
来自今日爱可可的前沿推介
Parameter-Efficient Fine-Tuning Design Spaces
J Chen, A Zhang, X Shi, M Li, A Smola, D Yang
[Georgia Institute of Technology & Amazon Web Services & Stanford University]
设计空间的参数高效微调
要点:
-
提出设计空间的参数高效微调,通过综合实验发现了参数高效微调的设计模式; -
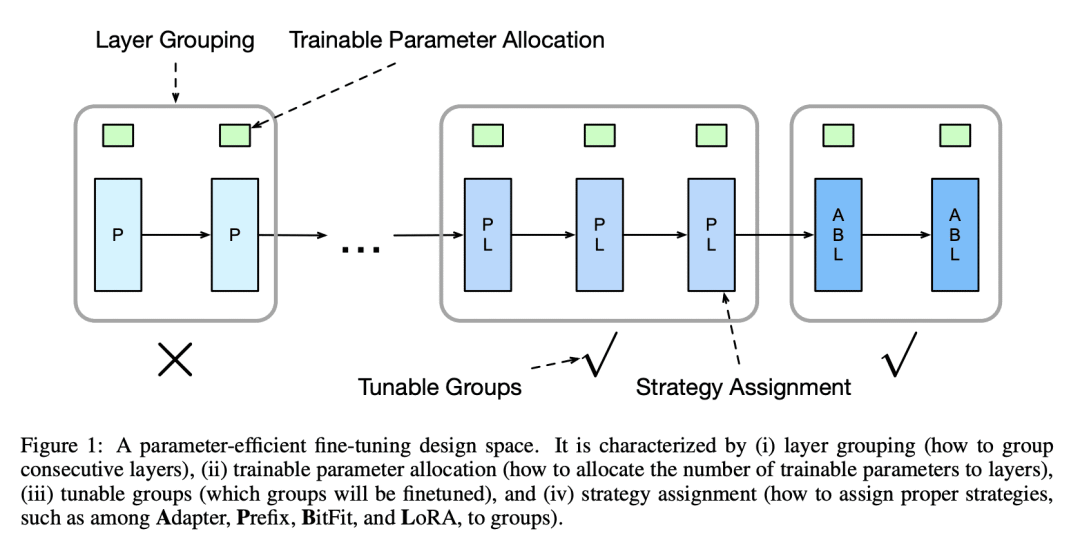
指出表征设计空间的四个组件:层分组、可训练参数分配、可调节组和策略分配; -
基于发现的设计模式开发了参数高效微调方法,在不同的底层模型和不同的自然语言处理任务中始终优于现有的微调策略。
提出设计空间的参数高效微调,通过实验发现设计模式,并开发了新方法,在不同的自然语言处理任务中始终优于现有的微调策略。
摘要:
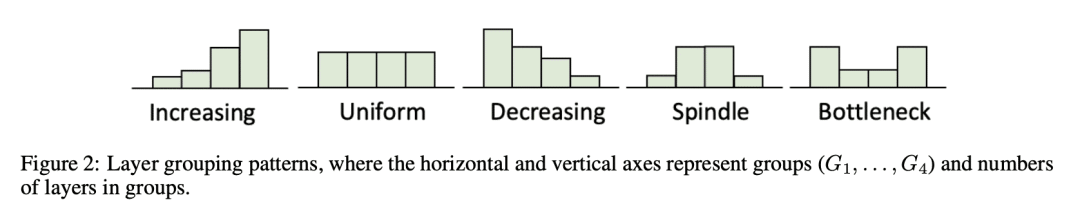
参数高效微调旨在用更少的可训练参数达到与微调相当的性能。已经提出了几种策略(例如 Adapters、prefix tuning、BitFit 和 LoRA)。但是,这些设计是单独手工开放的,目前尚不清楚是否存在某些设计模式适用于参数高效微调。因此,本文提出一种参数高效的微调设计范式,并发现了适用于不同实验设置的设计模式。引入参数高效微调设计空间,将微调结构和微调策略参数化,而不是专注于设计另一种单独的微调策略。任何设计空间都由四个组件表征:层分组、可训练参数分配、可调节组和策略分配。本文从初始设计空间开始,根据每种设计选择的模型质量逐步细化空间,并在这四个组件上进行贪婪选择。结果发现了以下设计模式:(i) 将层分组为锥形模式;(ii) 将可训练参数数量均匀分配到各层;(iii) 微调所有组;(iv) 将适当的微调策略分配给不同的组。这些设计模式带来了新的参数高效微调方法。实验证明,这些方法在不同的底层模型和不同的自然语言处理任务中始终显著优于其他参数高效微调策略。
https://arxiv.org/abs/2301.01821
Parameter-efficient fine-tuning aims to achieve performance comparable to fine-tuning, using fewer trainable parameters. Several strategies (e.g., Adapters, prefix tuning, BitFit, and LoRA) have been proposed. However, their designs are hand-crafted separately, and it remains unclear whether certain design patterns exist for parameter-efficient fine-tuning. Thus, we present a parameter-efficient fine-tuning design paradigm and discover design patterns that are applicable to different experimental settings. Instead of focusing on designing another individual tuning strategy, we introduce parameter-efficient fine-tuning design spaces that parameterize tuning structures and tuning strategies. Specifically, any design space is characterized by four components: layer grouping, trainable parameter allocation, tunable groups, and strategy assignment. Starting from an initial design space, we progressively refine the space based on the model quality of each design choice and make greedy selection at each stage over these four components. We discover the following design patterns: (i) group layers in a spindle pattern; (ii) allocate the number of trainable parameters to layers uniformly; (iii) tune all the groups; (iv) assign proper tuning strategies to different groups. These design patterns result in new parameter-efficient fine-tuning methods. We show experimentally that these methods consistently and significantly outperform investigated parameter-efficient fine-tuning strategies across different backbone models and different tasks in natural language processing.

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢