
来自今天的爱可可AI前沿推介
[CL] Neural Codec Language Models are Zero-Shot Text to Speech Synthesizers
C Wang, S Chen, Y Wu, Z Zhang, L Zhou, S Liu, Z Chen, Y Liu, H Wang, J Li, L He, S Zhao, F Wei
[Microsoft]
神经编解码器语言模型是零样本文本到语音合成器
要点:
-
提出 VALL-E,一种神经编解码语言模型,用于文本到语音合成(TTS),能学习上下文并仅用3秒没见过的说话者录音作为提示进行零样本合成; -
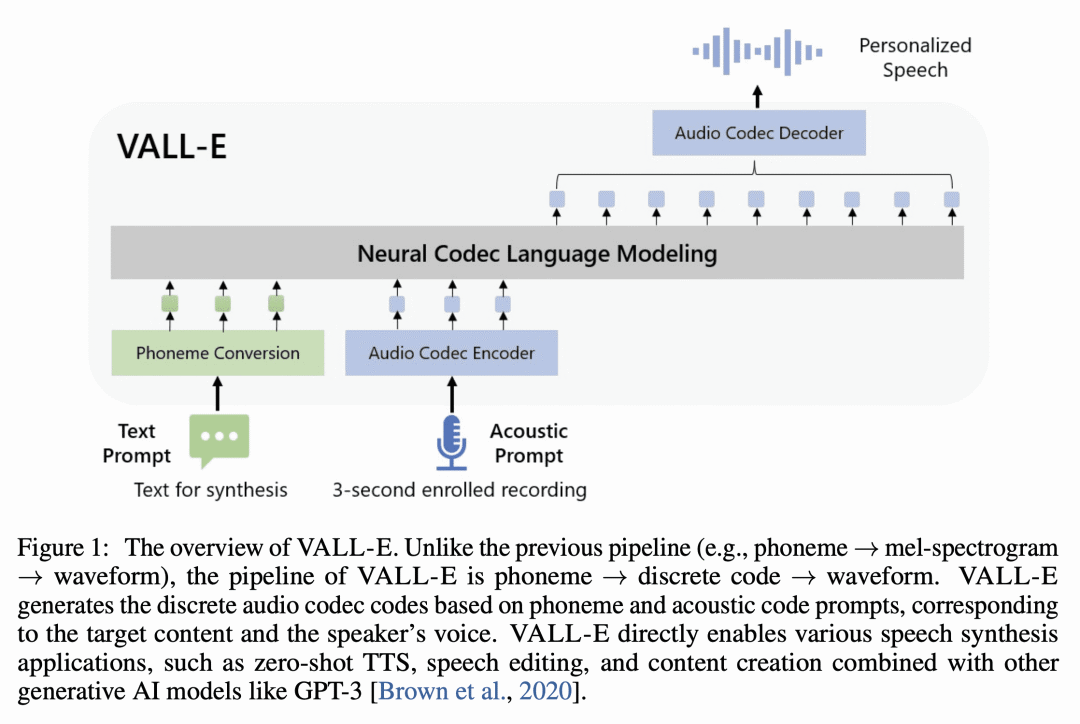
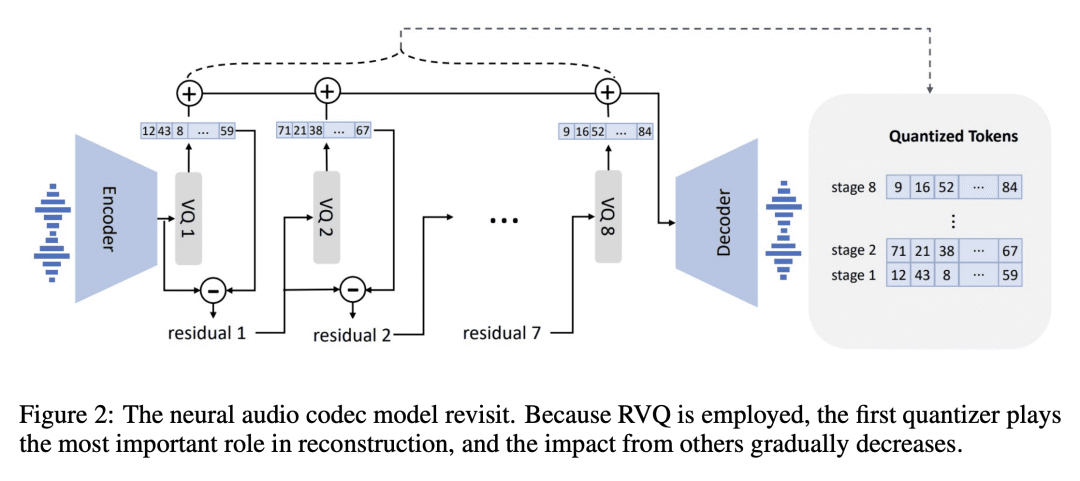
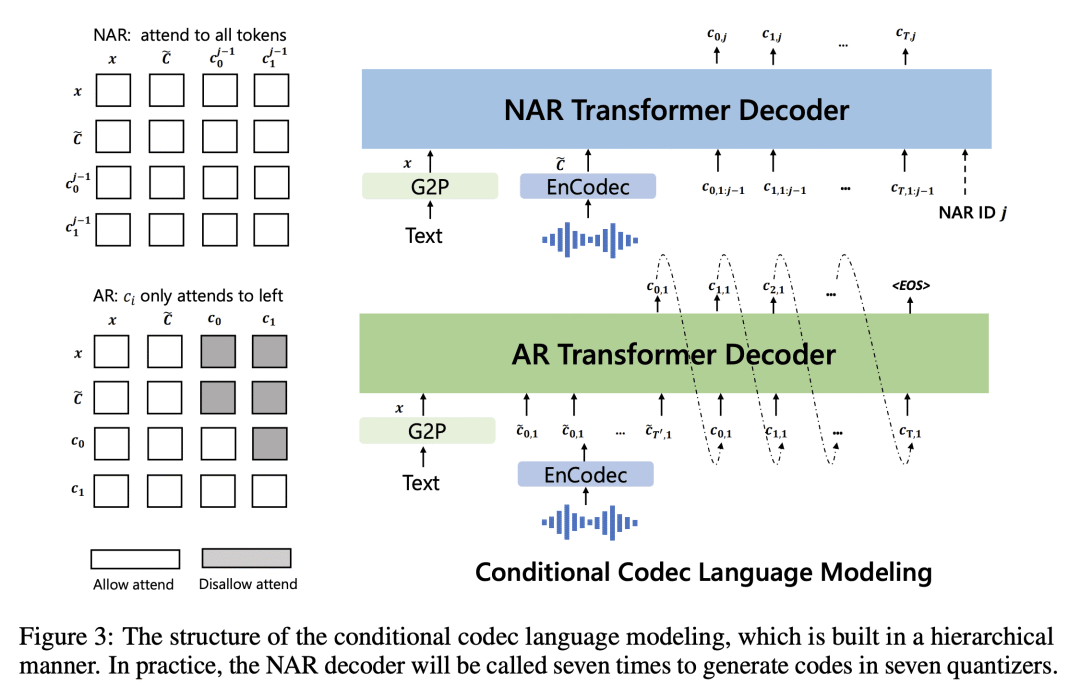
VALL-E 将 TTS 视为使用音频编解码代码作为中间表示的语言建模任务,而不是之前方法中的连续信号回归; -
VALL-E 能用相同的输入文本提供不同的输出,并保留所提示的声学环境和说话者的情感; -
在 LibriSpeech 和 VCTK 上的评估结果显示,在自然度和说话人相似度方面,VALL-E 明显优于最先进的零样本 TTS 系统。
一句话总结:
VALL-E 是一种新的面向 TTS 的神经编解码语言模型,具有强大的上下文学习能力,可实现与最先进技术相比的卓越零样本生成性能。
摘要:
本文提出一种用于文本到语音合成(TTS)的语言建模方法。用来自现成神经音频编解码模型的离散代码训练一个神经编解码语言模型(Vall-E),将 TTS 视为条件语言建模任务,而不是之前工作中的连续信号回归。在预训练阶段,将 TTS 训练数据扩展到 60000 小时的英语语音,是现有系统的数百倍。Vall-E 具有上下文学习能力,可以用仅有 3 秒钟的没见过的说话者录音提示来合成高质量的个性化语音。实验结果表明,Vall-E 在语音自然度和说话人相似度方面,明显优于最先进的零样本 TTS 系统。此外,Vall-E 可以在合成中保留所提示的声学环境和说话人的情感。
We introduce a language modeling approach for text to speech synthesis (TTS). Specifically, we train a neural codec language model (called Vall-E) using discrete codes derived from an off-the-shelf neural audio codec model, and regard TTS as a conditional language modeling task rather than continuous signal regression as in previous work. During the pre-training stage, we scale up the TTS training data to 60K hours of English speech which is hundreds of times larger than existing systems. Vall-E emerges in-context learning capabilities and can be used to synthesize high-quality personalized speech with only a 3-second enrolled recording of an unseen speaker as an acoustic prompt. Experiment results show that Vall-E significantly outperforms the state-of-the-art zero-shot TTS system in terms of speech naturalness and speaker similarity. In addition, we find Vall-E could preserve the speaker's emotion and acoustic environment of the acoustic prompt in synthesis. See this https URL for demos of our work.
论文链接:https://arxiv.org/abs/2301.02111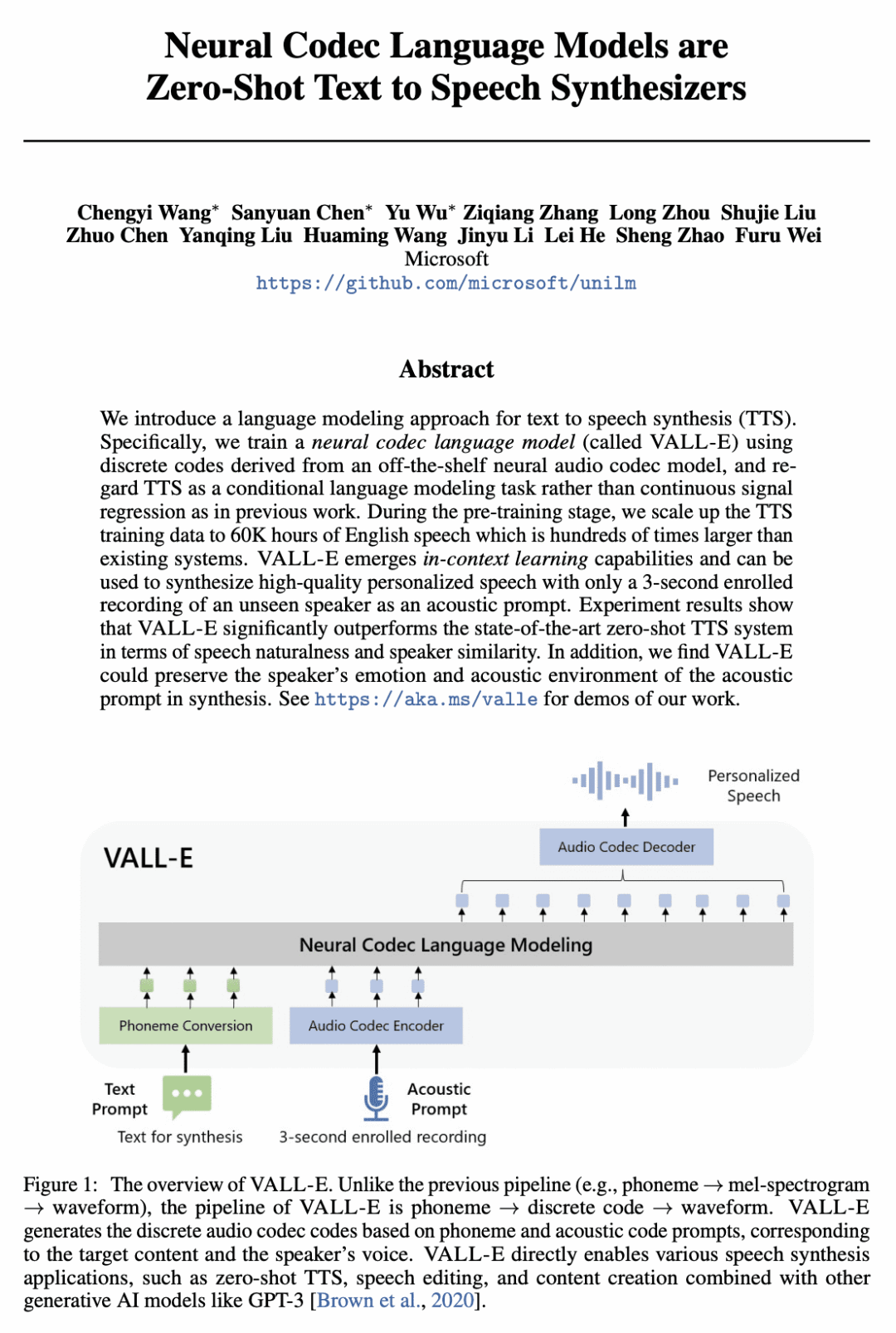
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢