
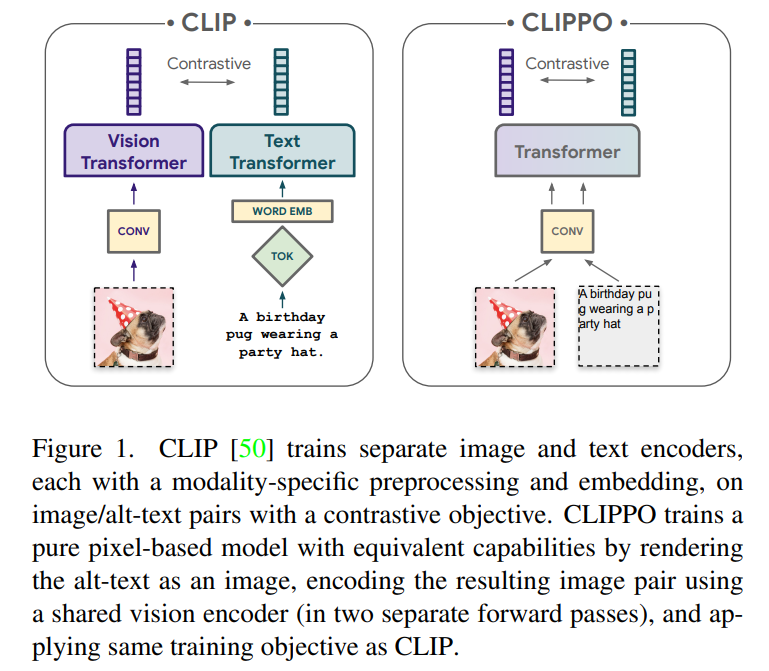
近年来,基于 Transformer 的大规模多模态训练促成了不同领域最新技术的改进,包括视觉、语言和音频。特别是在计算机视觉和图像语言理解方面,单个预训练大模型可以优于特定任务的专家模型。
然而,大型多模态模型通常使用模态或特定于数据集的编码器和解码器,并相应地导致涉及的协议。例如,此类模型通常涉及在各自的数据集上对模型的不同部分进行不同阶段的训练,并进行特定于数据集的预处理,或以特定于任务的方式迁移不同部分。这种模式和特定于任务的组件可能会导致额外的工程复杂性,并在引入新的预训练损失或下游任务时面临挑战。
因此,开发一个可以处理任何模态或模态组合的单一端到端模型,将是多模态学习的重要一步。本文中,来自谷歌研究院(谷歌大脑团队)、苏黎世的研究者将主要关注图像和文本。
论文地址:https://arxiv.org/pdf/2212.08045.pdf
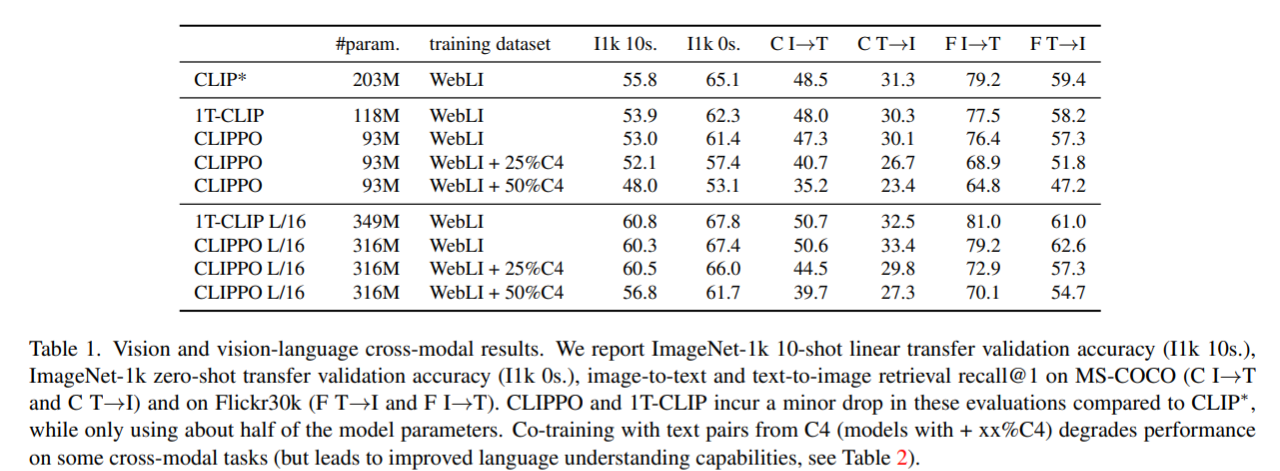
图像分类与检索。表 1 显示了 CLIPPO 的性能,可以看到,与 CLIP∗ 相比,CLIPPO 和 1T-CLIP 产生了 2-3 个百分点的绝对下降。
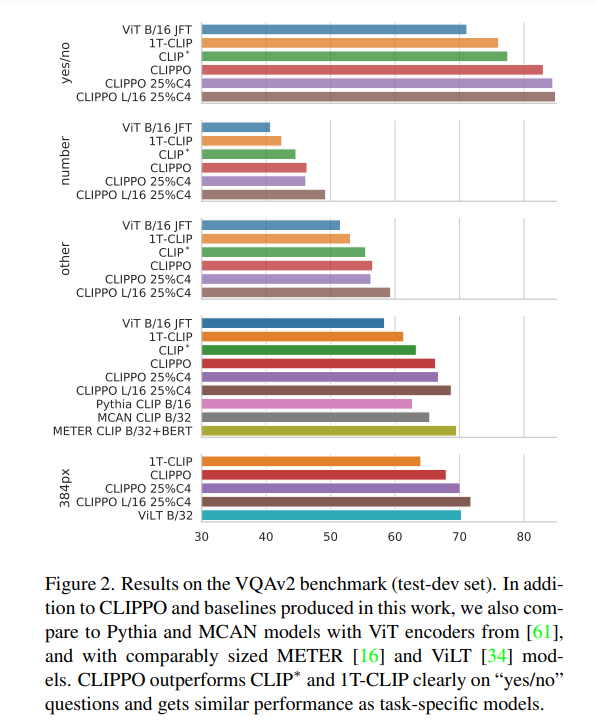
VQA。图 2 中报告了模型和基线的 VQAv2 评分。可以看到,CLIPPO 优于 CLIP∗ 、1T-CLIP,以及 ViT-B/16,获得了 66.3 的分数。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢