
作者郭瑞东,审校梁金,编辑邓一雪
Google 研究者发表了题为“大型语言模型的涌现能力”(Emergent Abilities of Large Language Models)的论文,考察了以 GPT-3 为代表的语言模型,发现语言模型的表现并非随着模型规模增加而线性增长,而是存在临界点,只有当模型大到超过特定的临界值,才会涌现出较小的模型不具备的能力。语言模型的这种涌现能力意味着,大型语言模型可能进一步扩展语言模型的功能。

论文标题:
Emergent Abilities of Large Language Models
论文链接:
该研究中,作者对语言模型的涌现能力给出了如下定义:“如果一种能力不存在于较小的模型中,而存在于较大的模型中,那么这种能力就是涌现出来的。”可以通过不同的方式对模型大小进行测量,包括训练时计算量(FLOPs)、参数数量或训练数据大小。图1显示了涌现能力的三个例子:运算能力、参加大学水平的考试(多任务 NLU),以及识别一个词的语境含义的能力。在每种情况下,语言模型最初表现很差,并且与模型大小基本无关,但当模型规模达到一个阈值时,语言模型的表现能力突然提高。
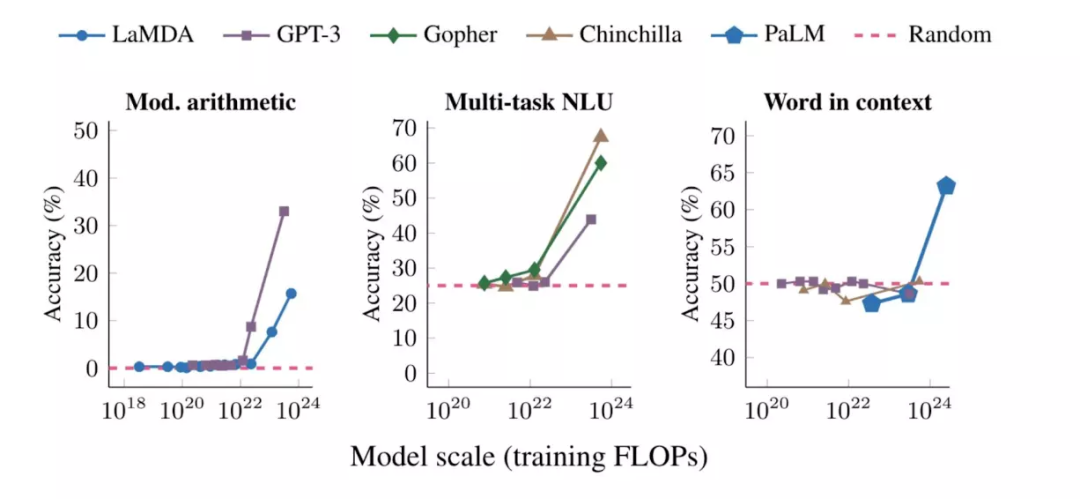
图1. 在多步计算、多任务语言理解和语境中的词汇含义三任务上,语言模型的准确度只有当模型规模(训练时的FLOPs)超过一个阈值时才突然提高。
另一类涌现能力包括提示策略(prompting strategy)以增强语言模型的能力。这些策略之所以出现,是因为较小的模型无法成功地使用这些策略,只有足够大的语言模型才可以。例如“思维链提示”(chain-of-thought prompting),其中模型被提示在给出最终答案之前生成一系列中间步骤。
研究者发现,语言模型的涌现能力是一个普遍现象而非特例,文中总结了GPT-3模型具有的137项涌现能力,对于更传统的NLP基准模型,例如 BIG-Bench,其具有的涌现能力也包括67项。图3展示了不同模型在多种任务上,准确性和模型大小都呈现相变(phase transition)。
而另一项相关研究,关注GPT-3在类比推断上的涌现能力,发现在抽象模式归纳、匹配等需要类比思维的问题上,足够大的语言模型即使没有直接训练,也可以展现出超越人类的准确性。
论文地址:Emergent Analogical Reasoning in Large Language Models
论文地址:https://arxiv.org/abs/2212.09196
在可预见的未来,大型语言模型仍将是机器学习研究的主流。语言模型在零次学习(zero shot learning)上的涌现能力,已让它们得以进入实际应用领域(例如chatGPT),并在自然语言处理研究领域之外有许多新的应用。例如,语言模型通过提示将自然语言指令转换为机器人可执行操作的命令,或促进多模态推理(根据文字作画)。为此,我们需要继续研究它们的涌现能力和局限性,建立对涌现能力的一般性理解(目前缺少令人信服的解释),并探索未实现的潜力及最终极限。
涌现能力具有重要的科学意义,如果涌现能力是没有尽头的,那么只要模型足够大,强 AI 的出现就是必然的。对现有语言模型涌现特征的研究发现,语言模型的表现和模型大小之间的关系是不可线性外推的,有理由相信,随着模型大小的增加,模型将会变得更加鲁棒。
随着机器学习社区朝着创建更大的语言模型的方向发展,人们越来越担心大语言模型的研究和开发将集中在少数几个拥有财政和计算资源来训练和运行这些模型的组织中。通过对特定任务数据集的小型模型进行微调,可以使用小模型替代大语言模型。该研究的作者指出:一旦一种能力被发现,进一步的研究可能会使这种能力适用于小尺度模型。随着我们继续训练越来越大的语言模型,降低涌现能力发生相变的门槛,对于让社区更广泛地获得这种能力的研究将变得更加重要。
未来关于涌现能力的研究方向包括训练更有能力的语言模型(例如改进模型结构和训练程序,可以促进具有涌现能力的高质量模型,同时减少计算成本;使用数据增强,在更小的模型上重现涌现能力),以及通过理解涌现能力的来源,开发可用于更好地支持语言模型执行任务的提示策略。研究者还可以使用交叉熵、困惑度(preplexity)等新的测量方式,研究语言模型及多模态模型的涌现能力。
本文转自集智俱乐部,阅读原文请点击这里
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢