
随着语言大模型(LLM)能力的不断提高,语境学习( in-context learning,ICL)已经成为自然语言处理(NLP)的一种新范式,其中LLM仅根据由少量训练样本增强的上下文进行预测。探索ICL来评估和推断LLM的能力已经成为一个新的趋势。文中对ICL的研究进展、面临的挑战以及未来的研究方向进行了综述和总结。
论文地址:https://arxiv.org/abs/2301.00234
github论文列表:https://github.com/dqxiu/ICL_PaperList
本文首先给出了ICL的形式化定义,并阐明了其与相关研究的相关性。然后,我们组织讨论了ICL的先进技术,包括训练策略、激励策略等;最后,指出了ICL面临的挑战,并指出了进一步研究的方向。希望我们的工作能够促进更多关于揭示ICL工作原理和改进ICL的研究。
随着模型规模和语料库规模的扩大(Devlin et al., 2019; Radford et al., 2019; Brown et al., 2020; Chowdhery et al., 2022),大型语言模型展示了从由上下文中的几个示例组成的演示中学习的新能力(简称语境学习)。许多研究表明,LLMs可以使用ICL执行一系列复杂的任务,如解决数学推理问题(Wei et al., 2022c)。这些强大的能力已经被广泛验证为大型语言模型的新兴能力(Wei等人,2022b)。

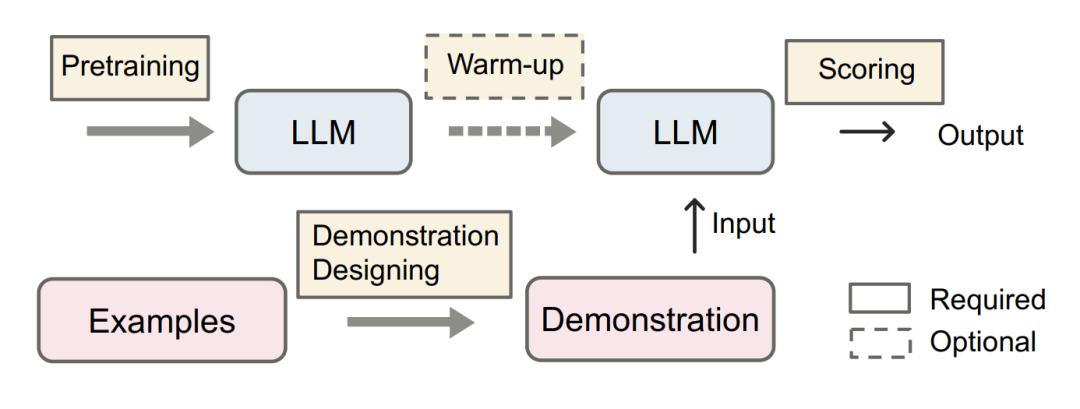
语境学习的核心思想是类比学习。图1给出了一个示例,描述了语言模型如何使用ICL进行决策。首先,ICL需要一些示例来形成演示上下文。这些示例通常使用自然语言模板编写。然后,ICL将一个查询问题和一个演示上下文连接在一起形成一个提示,然后将其输入到语言模型中进行预测。与监督学习需要一个使用后向梯度更新模型参数的训练阶段不同,ICL不需要参数更新,而是直接对预训练语言模型进行预测。该模型被期望学习隐藏在演示中的模式,并相应地做出正确的预测。
ICL作为一种新的范式,具有许多吸引人的优势。首先,由于演示是用自然语言格式编写的,它提供了一个可解释的接口来与大型语言模型通信(Brown et al., 2020)。这种范式通过更改演示和模板使将人类知识纳入语言模型变得容易得多(Liu等人,2022;陆等人,2022;吴等人,2022;Wei等,2022c)。第二,上下文学习类似于人类的类比决策过程。第三,与有监督学习相比,ICL是一种无训练学习框架。这不仅可以大大降低使模型适应新任务的计算成本,还可以使语言模型即服务(Sun等人,2022)成为可能,并且可以很容易地应用于大规模的现实世界任务。
尽管前景看好,但ICL中还有一些有趣的问题和有趣的性质需要进一步研究。虽然普通的GPT-3模型本身显示出有希望的ICL能力,但一些研究观察到,通过预训练期间的自适应,能力可以显著提高(Min et al., 2022b; Chen et al., 2022c)。此外,ICL的性能对特定的设置很敏感,包括提示模板、上下文示例的选择和示例顺序等(Zhao et al., 2021)。此外,尽管从直观上看是合理的,但ICL的工作机制仍然不明确,很少有研究提供初步解释(Dai et al., 2022; von Oswald et al., 2022)。
ICL的强大性能依赖于两个阶段:(1)训练阶段,训练LLM的ICL能力,(2)推理阶段,LLM根据特定任务的演示进行预测。在训练阶段,语言模型直接在语言建模目标上进行训练,如从左到右的生成。虽然这些模型并没有针对上下文学习进行特别优化,但ICL仍然具有令人惊讶的能力。现有的ICL研究基本上以训练有素的语言模型为骨干,因此本综述不会涵盖预训练语言模型的细节。在推理阶段,由于输入和输出标签都在可解释的自然语言模板中表示,因此有多个方向来提高ICL的性能。本文将给出详细的描述和比较,如选择合适的示例进行演示,针对不同的任务设计具体的评分方法等。
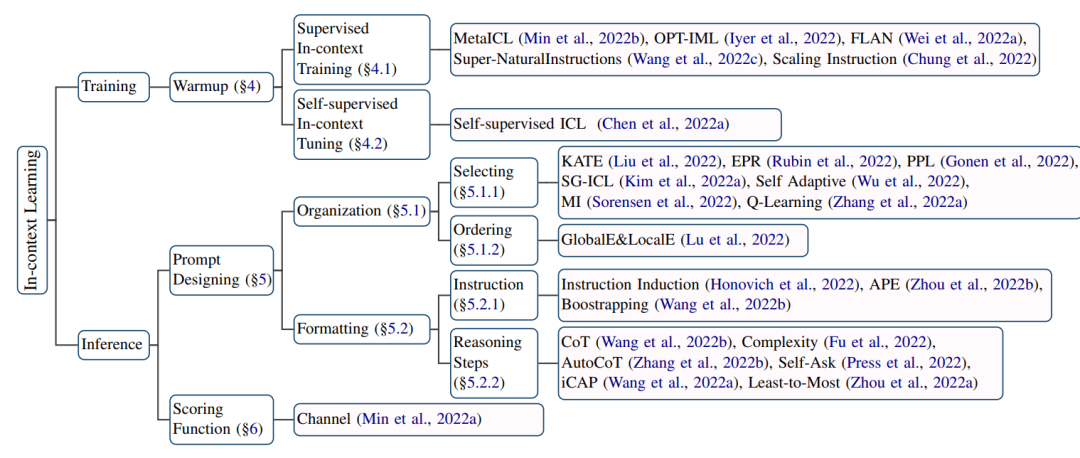
本文按照上述分类法(如图2所示)组织ICL目前的进展,给出了ICL的正式定义(§3),详细讨论了热身方法(§4)、演示设计策略(§5)和主要评分功能(§6)。§7对揭开ICL背后秘密的当前探索进行了深入讨论。进一步为ICL(§8)提供了有用的评估和资源,并介绍了ICL显示其有效性的潜在应用场景(§9)。最后,总结了挑战和潜在的方向(§10),希望这可以为该领域的研究人员铺平道路。

内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢