
12月27日,MetaAI 负责视觉和强化学习领域的A
截止27日晚间,这篇推文的阅读量已经达到73.9k。
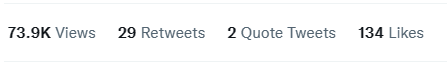
他表示,仅给出5个演示,MoDem就能在100K交互步骤中解决具有稀疏奖励和高维动作空间的具有挑战性的视觉运动控制任务,大大优于现有的最先进方法。
有多优秀呢?
他们发现MoDem在完成稀疏奖励任务方面的成功率比低数据机制中的先前方法高出150%-250%。

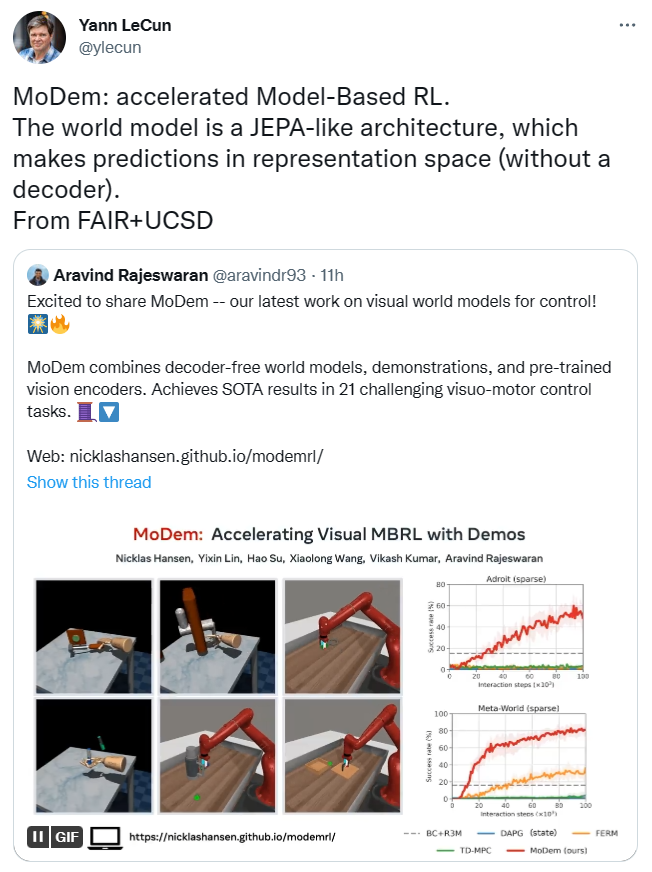
Lecun也转发了这一研究,表示MoDem的模型架构类似于JEPA,可在表征空间做出预测且无需解码器。
链接小编就放在下面啦,有兴趣的小伙伴可以看看~

论文链接:https://arxiv.org/abs/2212.05698
Github链接:https://github.com/facebookresearch/modem
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢