
来自今天的爱可可AI前沿推介
[CV] ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders
S Woo, S Debnath, R Hu, X Chen, Z Liu, I S Kweon, S Xie
[Meta AI & KAIST & New York University]
ConvNeXt V2: 基于掩码自编码器的卷积网络协同设计与扩展
要点:
-
提出ConvNeXt V2,一个新的ConvNet模型族,与掩码自编码器一起使用时性能有所提高; -
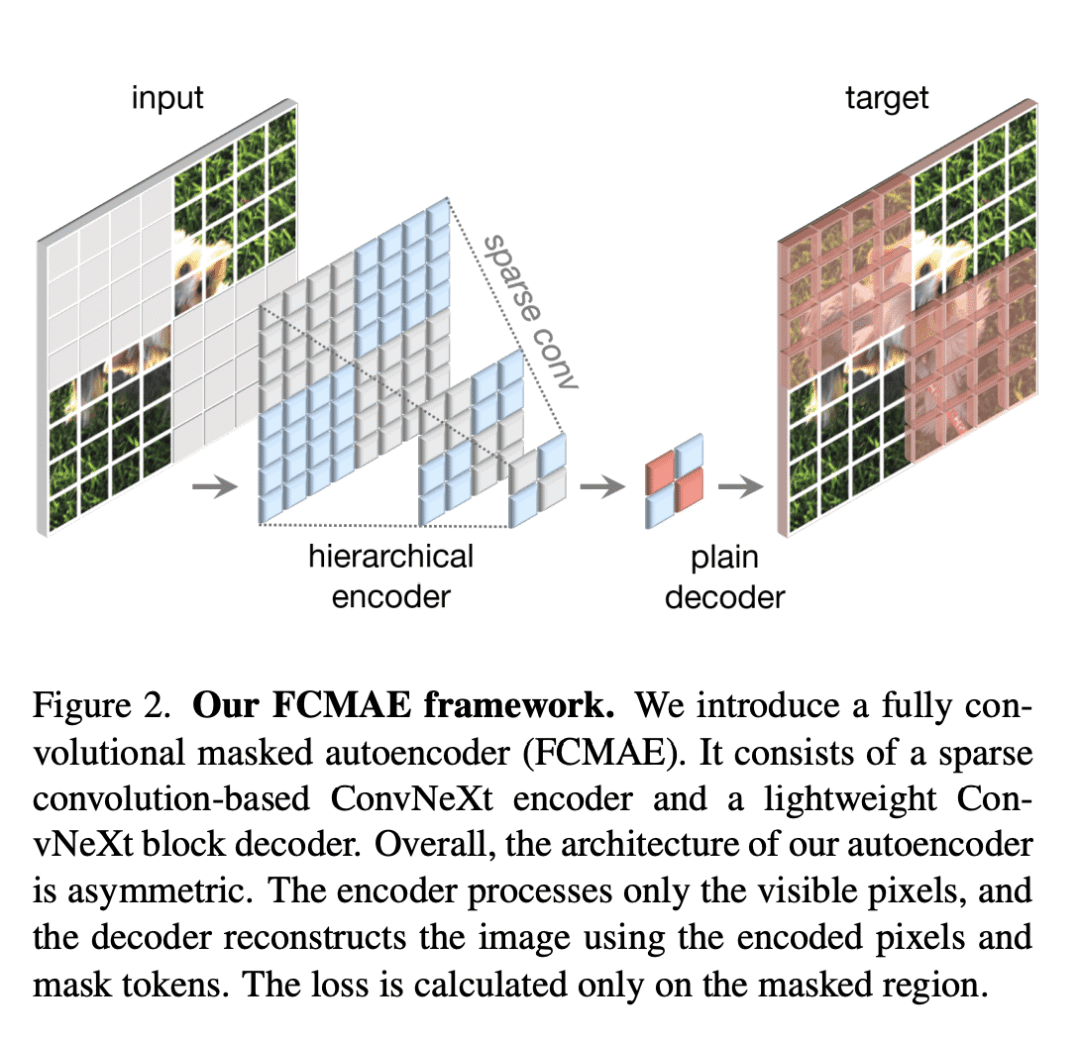
引入全卷积掩码自编码器框架和全局响应规范化层,可添加到ConvNeXt架构中; -
ConvNeXt V2显著提高了纯卷积网络在各种识别基准上的性能; -
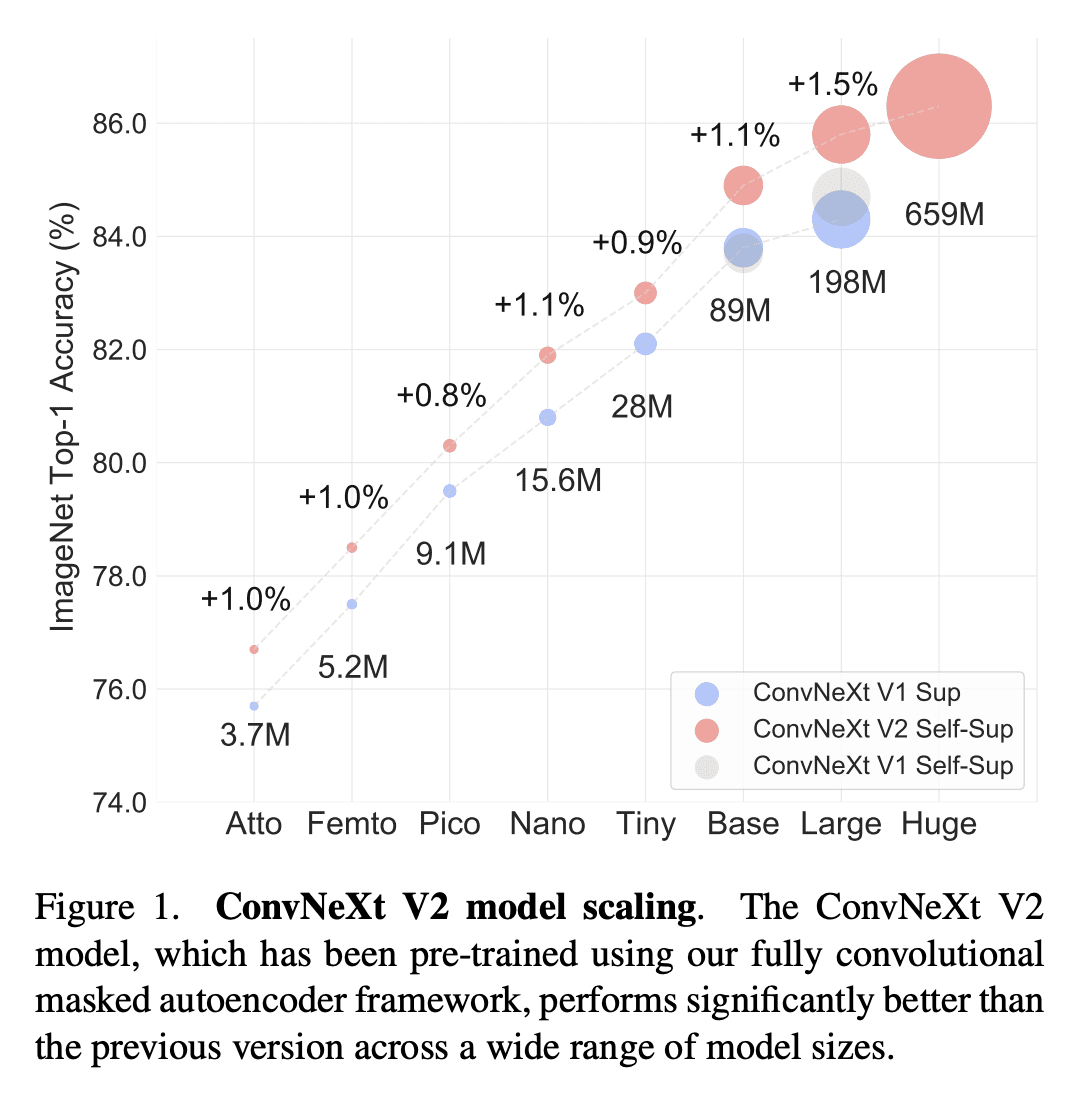
ConvNeXt V2模型有各种大小可供选择,包括高效的3.7M参数Atto模型和具有最先进性能的650M大型模型。
摘要:
在改进的架构和更好的表示学习框架的推动下,视觉识别领域在20世纪初实现了快速的现代化和性能提升。例如,以ConvNeXt为代表的现代ConvNet在各种场景中表现出了强劲的性能。虽然这些模型最初是为使用ImageNet标签的监督学习而设计的,但它们也可能受益于自监督学习技术,如掩码自编码器(MAE)。简单地将这两种方法结合起来会导致性能不佳。本文提出一种全卷积掩码自编码器框架和一种新的全局响应规范化(GRN)层,可添加到ConvNeXt架构中,以增强信道间特征竞争。这种自监督学习技术和架构改进的共同设计,产生了一个名为ConvNeXt V2的新模型族,大大提高了纯卷积网络在各种识别基准上的性能,包括ImageNet分类、COCO检测和ADE20K分割。本文提供了各种大小的预训练ConvNeXt V2模型,从ImageNet上精度为76.7%的高效3.7M参数Atto模型,到仅使用公开训练数据实现最先进88.9%精度的650M大型模型。
Driven by improved architectures and better representation learning frameworks, the field of visual recognition has enjoyed rapid modernization and performance boost in the early 2020s. For example, modern ConvNets, represented by ConvNeXt, have demonstrated strong performance in various scenarios. While these models were originally designed for supervised learning with ImageNet labels, they can also potentially benefit from self-supervised learning techniques such as masked autoencoders (MAE). However, we found that simply combining these two approaches leads to subpar performance. In this paper, we propose a fully convolutional masked autoencoder framework and a new Global Response Normalization (GRN) layer that can be added to the ConvNeXt architecture to enhance inter-channel feature competition. This co-design of self-supervised learning techniques and architectural improvement results in a new model family called ConvNeXt V2, which significantly improves the performance of pure ConvNets on various recognition benchmarks, including ImageNet classification, COCO detection, and ADE20K segmentation. We also provide pre-trained ConvNeXt V2 models of various sizes, ranging from an efficient 3.7M-parameter Atto model with 76.7% top-1 accuracy on ImageNet, to a 650M Huge model that achieves a state-of-the-art 88.9% accuracy using only public training data.
论文链接:https://arxiv.org/abs/2301.00808

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢