
来自 KAIST、Meta、纽约大学的研究者(包括ConvNeXt一作刘壮、ResNeXt 一作谢赛宁)提出在同一框架下共同设计网络架构和掩码自编码器,这样做的目的是使基于掩码的自监督学习能够适用于 ConvNeXt 模型,并获得可与 transformer 媲美的结果。
论文地址:https://arxiv.org/pdf/2301.00808v1.pdf
S Woo, S Debnath, R Hu, X Chen, Z Liu, I S Kweon, S Xie
[Meta AI & KAIST & New York University]
ConvNeXt V2: 基于掩码自编码器的卷积网络协同设计与扩展
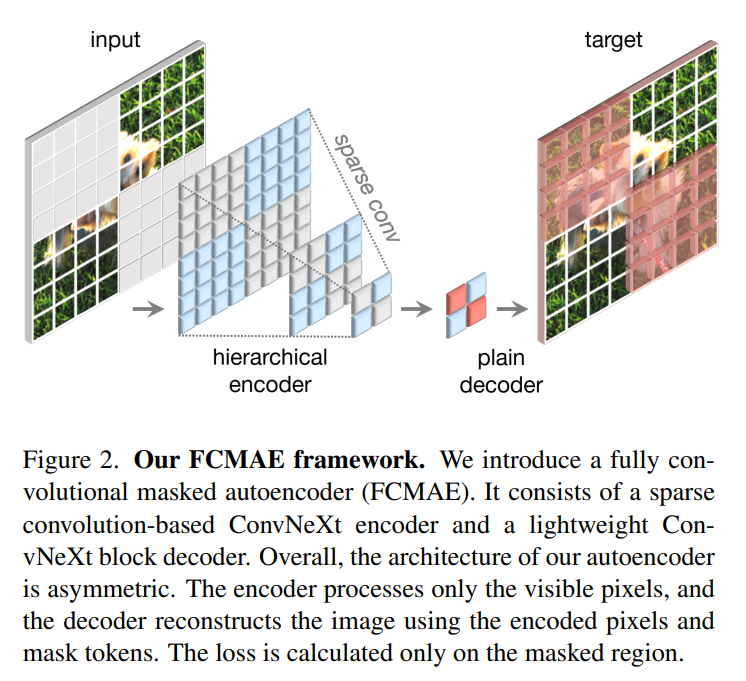
该研究提出的方法在概念上很简单,是以完全卷积的方式运行的。学习信号通过对原始的视觉输入随机掩码来生成,同时掩码的比率需要较高,然后再让模型根据剩余的 context 预测缺失的部分。整体框架如下图所示。框架由一个基于稀疏卷积的 ConvNeXt 编码器和一个轻量级的 ConvNeXt 解码器组成,其中自编码器的结构是不对称的。编码器只处理可见的像素,而解码器则使用已编码的像素和掩码 token 来重建图像。同时只在被掩码的区域计算损失。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢