

前言
丁香医生的评论区和后台,每天都会收到成千上万条关于健康的问题。为了帮助用户解决各种健康疑问,丁香医生提供了多种不同形式的服务。对于高频、有共性的问题,通过数百位医生、专家收集整理资料,编写成专业易懂、FAQ问答形式的「健康百科」。此外,还有大量「专家科普」深度长文,解释每个医疗知识背后的来龙去脉。
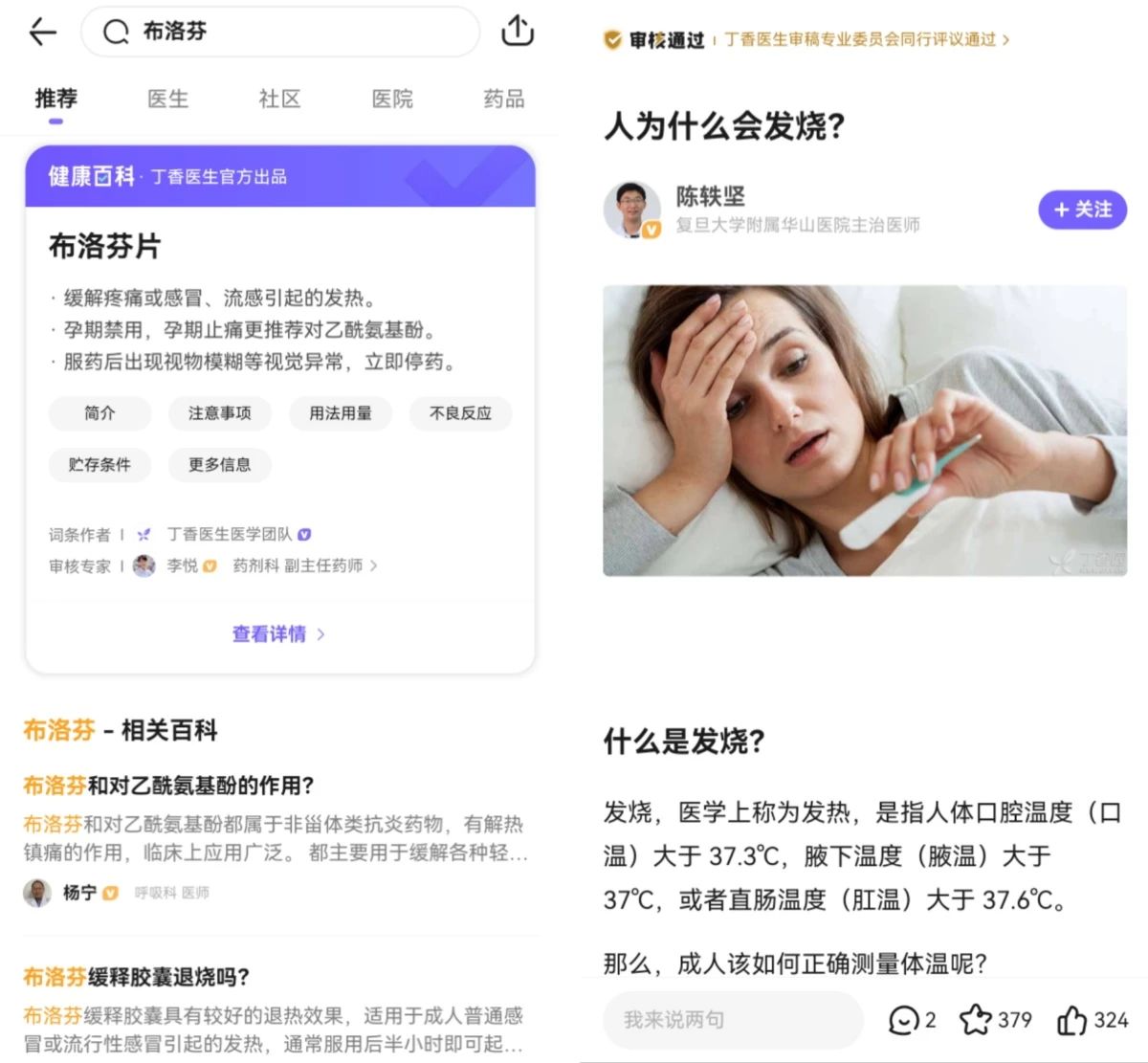
这两类内容都具备良好的结构化,有相对工整的标题,有归属的科室,同时或以医疗实体分类,或以健康topic分类等。用户通过搜索的方式即可方便地触达到内容。不过,医学毕竟是个复杂的话题,很多病症在不同人身上个体差异也特别大,参照最近大家阳了的情况:
得新冠就像小马过河,小马问松鼠,水深吗?松鼠说:“太深了!我朋友过河被淹死了!”小马又问小狗,小狗说:“挺深的,我好不容易才游过去的。”小马又去问黄牛。
黄牛笑着说:“要布洛芬吗?”
主动的科普做不到事无巨细地把所有细节、可能性都写出来。用户有个性化的问题,在科普文章中找不到答案,可以选择使用付费线上问诊服务,直接找个医生问。当问诊结束后,问诊记录会默认保持保密状态。此时,如果你愿意,帮助那些遇到类似问题的人,可以将问题设置为公开。本次问诊记录将会隐去所有敏感信息后,进入搜索索引。通过用户检索,数据将展示在「公开问题」栏目。
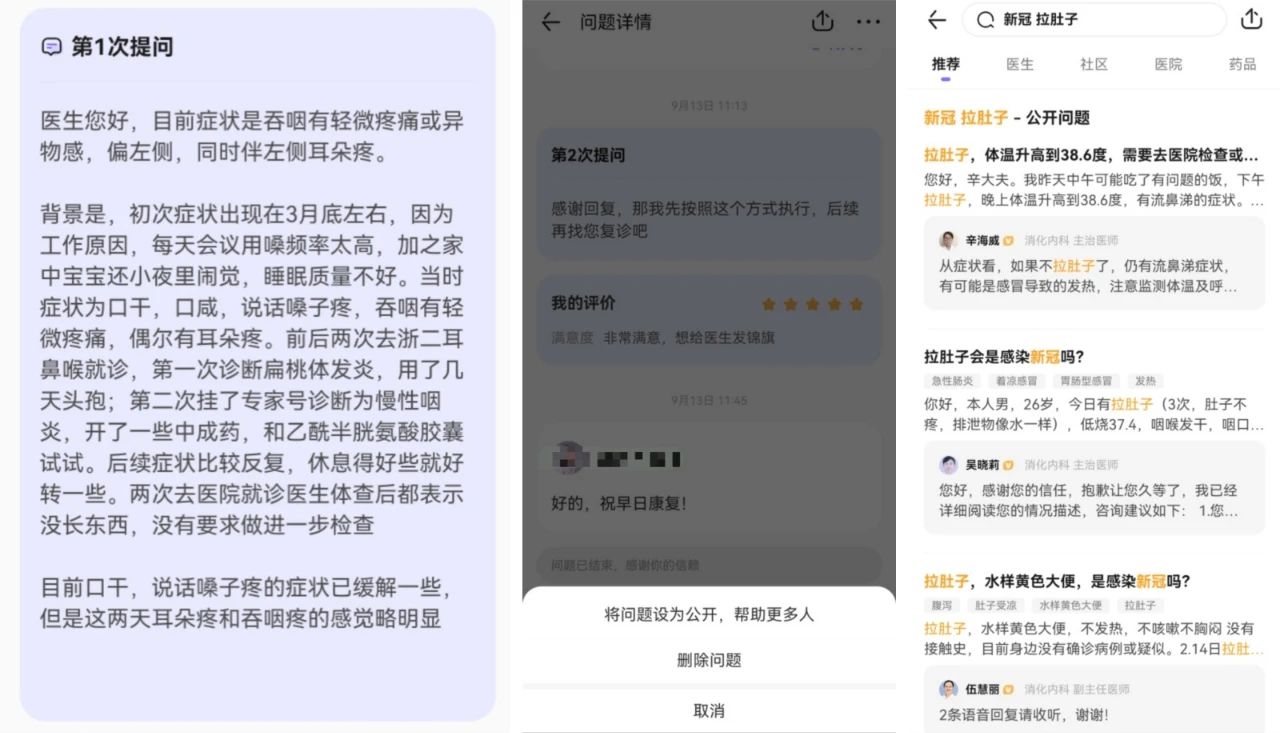
接触过信息检索的同学一定都有体会,要提升搜索效果,一方面要在语义匹配上下功夫,另一方面也要尽可能提升原始数据的结构化程度。眼尖的同学肯定发现了,被公开的问诊记录已经被自动带上了标题。对于长文本检索来说,标题是个非常重要的索引字段,它包含了全文的核心主旨,不仅有利于文档与Query的语义匹配,同时对于用户阅读体验也更好。通常,文章标题都是由编辑同学起的,人有高度抽象的思维能力,可以做到复杂事物的总结归纳,理清楚最主要的脉络逻辑。在当前的场景中,我们希望模型也能具备类似的能力,即提炼出用户问诊主诉,并生成一个流畅通顺的问句。
在还是RNN-Seq2seq为主流架构的3年前,团队也在摘要生成方面做了不少尝试,当时的技术背景下,我们大多探索的方向是在如何在结构上加些trick,提升长文的编码能力。或是各种结合copy机制,来提升关键信息的识别,引入外部知识实体数据等方向。但是,由于受限于主体encoder的编码能力,最终结果总是差强人意,虽然偶有让人眼前一亮的case,但是当时模型输出的稳定性还是不足以应用在实际场景中。
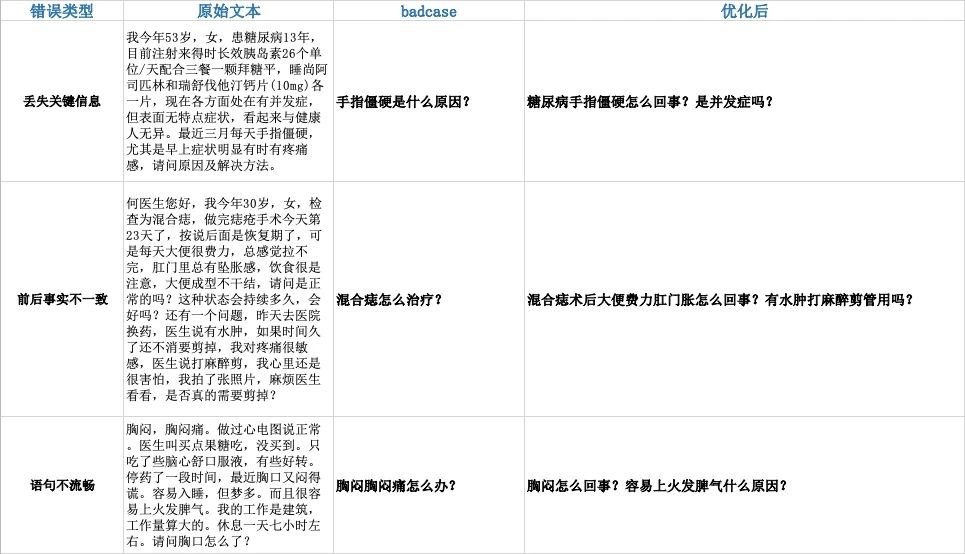
然而在随后的3年里,预训练模型迎来了爆发,在大模型的加持下,NLG的效果迅速提升至一个十分可观的水平。结合我们的任务,Google发布的T5成为了我们的基础框架。在经过几轮标注数据调教后,baseline版本已基本达到可读状态。但是在落地之前,还有几个问题需要解决,比如由于生成低资源导致的语句不流畅、生成句子前后事实不一致、输入文本过长等。
近几年,摘要生成也是NLP领域比较火热的一个方向,本文结合学界的几项工作,谈谈如何缓解上述问题的一些思路:
https://techbeat.net/article-info?id=4489
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢