
【标题】Lexicographic Multi-Objective Reinforcement Learning
【作者团队】Joar Skalse, Lewis Hammond, Charlie Griffin, Alessandro Abate
【发表日期】2022.12.28
【论文链接】https://arxiv.org/pdf/2212.13769.pdf
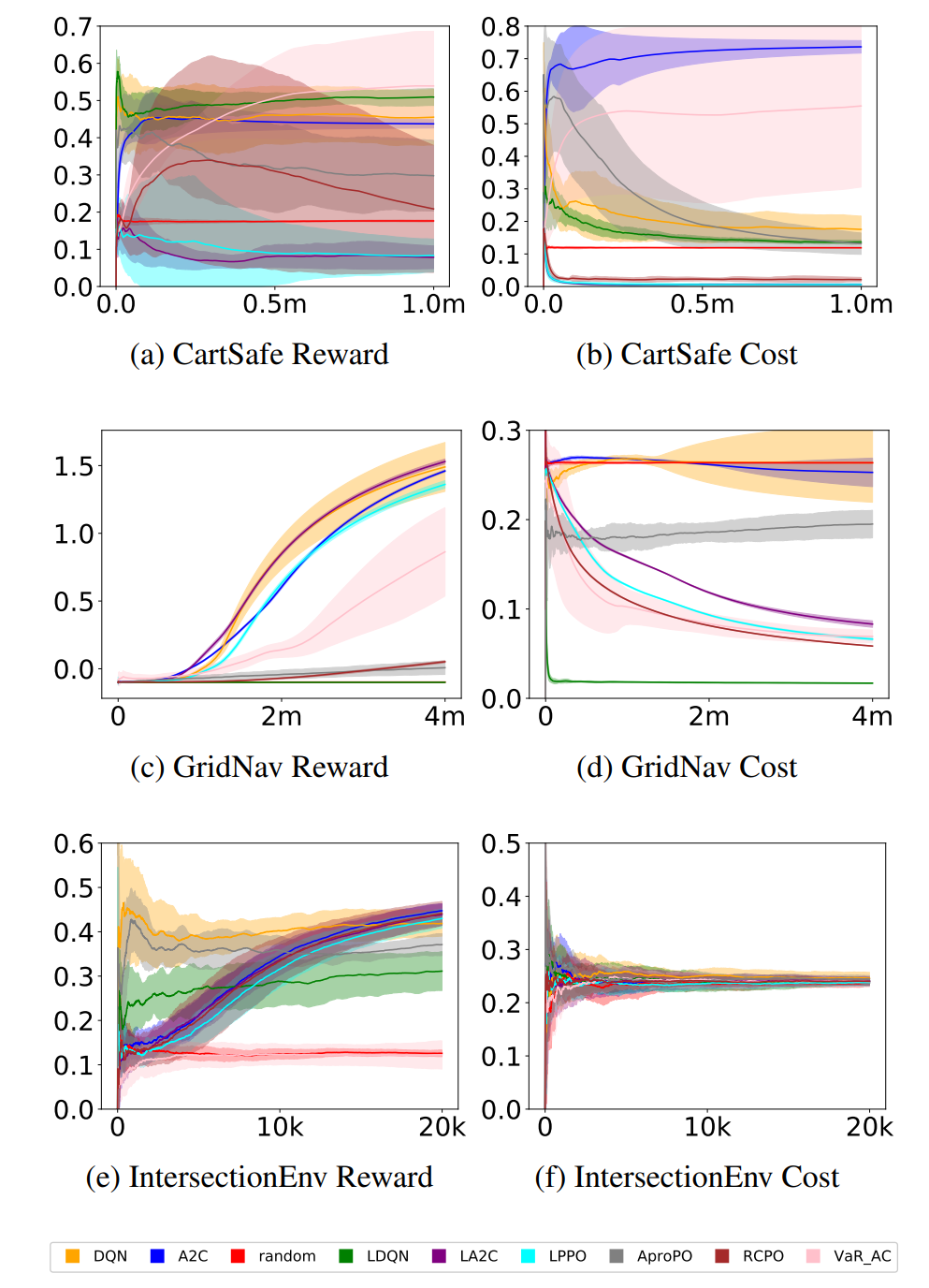
【推荐理由】在这项工作中,作者介绍了用于解决词典多目标问题的强化学习技术。 这些是涉及多个奖励信号的问题,目标是学习最大化第一个奖励信号的策略,并且受此约束也最大化第二个奖励信号,依此类推。 本文提出了一系列可用于解决此类问题的动作值和策略梯度算法,并证明它们收敛到字典序最优的策略。 作者根据经验评估这些算法的可扩展性和性能,证明它们的实际适用性。 作为更具体的应用,作者展示了如何使用本文的算法对智能体的行为施加安全约束,并将它们在这种情况下的性能与其他受约束的强化学习算法的性能进行比较。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢