
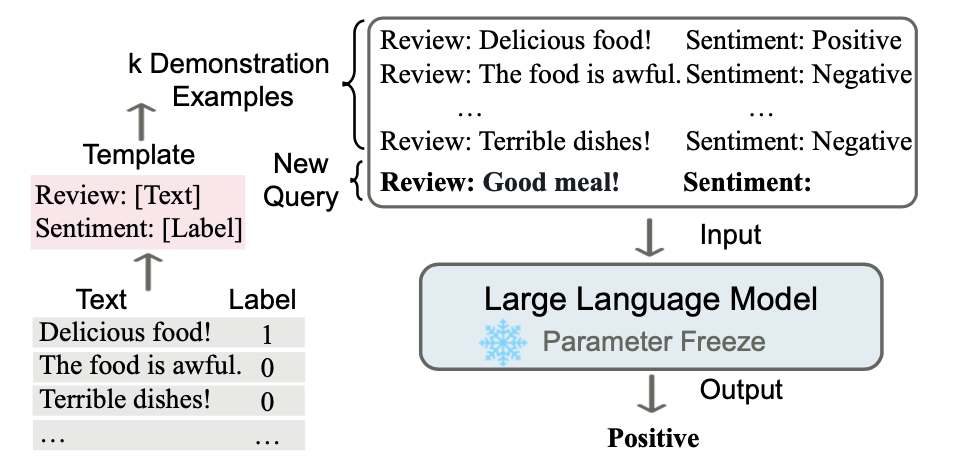
虽然ChatGPT在大众眼里的热度可能已经过去了,但它prompt出了我的焦虑,于是最近一直在补大模型相关的工作。比起小模型,大模型有一个很重要的涌现能力(Emergent ability)就是In-Context Learning(ICL),也是一种新的范式,指在不进行参数更新的情况下,只在输入中加入几个示例就能让模型进行学习,如下图中用ICL做情感分析任务的栗子:
忽略大模型的贵,这个范式具备不少优势:
-
输入的形式是自然语言,可以让我们可以更好地跟语言模型交互,通过修改模版和示例说明我们想要什么,甚至可以把一些知识直接输入给模型
-
这种学习方式更接近人类,即通过几个例子去类比,而不是像精调一样从大量语料中统计出规律
-
相比于监督学习,ICL不需要进行训练,降低了模型适配新任务的成本,同时也提升了
language-model-as-a-service这种模式的可行性
是不是开始觉得有些香了,甚至想动手试一试?但又觉得跟自己以前会玩的精调有很大区别,不知道从何下手炼丹?
下面就给大家推荐一篇北大出品的综述,可以在一定程度上减少大家入门ICL的痛苦:

题目:A Survey for In-context Learning
链接:https://arxiv.org/abs/2301.00234
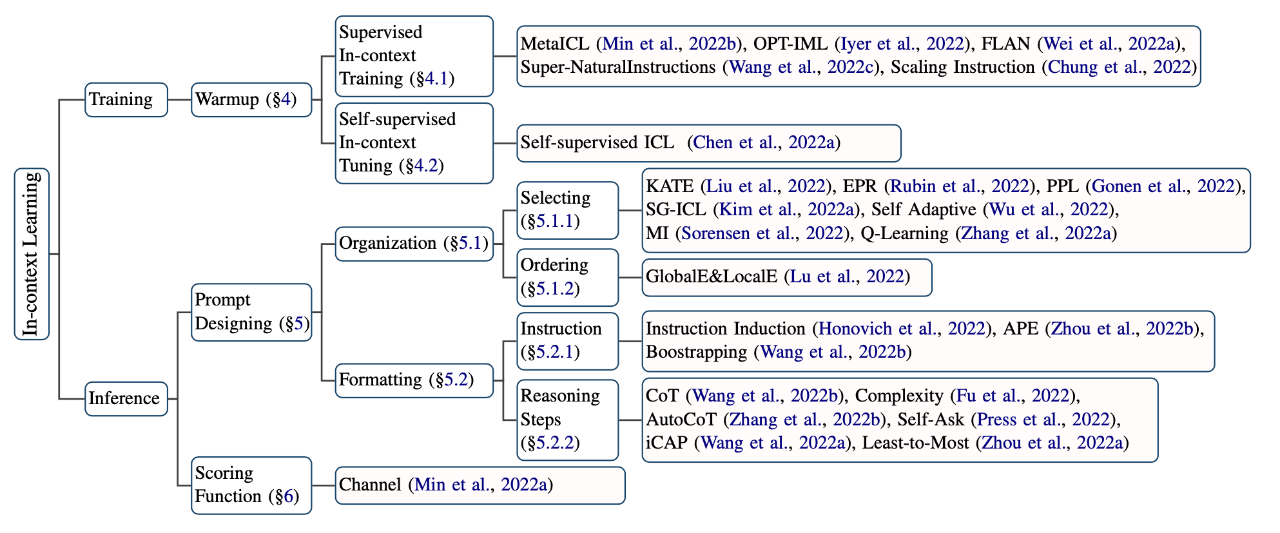
这篇文章非常系统地从精调、推理两个方向上给出了ICL的几种优化方法,接下来我们一一学习:
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢