
知识蒸馏(KD)作为一种有前途的模型压缩解决方案,已被应用于实时推荐中以减少推荐延迟。传统的解决方案首先从训练数据训练一个完整的教师模型,然后转移它的知识(即软标签)来监督一个紧凑的学生模型的学习。那么,什么是软标签呢?比如在推荐系统中,软标签可以是教师对用户-商品交互的预测,通常用于知识转移,这些KDs将根据软标签创建或采样训练实例,用于训练学生模型。因此,软标签的质量是知识蒸馏的基础。然而,所产生的软标签会产生严重的偏差问题,蒸馏后更强烈地推荐流行商品,使得学生模型无法做出准确公平的推荐,降低了操作系统的有效性。
本文中,作者找到了KD出现偏差问题的原因------教师的偏误软标签,导致标签在蒸馏过程中进一步传播和强化。所以作者提出了一种新的分层蒸馏策略的KD方法,首先根据的受欢迎程度将商品分成多个组,然后提取每个组内的排名信息来监督学生模型学习。分层策略几乎可以阻断教师偏见的因果效应。作者所提出的方法在蒸馏阶段,与教师模型训练无关。
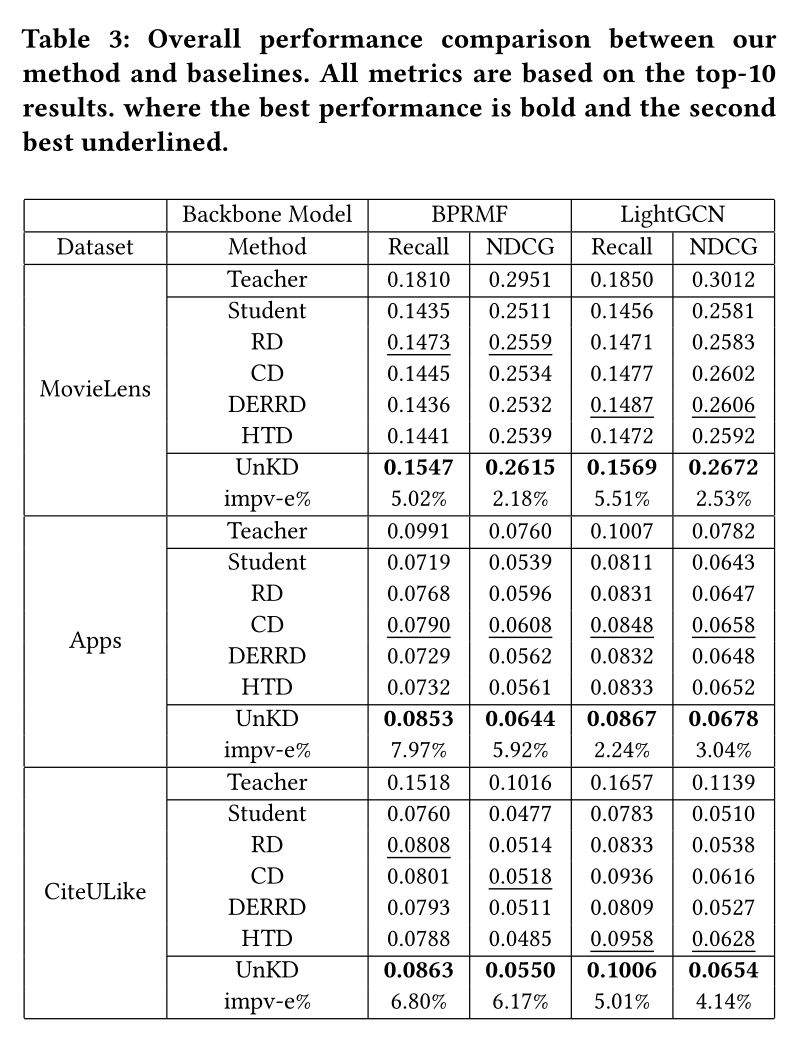
实验结果显示,UnKD与其余方法相比,表现最佳。
论文标题:Unbiased Knowledge Distillation for Recommendation
收录会议:WSDM 2023
论文链接:https://doi.org/10.48550/arXiv.2211.14729
代码链接:https://github.com/chengang95/UnKD

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢