
腿式机器人的快速稳定运动涉及苛刻且矛盾的要求,特别是快速控制频率和精确的动力学模型。受益于神经网络的通用逼近能力和离线优化,强化学习已被用于解决有腿机器人运动中的各种具有挑战性的问题;然而,四足机器人的最优控制需要优化多个目标,如保持平衡、提高效率、实现周期性步态和服从命令等。这些目标不能总是同时实现,尤其是在高速情况下。
在这里,浙江大学团队介绍了一种模仿松弛强化学习 (IRRL) 方法来分阶段优化目标。为了弥合模拟与现实之间的差距,研究人员进一步将随机稳定性的概念引入系统稳健性分析中。状态空间熵递减率是一个定量指标,可以敏锐地捕捉到倍周期分岔的发生和可能出现的混沌。通过在训练和随机稳定性分析中使用 IRRL,研究人员证明 MIT-MiniCheetah 类机器人的稳定运行速度为 5.0 m s^–1。
该研究以「High-speed quadrupedal locomotion by imitation-relaxation reinforcement learning」为题,于 2022 年 12 月 14 日发布在《Nature Machine Intelligence》。

论文链接 https://www.nature.com/articles/s42256-022-00576-3
提高敏捷性,达到并超越动物的最大速度对于有腿机器人研究来说是一项挑战。对于动物来说,它们卓越的机动性是灵巧的骨骼-肌肉系统和复杂的中央感觉-运动控制结构的内在结果。这激发了新的设计理念和新颖的控制算法,以实现与自然对应物相媲美的性能。
在这里,浙江大学团队提出了一种系统的学习范式和基于 RL 的控制器的稳健性评估,该控制器专用于机器人的稳定高速运动。为了避免不真实的行为,在训练过程中提供了参考轨迹作为指导。然而,性能对高速运行的参考轨迹之间的微小差异很敏感。同时,没有适合所有速度范围的单一理想参考轨迹。为了减轻这种严格的要求,研究人员设计了一个经过调整的两步训练过程。在第一步中,控制器通过模仿学习进行训练,以便可以近似地再现运动学参考轨迹。随后是松弛步骤,通过部分消除非理想参考轨迹的影响来适应特定的机器人动力学。值得注意的是,模仿和松弛强化学习(IRRL)过程是降低训练成本和在高维参数空间中找到最优解的关键。
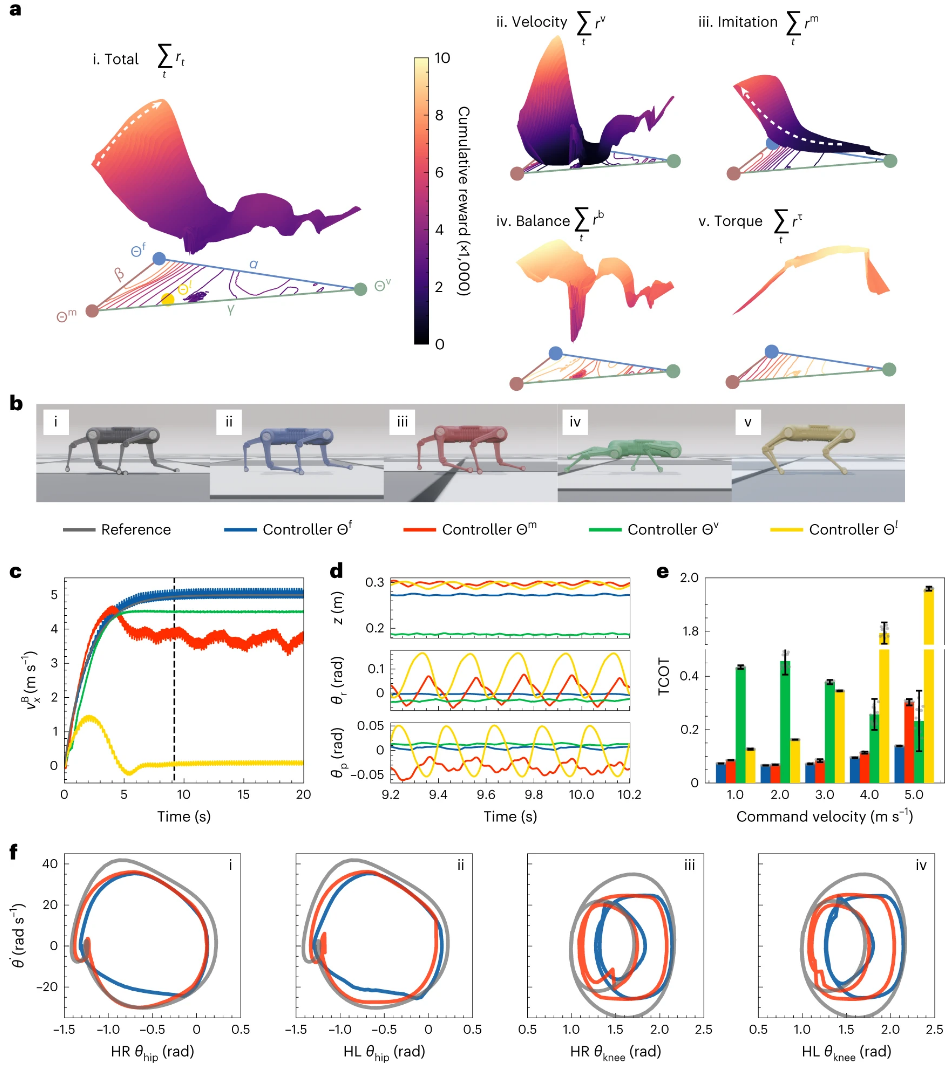
图示:IRRL 方法的概念和验证
对于机器人系统的随机性,熵稳定性是扰动后恢复极限循环运动能力的一种可行措施。机器人状态分布将缩小到极限圆,导致随机稳定系统状态空间的熵减少。否则,倍周期和混沌系统的状态熵会增加。熵递减率是动态系统稳定性的一个关键指标。RL 控制器的随机稳定性很容易评估,这本质上是一个随机问题,并基于对动作空间的采样进行优化。借助并行的大规模模拟,可以收集一组在各种扰动下的轨迹,从而给出熵计算的演化状态分布。这样,系统延迟、地面摩擦和特定步态的影响可以单独考虑。
通过在训练和随机稳定性分析中使用 IRRL,控制器和机器人硬件都得到了相应的改进。研究人员证明了 MIT-MiniCheetah 类机器人的稳定运行速度为 5.0 m s^–1,与 MIT-MiniCheetah 机器人达到的最高速度(3.7 m s^–1)相比提高了 35%。无量纲弗劳德数为 8.5,高于此前由专门跑步的四足机器人 MIT-Cheetah II 创下的 7.1 的记录。

双足机器人在地形上打滑后的压力响应
受益于神经网络的通用逼近能力和离线优化,RL 方法可以缓解动态模型精度和控制频率之间长期存在的冲突。这为充分探索硬件追赶甚至超越动物敏捷性的潜力提供了一条可行的途径。不幸的是,由于多个目标之间的冲突,局部极值严重限制了 RL 的有效性。Easy-to-hard learning是解决这个问题的成熟策略。由于模拟奖励的单峰性质,如参数超平面上的累积奖励表面所示,局部极值通过两步 IRRL 方法绕行。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢