
来自今天的爱可可AI前沿推介
[LG] Reward is not Necessary: How to Create a Compositional Self-Preserving Agent for Life-Long Learning
T J. Ringstrom
[University of Minnesota]
奖励并非必要:创建终身学习的合成自保持智能体
要点:
-
提出一类新的贝尔曼方程,即算子贝尔曼方程(OBE),用于联合编码被正式表示为时间目标马尔可夫决策过程的联合非平稳和非马尔可夫任务; -
提出用内在动机函数,即效价函数,来量化遵循策略序列后激励的变化; -
自保持智能体(SPA)在计算规划时具有进行高级抽象符号推理的能力和终身学习能力,智能体会随着时间学习新的组合。
一句话总结:
自保持智能体(SPA)是一种基于生理学模型的智能体,通过算子贝尔曼方程(OBE)和价值函数,能在不使用奖励信号或奖励最大化作为目标的情况下实现自保持,还能进行符号推理并进行终身学习。
摘要:
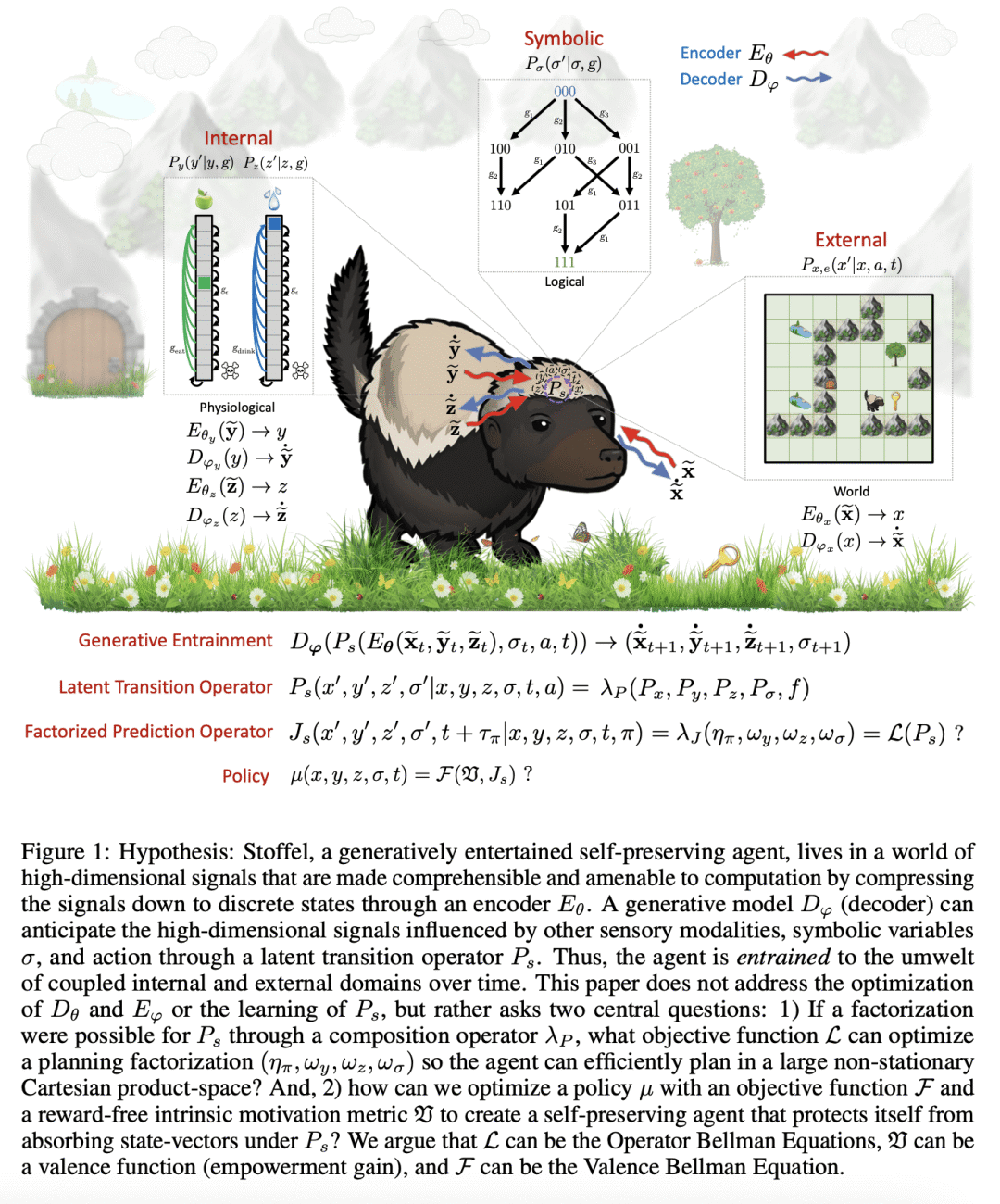
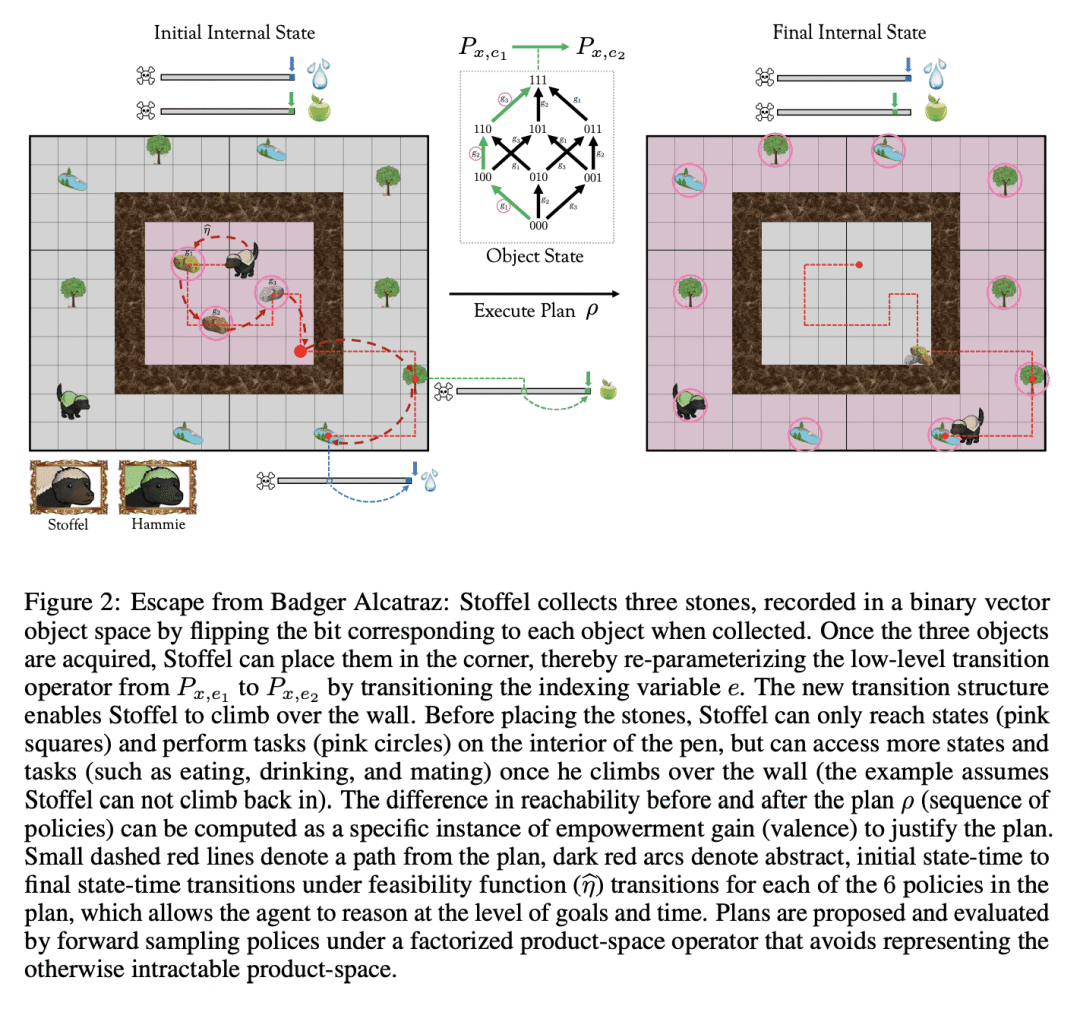
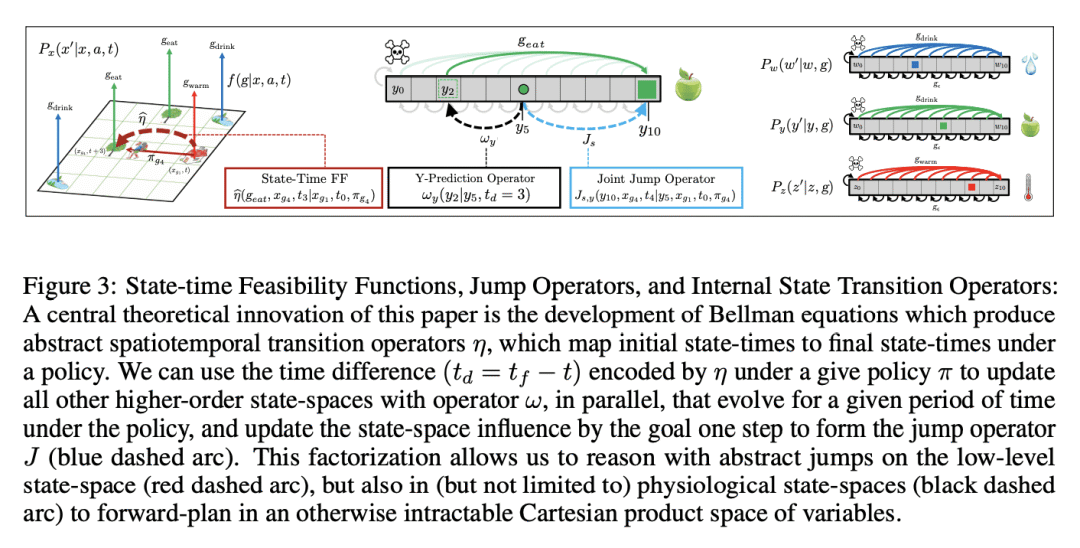
本文提出一种基于生理学模型的智能体,作为可以定义不使用奖励信号或奖励最大化作为目标的灵活自保持系统的证明。通过引入具有生理学结构的自保持智能体(SPA)实现了这一点,如果智能体不解决和执行针对目标的策略,系统就会陷入吸收状态。SPA采用一类新的贝尔曼方程来定义,这类方程称为算子贝尔曼方程(OBE),用于联合编码被正式表示为时间目标马尔可夫决策过程的非平稳和非马尔可夫任务。OBE 生成最优的目标条件时空迁移算子,将初始状态时映射到用于完成目标的策略的最终状态时,还可用于在多个动态生理学状态空间中预测未来状态。 SPA 配备了一种内在动机函数,即效价函数,用来量化遵循策略后激励(迁移算子的信道容量)的变化。因为激励是迁移算子的函数,所以激励和 OBE 之间存在自然的协同效应:OBE 创建分层迁移算子,效价函数可以评估这些算子上定义的分层激励变化。然后可以用效价函数进行目标选择,其中智能体选择实现产生最大激励收益的目标状态的策略序列。这样,智能体将寻求自由,避免破坏其未来对外部和内部状态的控制能力的内部死亡状态,从而展示出预测和预期自保持的能力。本文还将 SPA 与多目标强化学习进行比较,并讨论其符号推理和终身学习的能力。
We introduce a physiological model-based agent as proof-of-principle that it is possible to define a flexible self-preserving system that does not use a reward signal or reward-maximization as an objective. We achieve this by introducing the Self-Preserving Agent (SPA) with a physiological structure where the system can get trapped in an absorbing state if the agent does not solve and execute goal-directed polices. Our agent is defined using new class of Bellman equations called Operator Bellman Equations (OBEs), for encoding jointly non-stationary non-Markovian tasks formalized as a Temporal Goal Markov Decision Process (TGMDP). OBEs produce optimal goal-conditioned spatiotemporal transition operators that map an initial state-time to the final state-times of a policy used to complete a goal, and can also be used to forecast future states in multiple dynamic physiological state-spaces. SPA is equipped with an intrinsic motivation function called the valence function, which quantifies the changes in empowerment (the channel capacity of a transition operator) after following a policy. Because empowerment is a function of a transition operator, there is a natural synergism between empowerment and OBEs: the OBEs create hierarchical transition operators, and the valence function can evaluate hierarchical empowerment change defined on these operators. The valence function can then be used for goal selection, wherein the agent chooses a policy sequence that realizes goal states which produce maximum empowerment gain. In doing so, the agent will seek freedom and avoid internal death-states that undermine its ability to control both external and internal states in the future, thereby exhibiting the capacity of predictive and anticipatory self-preservation. We also compare SPA to Multi-objective RL, and discuss its capacity for symbolic reasoning and life-long learning.
论文链接:https://arxiv.org/abs/2211.10851
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢