
来自今天的爱可可AI前沿推介
[AS] ResGrad: Residual Denoising Diffusion Probabilistic Models for Text to Speech
Z Chen, Y Wu, Y Leng, J Chen, H Liu...
[Microsoft & Imperial College London & Renmin University of China & ...]
ResGrad: 文本到语音残差去噪扩散概率模型
要点:
-
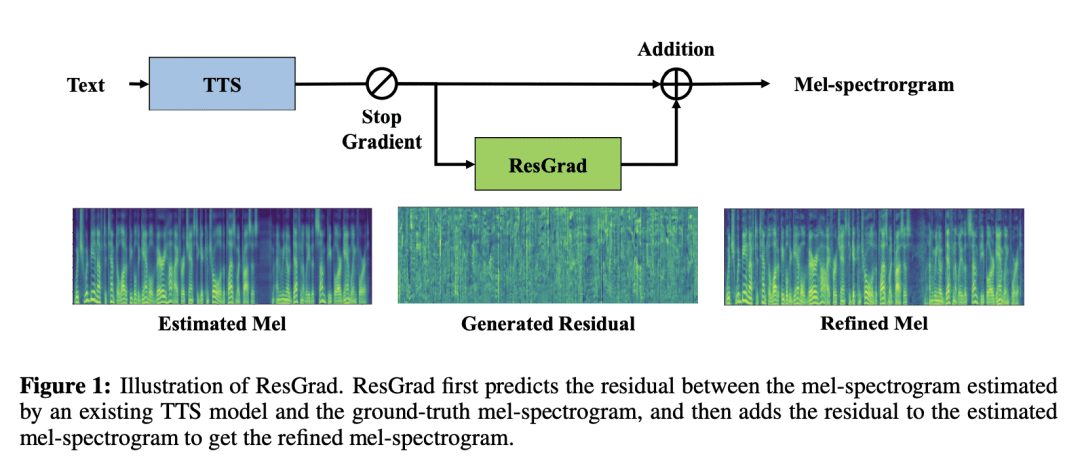
提出ResGrad,一种轻量扩散模型,可通过预测现有TTS模型输出谱图与相应真实语音间残差来学习改善输出谱图,通过引入残差,降低了任务的复杂度,更轻量,具有更小的实时因子; -
ResGrad以即插即用方式应用于现有TTS模型的推理过程,无需重新训练模型; -
对LJ-Speech、LibriTTS和VCTK数据集的实验表明,与其他加速DDPM的基线相比,ResGrad可以在相同的RTF下获得更高的样本质量,在生成相似语音质量的情况下,比基线快10倍以上。
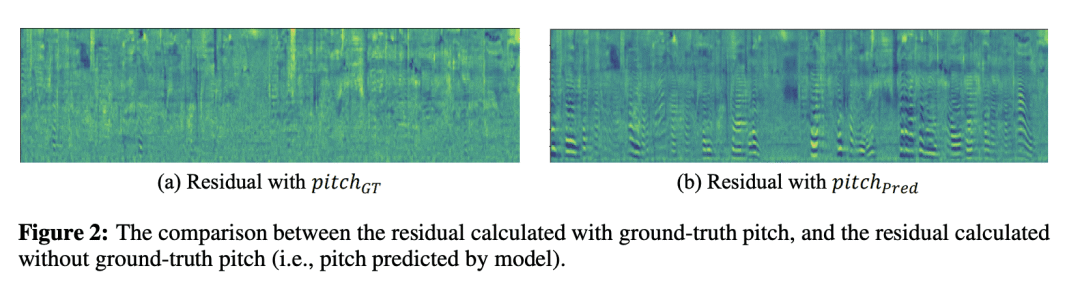
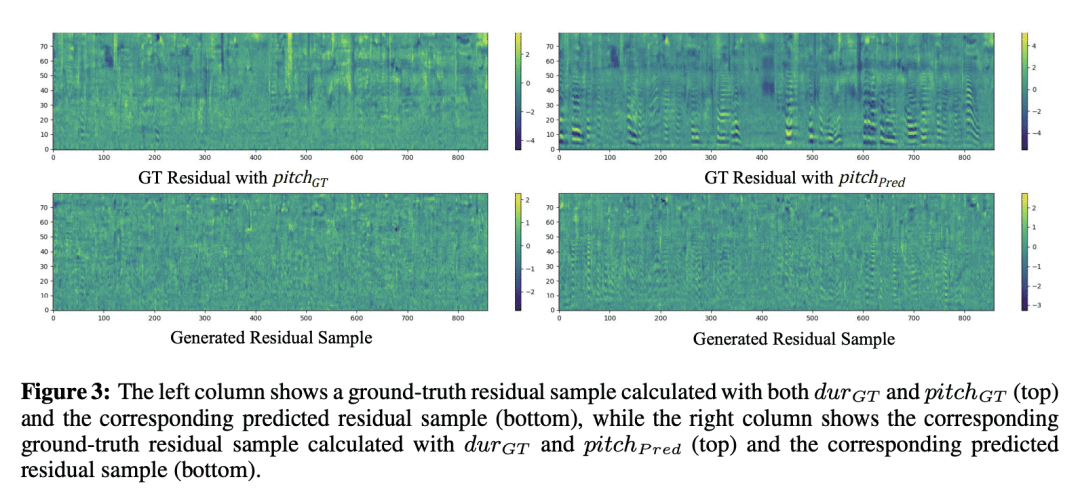
摘要: 去噪扩散概率模型(DDPM)正在文本到语音(TTS)合成中得到越来越广泛的应用,因为其具有生成高保真样本的强大能力。然而,由于在高维数据空间中的迭代细化过程导致推理速度缓慢,限制了其在实时系统中的应用。之前的工作探索了通过最大限度减少推理步骤的数量来加快速度,但以牺牲样本质量为代价。本文为了提高基于DDPM的TTS模型的推理速度,同时实现高样本质量,提出了ResGrad,一种轻量扩散模型,通过预测模型输出和相应的真实语音间的残差,学习细化现有TTS模型(如FastSpeech 2)的输出谱图。ResGrad有如下优点:1) 与其他需要从头开始合成语音的DDPM加速方法相比,ResGrad通过将生成目标从真实mel谱图变为残差来降低任务的复杂性,从而形成更轻量的模型,获得了更小的实时因子。2) ResGrad以即插即用的方式用于现有TTS模型的推理过程,无需重新训练该模型。在单说话人数据集LJSpeech和两个具有多说话人(LibriTTS)和高采样率(VCTK)的更具挑战性的数据集上验证ResGrad。结果表明,与其他DDPM的加速方法相比:1) ResGrad以实时因子测量的相同推理速度实现更好的样本质量;2) 达到相似的语音质量,ResGrad的语音合成速度比基线方法快10倍以上。
Denoising Diffusion Probabilistic Models (DDPMs) are emerging in text-to-speech (TTS) synthesis because of their strong capability of generating high-fidelity samples. However, their iterative refinement process in high-dimensional data space results in slow inference speed, which restricts their application in real-time systems. Previous works have explored speeding up by minimizing the number of inference steps but at the cost of sample quality. In this work, to improve the inference speed for DDPM-based TTS model while achieving high sample quality, we propose ResGrad, a lightweight diffusion model which learns to refine the output spectrogram of an existing TTS model (e.g., FastSpeech 2) by predicting the residual between the model output and the corresponding ground-truth speech. ResGrad has several advantages: 1) Compare with other acceleration methods for DDPM which need to synthesize speech from scratch, ResGrad reduces the complexity of task by changing the generation target from ground-truth mel-spectrogram to the residual, resulting into a more lightweight model and thus a smaller real-time factor. 2) ResGrad is employed in the inference process of the existing TTS model in a plug-and-play way, without re-training this model. We verify ResGrad on the single-speaker dataset LJSpeech and two more challenging datasets with multiple speakers (LibriTTS) and high sampling rate (VCTK). Experimental results show that in comparison with other speed-up methods of DDPMs: 1) ResGrad achieves better sample quality with the same inference speed measured by real-time factor; 2) with similar speech quality, ResGrad synthesizes speech faster than baseline methods by more than 10 times. Audio samples are available at this https URL.
论文链接:https://arxiv.org/abs/2212.14518
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢