择分别在71%和88%的时间是正确的,表明其非常强劲的非蕴含性能。本文认为这些结果强烈表明,LLM将在不久的将来通过律师考试的MBE部分。
Nearly all jurisdictions in the United States require a professional license exam, commonly referred to as "the Bar Exam," as a precondition for law practice. To even sit for the exam, most jurisdictions require that an applicant completes at least seven years of post-secondary education, including three years at an accredited law school. In addition, most test-takers also undergo weeks to months of further, exam-specific preparation. Despite this significant investment of time and capital, approximately one in five test-takers still score under the rate required to pass the exam on their first try. In the face of a complex task that requires such depth of knowledge, what, then, should we expect of the state of the art in "AI?" In this research, we document our experimental evaluation of the performance of OpenAI's
text-davinci-003model, often-referred to as GPT-3.5, on the multistate multiple choice (MBE) section of the exam. While we find no benefit in fine-tuning over GPT-3.5's zero-shot performance at the scale of our training data, we do find that hyperparameter optimization and prompt engineering positively impacted GPT-3.5's zero-shot performance. For best prompt and parameters, GPT-3.5 achieves a headline correct rate of 50.3% on a complete NCBE MBE practice exam, significantly in excess of the 25% baseline guessing rate, and performs at a passing rate for both Evidence and Torts. GPT-3.5's ranking of responses is also highly-correlated with correctness; its top two and top three choices are correct 71% and 88% of the time, respectively, indicating very strong non-entailment performance. While our ability to interpret these results is limited by nascent scientific understanding of LLMs and the proprietary nature of GPT, we believe that these results strongly suggest that an LLM will pass the MBE component of the Bar Exam in the near future.
论文链接:https://arxiv.org/abs/2212.14402

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢