
来自爱可可的前沿推介
Filtering, Distillation, and Hard Negatives for Vision-Language Pre-Training
F Radenovic, A Dubey, A Kadian, T Mihaylov, S Vandenhende, Y Patel, Y Wen, V Ramanathan, D Mahajan
[Meta AI]
面向视觉语言预训练的过滤、蒸馏和硬负样本
要点:
-
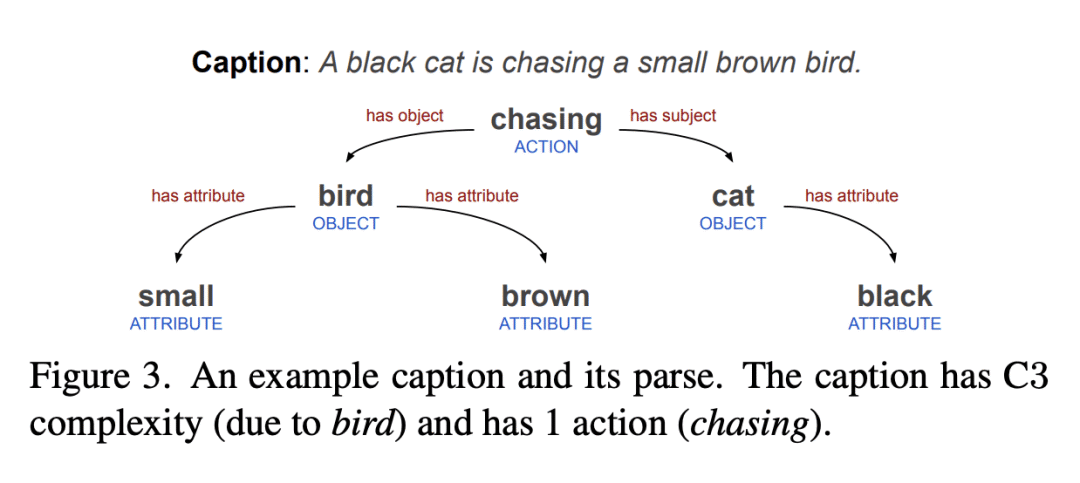
提出复杂度、动作和文本定位(Complexity, Action, and Text-spotting - CAT)数据集过滤策略,可以减少数据集大小,并提高零样本视觉-语言任务上的性能;
-
概念蒸馏是一种用强大的单模态表示进行对比训练的技术,不会增加训练复杂度;
-
提出一种重要性采样方法,用于对硬负样本进行上采样,作为对传统对比对齐目标的修改;
-
一种新的少样本线性探测方法弥合了零样本和少样本学习之间的差距。
一句话总结:
通过精心的数据集过滤和简单的建模改进,可以通过大规模预训练在检索和分类任务中实现零样本性能的显著提高。CAT 过滤可以应用于任意大规模数据集,概念蒸馏是利用大容量预训练图像模型进行多模态训练的计算和存储高效的方法,提出少样本线性探测方法比之前的工作有所改进。
摘要:
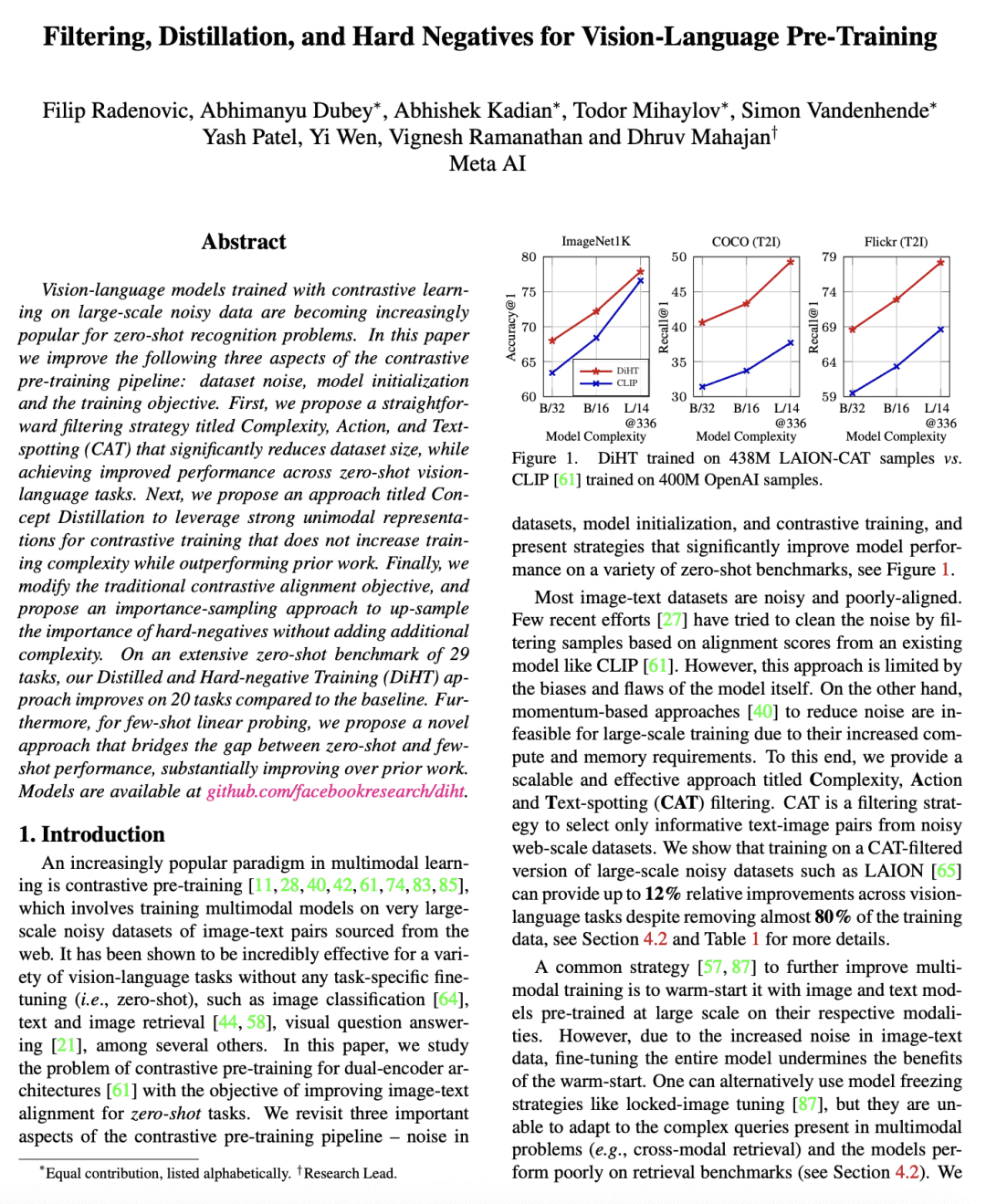
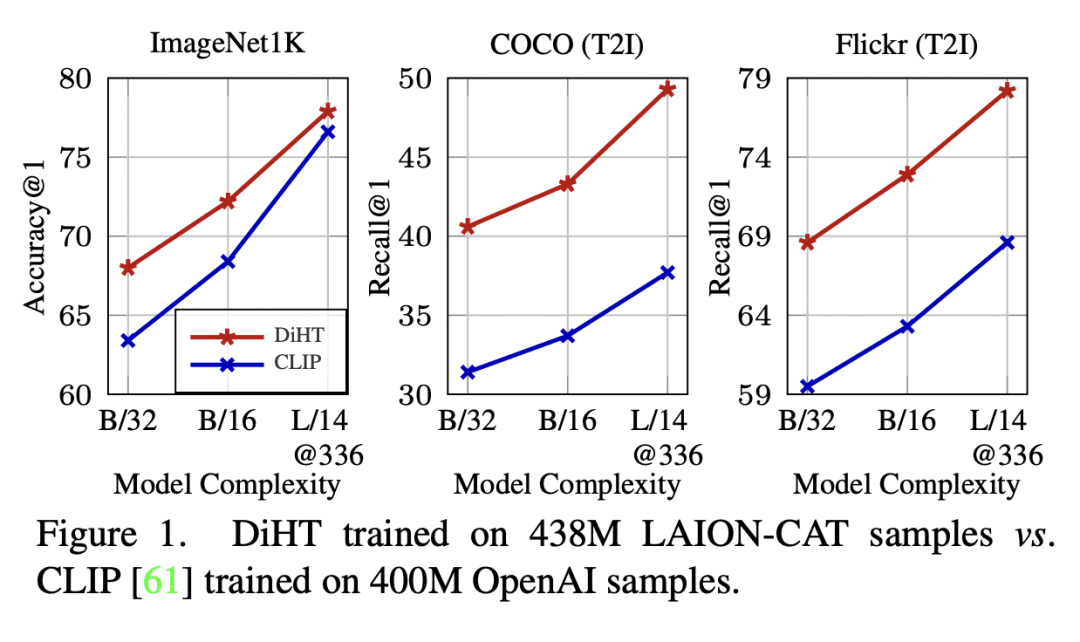
用大规模含噪数据对比学习训练的视觉-语言模型越来越受欢迎,用于零样本识别问题。本文改进了对比预训练流水线的以下三方面:数据集噪声、模型初始化和训练目标。本文提出一种简单的过滤策略,名为复杂度,动作和文本定位(CAT),它显著减少了数据集大小,同时在零样本视觉-语言任务中实现了性能改进。本文提出一种名为概念蒸馏的方法,利用强大的单模态表示进行对比训练,在性能优于之前工作的同时不会增加训练复杂度。本文修改了传统的对比对齐目标,并提出一种重要性采样方法,用于对硬负样本进行上采样,而不会增加额外的复杂度。在29项任务的广泛零样本基准测试中,所提出的蒸馏和硬负训练(DiHT)方法相比基线在20项任务中取得了改进。此外,对于少样本线性探测,本文提出一种新的方法,该方法弥合了零样本和少样本性能之间的差距,大大改善了之前的工作。
论文地址:https://arxiv.org/abs/2301.02280
Vision-language models trained with contrastive learning on large-scale noisy data are becoming increasingly popular for zero-shot recognition problems. In this paper we improve the following three aspects of the contrastive pre-training pipeline: dataset noise, model initialization and the training objective. First, we propose a straightforward filtering strategy titled Complexity, Action, and Text-spotting (CAT) that significantly reduces dataset size, while achieving improved performance across zero-shot vision-language tasks. Next, we propose an approach titled Concept Distillation to leverage strong unimodal representations for contrastive training that does not increase training complexity while outperforming prior work. Finally, we modify the traditional contrastive alignment objective, and propose an importance-sampling approach to up-sample the importance of hard-negatives without adding additional complexity. On an extensive zero-shot benchmark of 29 tasks, our Distilled and Hard-negative Training (DiHT) approach improves on 20 tasks compared to the baseline. Furthermore, for few-shot linear probing, we propose a novel approach that bridges the gap between zero-shot and few-shot performance, substantially improving over prior work. Models are available at this https URL.

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢