
作者:Jay Zhangjie Wu , Yixiao Ge , Xintao Wang , 等
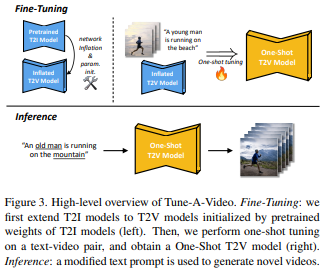
简介:本文研究在Text2Video生成领域引入扩散模型。为了再现文本到图像(T2I)的成功生成,最近的文本到视频生成(T2V)工作使用大规模文本-视频数据集进行微调。然而,这种范式在计算上很昂贵。人类有惊人的能力从一个范例中学习新的视觉概念。作者针对性研究并提出了一个新的T2V生成问题,即单样本视频生成,其中仅呈现单个文本视频对来训练开放域T2V生成器。 作者建议将基于海量图像数据预处理的T2I扩散模型用于T2V生成。作者做了两个关键观察:1)T2I模型能够生成与动词术语很好地对齐的图像;2) 扩展T2I模型以同时生成多个图像显示出令人惊讶的良好内容一致性。为了进一步学习连续运动,作者提出了具有定制的稀疏因果注意的Tune-A-Video,它通过对预训练的T2I扩散模型进行有效的一次性调整、实现从文本提示生成视频。Tune-A-Video能够在各种应用程序(如主题或背景的改变、属性编辑、风格转换)上生成时间连贯的视频,证明了作者方法的通用性和有效性。


论文下载:https://arxiv.org/pdf/2212.11565.pdf
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢