今天向大家推荐四篇近期发布的文献综述,包含无监督域适应、人体解析、视频异常检测和水果成熟度分类。
▌Source-Free Unsupervised Domain Adaptation: A Survey

通过深度学习的无监督域适应(UDA)来解决由不同域的分布差异引起的域迁移问题。现有的 UDA 方法高度依赖于源域数据的可及性,由于隐私保护、数据存储和传输成本以及计算负担等原因,在实际应用场景中通常是有限的。
为了解决这个问题,业界近期提出了许多无源无监督域适应(SFUDA)的方法,这些方法在源数据不可访问的情况下,将知识从预先训练的源模型迁移到无标签的目标域。
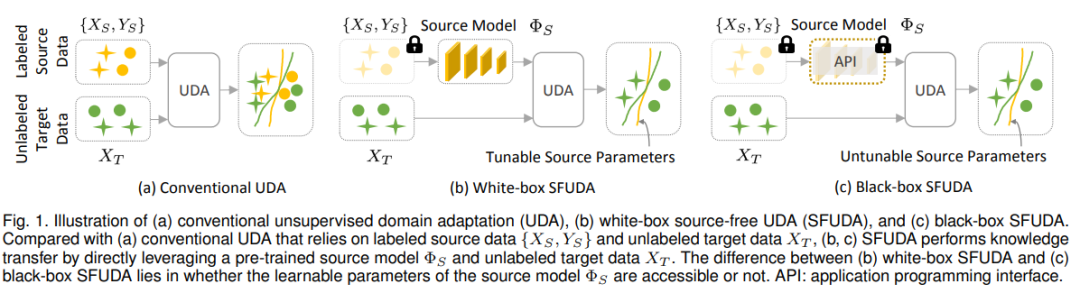
该综述从技术角度对现有的 SFUDA 方法进行了及时和系统的文献回顾。具体来说,作者将目前的 SFUDA 研究分为两类,即白盒 SFUDA 和黑盒 SFUDA,如图1所示。 并根据它们使用的不同学习策略进一步划分为更细的子类别。还研究了每个子类别中的方法所面临的挑战,以及白盒和黑盒 SFUDA 方法的优势/劣势,总结了常用的基准数据集,并总结了在不使用源数据的情况下提高模型泛化能力的流行技术。最后讨论了该领域几个有前途的未来方向。
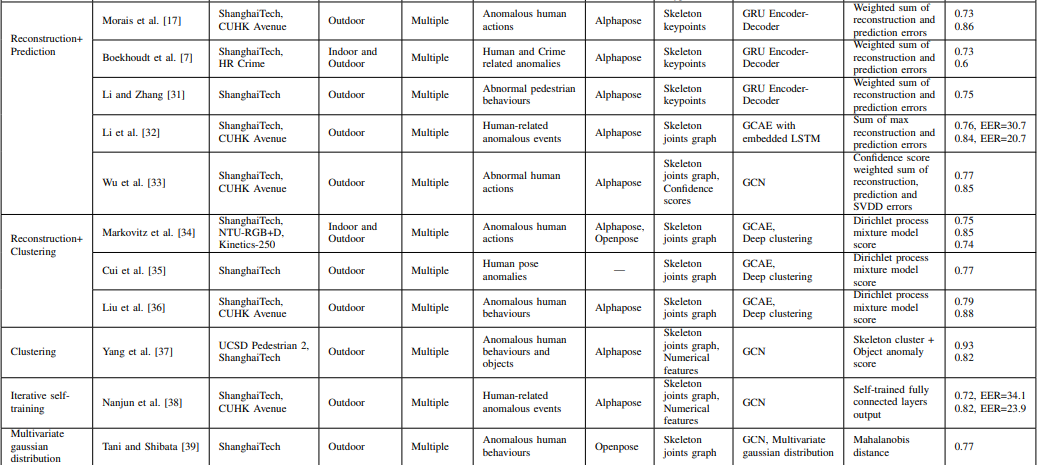
图1 (a)传统的无监督领域适应(UDA),(b)白盒无源UDA(SFUDA),和(c)黑盒SFUDA,
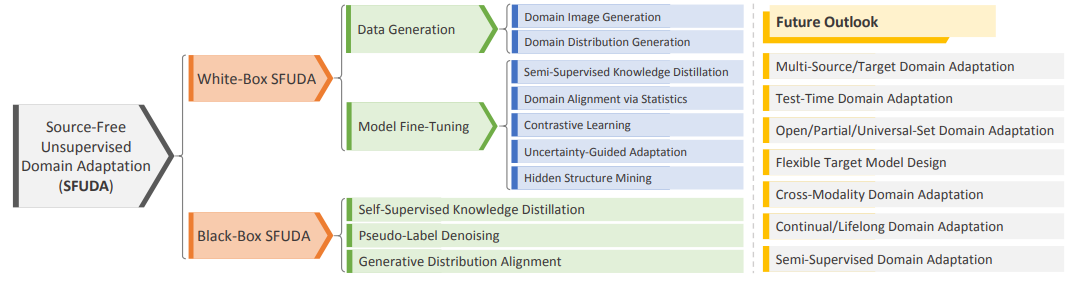
根据对源模型进行微调的不同策略,将现有的研究分为以下五个子类别:
图2 现有的无源无监督领域适应(SFUDA)方法的分类,以及未来展望
▌Deep Learning Technique for Human Parsing: A Survey and Outlook

人体解析的目的是将图像或视频中的人分割成多个像素级的语义部分。在过去的十年中,它在计算机视觉领域吸引了大量学者的研究兴趣,并在广泛的实际应用中得到了利用,如安全监控、社交媒体、视觉特效等等。尽管基于深度学习的人体解析解决方案已经取得了令人瞩目的成就,但许多重要的概念、现有的挑战和潜在的研究方向仍然是混乱的。
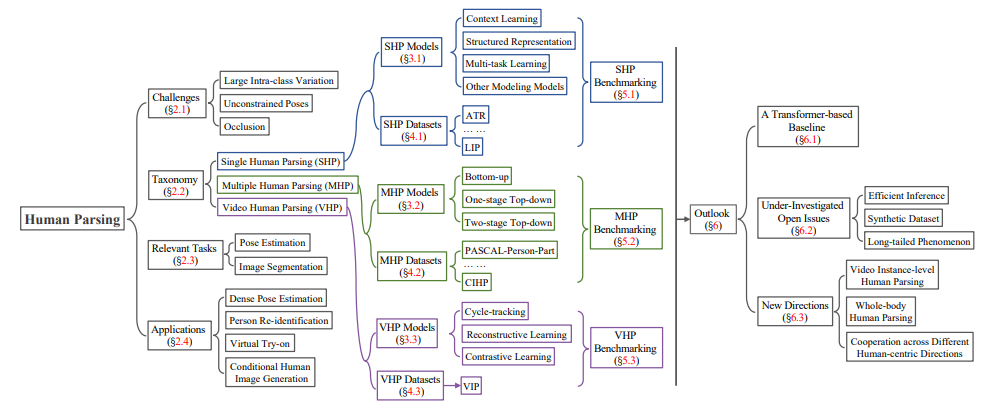
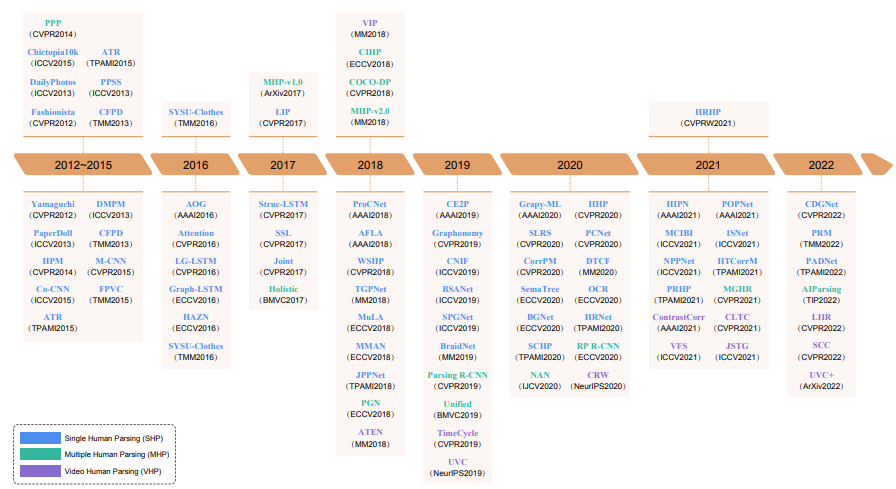
本篇综述通过介绍各自的任务设置、背景概念、相关问题和应用、代表性文献和数据集,全面回顾了三个核心子任务:Single human parsing (SHP)、Multiple human parsing (MHP) 和 Video human parsing (VHP),如图1所示。还介绍了这些方法在基准数据集上的定量性能比较。
此外,为了促进研究社区的可持续发展,作者还提出一个基于 transformer 的人体解析框架,如图6所示,通过通用的、简洁的和可扩展的解决方案为后续研究提供了一个高性能的基线。最后,指出了该领域中一系列未被充分研究的开放性问题,并提出了未来研究的新方向。
表一 2012年至2022年具有代表性的人体解析工作时间轴。上半部分代表人体解析的数据集,下半部分代表人体解析的模型
▌Skeletal Video Anomaly Detection using Deep Learning: Survey, Challenges and Future Directions

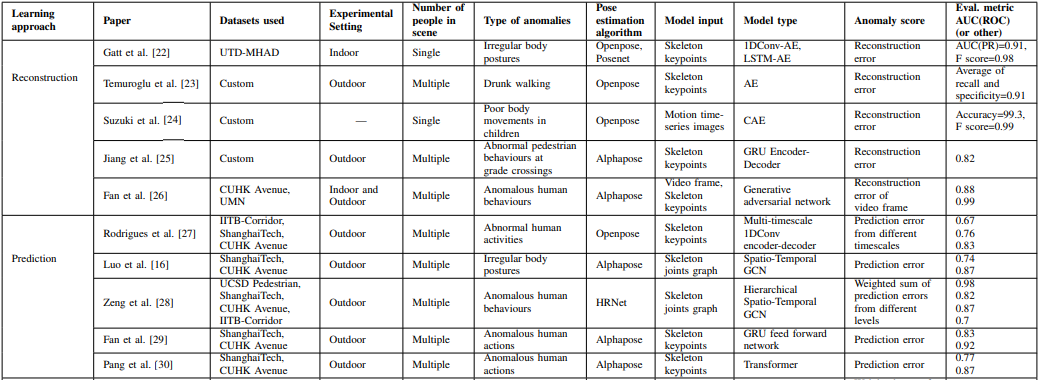
现有的视频异常检测方法大多利用含有可识别的人脸和外观特征的视频。其中使用含有可识别人脸的视频会引起隐私问题,特别是在医院或社区环境中使用时。而基于外观的特征也可能对基于像素的噪声很敏感,使异常检测方法对背景的变化进行建模,并使其难以关注前景中人类的行动。目前,以骨架形式描述视频中人类运动的结构信息的方法是保护隐私的,可以克服基于外观的特征所带来的一些问题。
本篇综述就对使用从视频中提取的骨架的隐私保护型深度学习异常检测方法进行了调研。并根据各种学习方法提出一个新的算法分类法。得到的结论是,基于骨架的异常检测方法可以成为视频异常检测中一个可信的保护隐私的选择。最后,确定了主要的开放式研究问题,并提供了解决这些问题的指南。
▌Fruit Ripeness Classification: a Survey

本篇综述对水果成熟度分类任务提供了一个广泛的全景图。更具体地说,文中提供了这一问题的正式定义和一个涉及水果成熟的生物过程的总结。然后,讨论了可用于表示水果属性的不同类型的描述符:color, light spectrum, fluorescence, spectral imaging。因此,被描述的属性可以由统计学、机器学习或深度学习模型来处理。此外,深度学习可以对原始数据进行操作,从而使用户不必计算特定水果的复杂的工程特征。本篇综述回顾了文献中提出的进行水果成熟度分类的最新的自动化方法,强调了它们所操作的最常见的特征描述符。
内容中包含的图片若涉及版权问题,请及时与我们联系删除



评论
沙发等你来抢