
来自今天的爱可可AI前沿推介
[LG] SparseGPT: Massive Language Models Can Be Accurately Pruned in One-Shot
E Frantar, D Alistarh
[IST Austria]
SparseGPT: 大规模语言模型可通过单样本精确修剪
要点:
-
提出SparseGPT, GPT族模型的单样本修剪方法; -
SparseGPT可以让GPT族模型稀疏50-60%,而精度损失最小; -
SparseGPT可用于最大的开源GPT族模型,无需重新训练; -
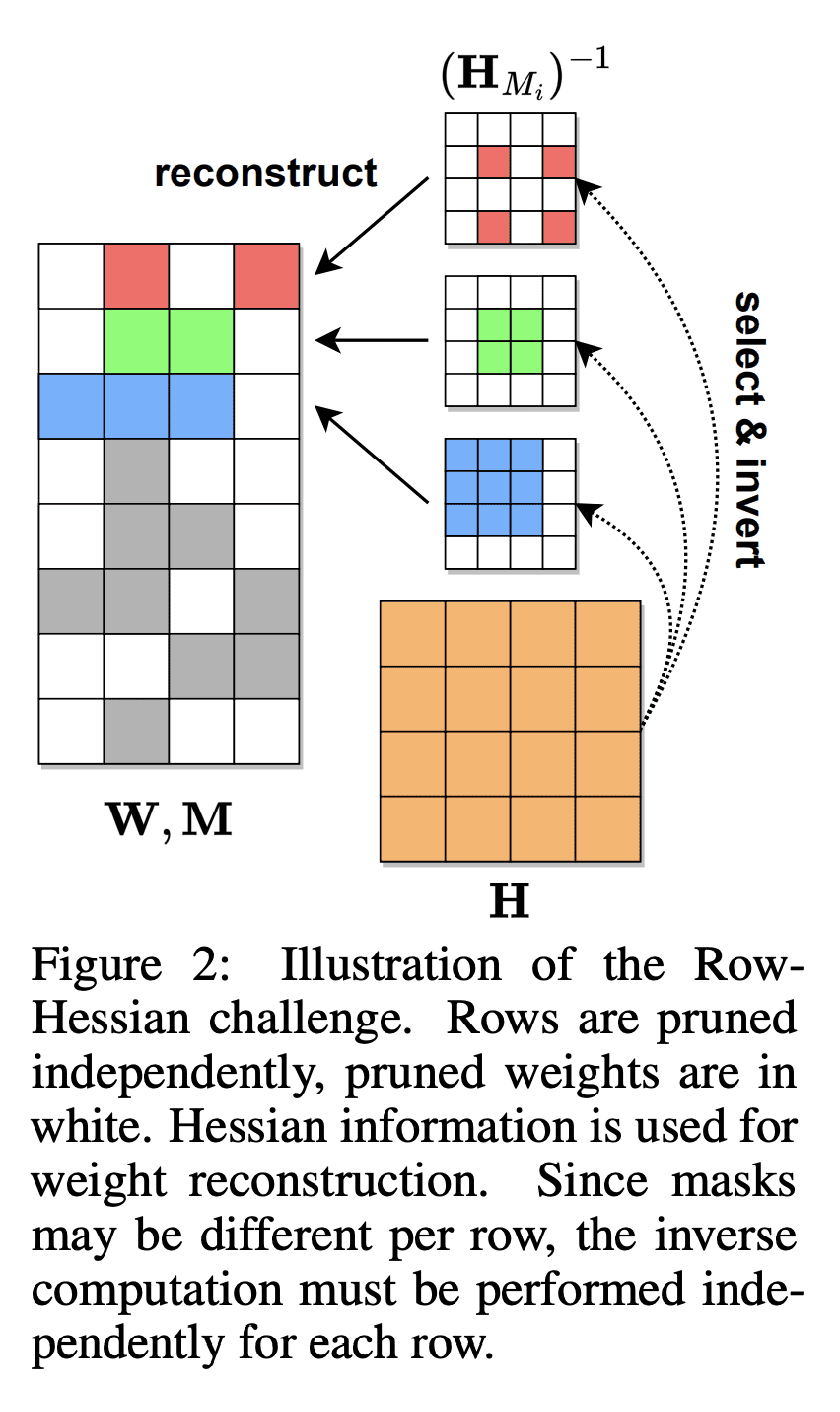
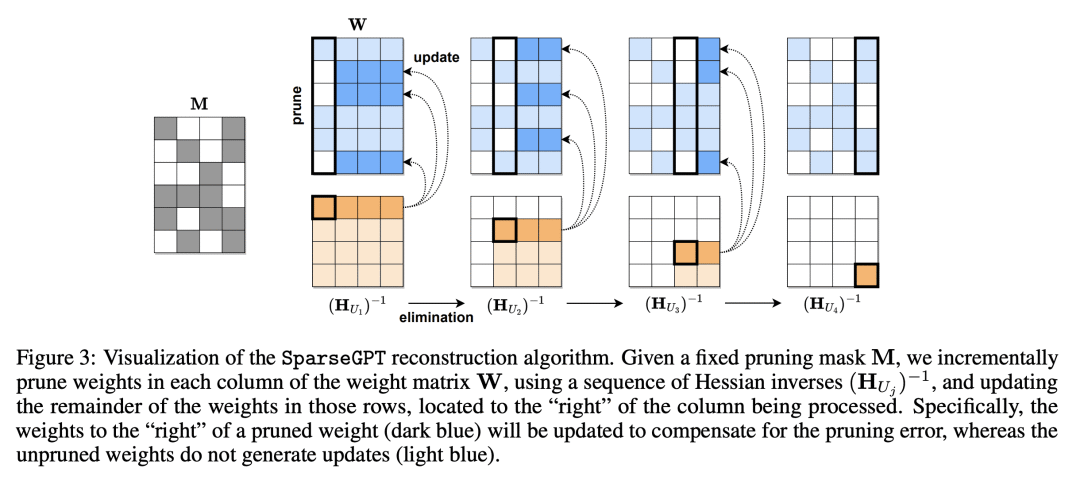
SparseGPT基于一种新的大规模近似稀疏回归算法,该算法与权重量化方法兼容。
摘要:
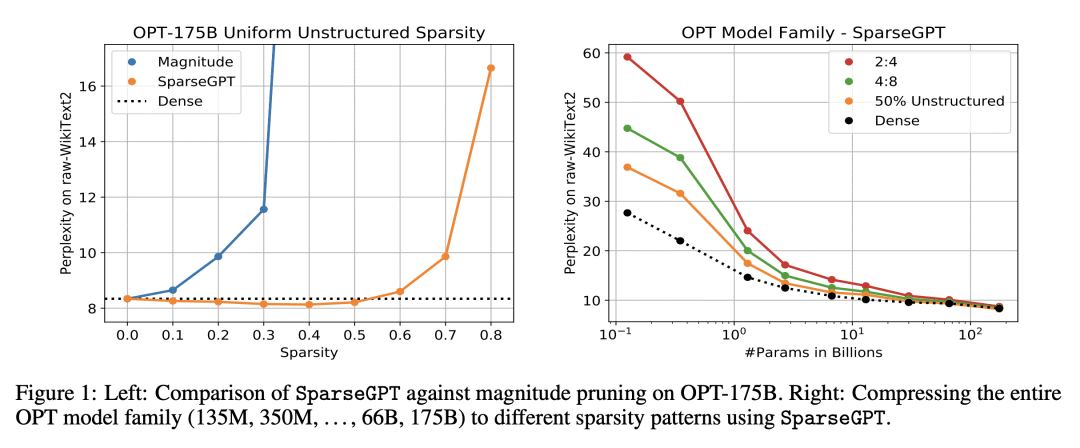
本文首次证明,大规模生成预训练transformer(GPT)族模型可以单样本修剪到至少50%的稀疏度,而无需任何再训练,且精度损失最小。这是通过一种名为SparseGPT的新修剪方法实现的,该方法专门设计用于高效、准确地处理大规模GPT族模型。在最大的可用开源模型OPT-175B和BLOOM-176B上执行SparseGPT时,可以达到60%稀疏,困惑度的增加可以忽略不计:值得注意的是,在推理时,这些模型的1000多亿个权重可以忽略。SparseGPT可推广到半结构化(2:4和4:8)模式,并与权重量化方法兼容。
We show for the first time that large-scale generative pretrained transformer (GPT) family models can be pruned to at least 50% sparsity in one-shot, without any retraining, at minimal loss of accuracy. This is achieved via a new pruning method called SparseGPT, specifically designed to work efficiently and accurately on massive GPT-family models. When executing SparseGPT on the largest available open-source models, OPT-175B and BLOOM-176B, we can reach 60% sparsity with negligible increase in perplexity: remarkably, more than 100 billion weights from these models can be ignored at inference time. SparseGPT generalizes to semi-structured (2:4 and 4:8) patterns, and is compatible with weight quantization approaches.
论文链接:https://arxiv.org/abs/2301.00774
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢