
作者:Elias Frantar, Dan Alistarh
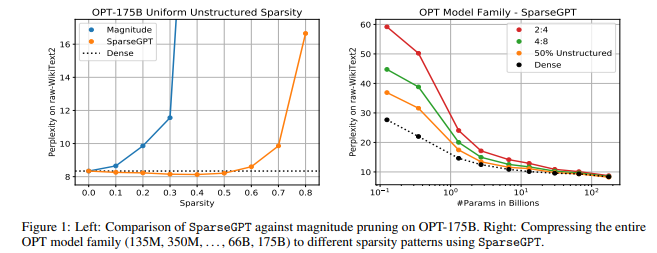
简介:本文研究专门针对GPT家族中大语言模型的新剪枝方法。作者首次展示了大规模生成预训练Transformer(GPT) 系列模型可以一次性修剪到至少 50% 的稀疏性,而无需任何重新训练,并且精度损失最小。这是通过一种称为 SparseGPT 的新剪枝方法实现的,该方法专门设计用于在大规模 GPT 系列模型上高效准确地工作。在最大的可用开源模型 OPT-175B 和 BLOOM-176B 上执行 SparseGPT 时,作者可以达到 60% 的稀疏度,而困惑度的增加可以忽略不计。值得注意的是,在推理时可以忽略来自这些模型的超过 1000 亿个权重。SparseGPT 泛化为半结构化(2:4 和 4:8)模式,并且与权重量化方法兼容。
未来工作的一个自然途径是研究此类大型模型的微调机制,这将允许进一步恢复精度。作者推测这应该是可能的,并且通过逐步修剪和微调,将可能可以实现至少80-90%的稀疏性。
论文下载:https://arxiv.org/pdf/2301.00774.pdf
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢