
本文来自今日爱可可前沿推介
Muse: Text-To-Image Generation via Masked Generative Transformers
H Chang, H Zhang, J Barber, A Maschinot, J Lezama, L Jiang, M Yang, K Murphy, W T. Freeman, M Rubinstein, Y Li, D Krishnan
[Google Research]
Muse: 基于掩码生成式Transformer的文本到图像生成
要点:
-
提出一种新的文本到图像生成模型,FID分数和CLIP分数达到最新水平; -
由于使用了离散图像Token量化和并行解码,该模型比之前模型更快; -
可提供零样本编辑功能,包括绘画、补全和无蒙版编辑; -
利用预训练的大型语言模型,实现了细粒度的语言理解,以及高保真的图像生成和视觉概念理解 。
摘要:
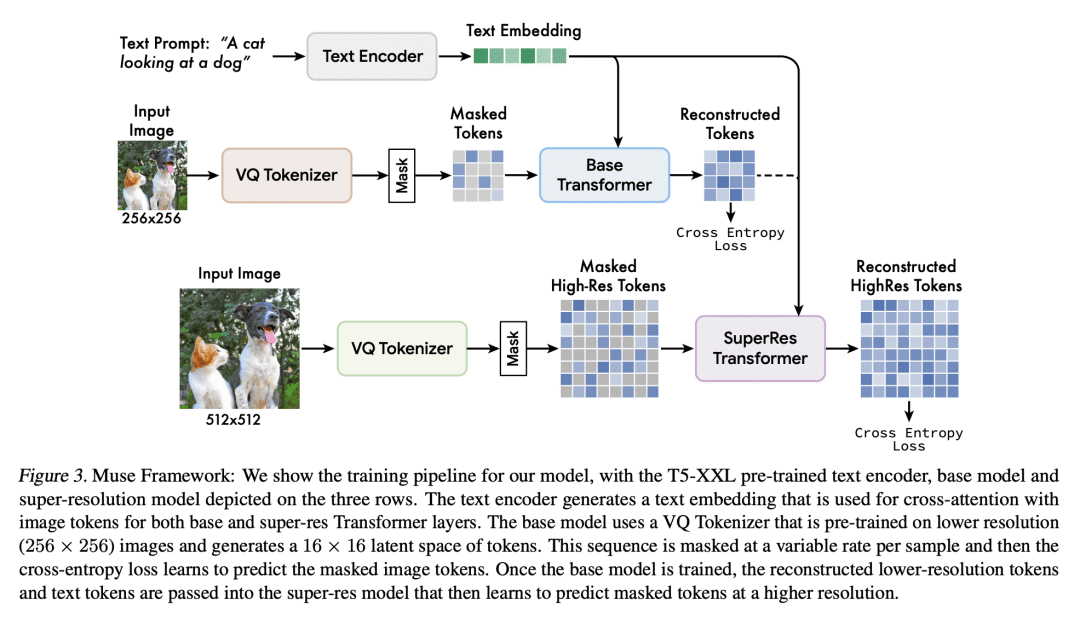
本文提出Muse,一个文本到图像的Transformer模型,实现了最先进的图像生成性能,同时比扩散模型和自回归模型效率高得多。Muse在离散Token空间接受掩码建模任务的训练:给定从预训练的大型语言模型(LLM)中提取的文本嵌入,Muse被训练来预测随机掩码的图像Token。与Imagen和DALL-E 2等像素空间扩散模型相比,由于使用离散token和需要更少采样迭代,Muse的效率要高得多;与Parti等自回归模型相比,由于使用并行解码,Muse的效率更高。使用预先训练的LLM可以实现细粒度的语言理解,转化为高保真图像生成,并理解视觉概念,如对象、其空间关系、姿态、基数等。所得到的900M参数模型在CC3M上实现了新的SOTA,FID分数为6.06。Muse 3B参数模型在零样本COCO评估下实现了7.88的FID,CLIP得分为0.32。Muse还直接支持了许多图像编辑应用程序,无需微调或逆转模型:绘画、补全和无蒙版编辑。
https://arxiv.org/abs/2301.00704
We present Muse, a text-to-image Transformer model that achieves state-of-the-art image generation performance while being significantly more efficient than diffusion or autoregressive models. Muse is trained on a masked modeling task in discrete token space: given the text embedding extracted from a pre-trained large language model (LLM), Muse is trained to predict randomly masked image tokens. Compared to pixel-space diffusion models, such as Imagen and DALL-E 2, Muse is significantly more efficient due to the use of discrete tokens and requiring fewer sampling iterations; compared to autoregressive models, such as Parti, Muse is more efficient due to the use of parallel decoding. The use of a pre-trained LLM enables fine-grained language understanding, translating to high-fidelity image generation and the understanding of visual concepts such as objects, their spatial relationships, pose, cardinality etc. Our 900M parameter model achieves a new SOTA on CC3M, with an FID score of 6.06. The Muse 3B parameter model achieves an FID of 7.88 on zero-shot COCO evaluation, along with a CLIP score of 0.32. Muse also directly enables a number of image editing applications without the need to fine-tune or invert the model: inpainting, outpainting, and mask-free editing. More results are available at this https URL


内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢