
【标题】Muse: Text-To-Image Generation via Masked Generative Transformers
【作者团队】Huiwen Chang, Han Zhang, Jarred Barber, AJ Maschinot, Jose Lezama, Lu Jiang, Ming-Hsuan Yang, Kevin Murphy, William T. Freeman, Michael Rubinstein, Yuanzhen Li, Dilip Krishnan
【发表时间】2023/01/02
【机 构】谷歌
【论文链接】https://arxiv.org/pdf/2301.00704v1.pdf
【代码链接】http://muse-model.github.io
本文展示了 Muse,一种文本到图像的 Transformer 模型,它具有最先进的图像生成性能,同时比扩散或自回归模型效果更好。 Muse 在离散空间中进行掩码任务的训练,基于从预训练的大型语言模型中提取的文本嵌入,训练 Muse 以预测随机遮蔽的图像token。 与 Imagen 和 DALL-E 2 等像素空间扩散模型相比,Muse 使用离散token并且需要更少的采样迭代,效率显着提高。另外与 Parti 等自回归模型相比,Muse 由于使用了并行解码,因此效率更高。 使用预训练的语言模型可以实现细粒度的语言理解,转化为高保真图像生成和视觉概念的理解,例如对象、空间关系、姿势、基数等。本文的 900M 参数模型在 CC3M,FID 得分为 6.06, 3B 参数模型在零样本 COCO 评估中实现了 7.88 的 FID,以及 0.32 的 CLIP 分数。 Muse 还可以直接启用许多图像编辑应用程序,包括inpainting, outpainting等,而无需微调或反向模型。
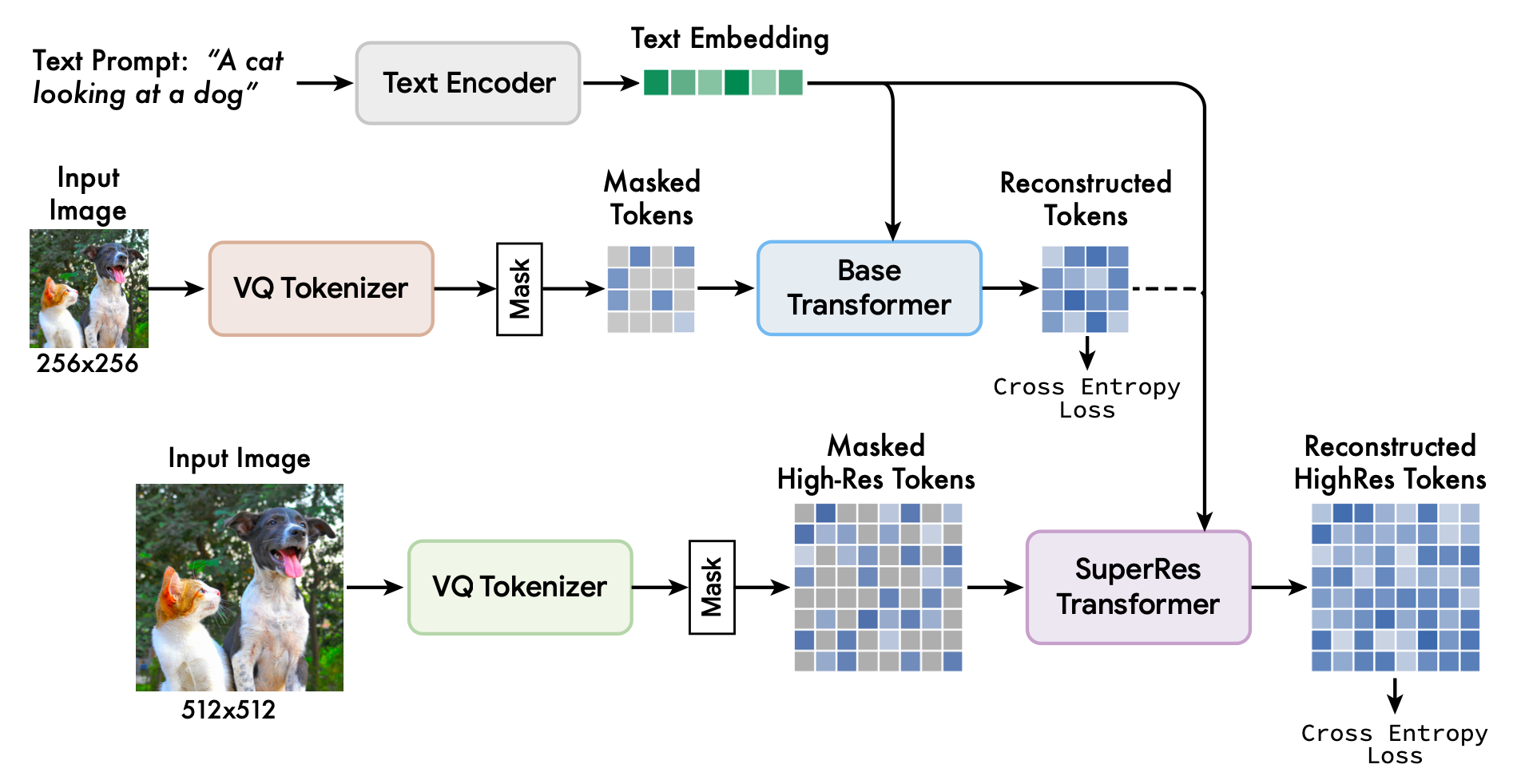
上图展示了Muse框架,包括在T5-XXL预训练的文本编码器、基础模型和超级分辨率模型。文本编码器生成一个文本嵌入,用于与基础和超分辨率Transformer层的图像tone进行交叉注意力计算。基础模型使用VQ tokenizer在较低分辨率(256×256)的图像上进行了预训练,并生成了16×16的隐空间。序列以可变速率被遮蔽,然后通过交叉熵损失学习预测被遮蔽的图像token。重建的低分辨率token和文本token就会被传递到超分辨率模型中,然后学习预测更高分辨率下的遮蔽token。
模型推理时间效率的关键部分是使用平行解码来预测单个前向通道中的多个输出token。平行解码有效性的关键假设是马尔可夫属性,即token是有条件地独立于其他token的。解码是根据cosine schedule进行的,该方法选择了一定的固定比例的最高置信度的掩码,在该步骤中进行预测。然后,这些token在剩余的步骤中被设定为未被遮蔽,被遮蔽的token集被适当减少。使用这个方法,本文能够在基础模型中只用24个解码步骤对256个token进行推理,在超级分辨率模型中用8个解码步骤对4096个token进行推理,而自回归模型需要对应256或4096个步骤,扩散模需要数百个步骤。
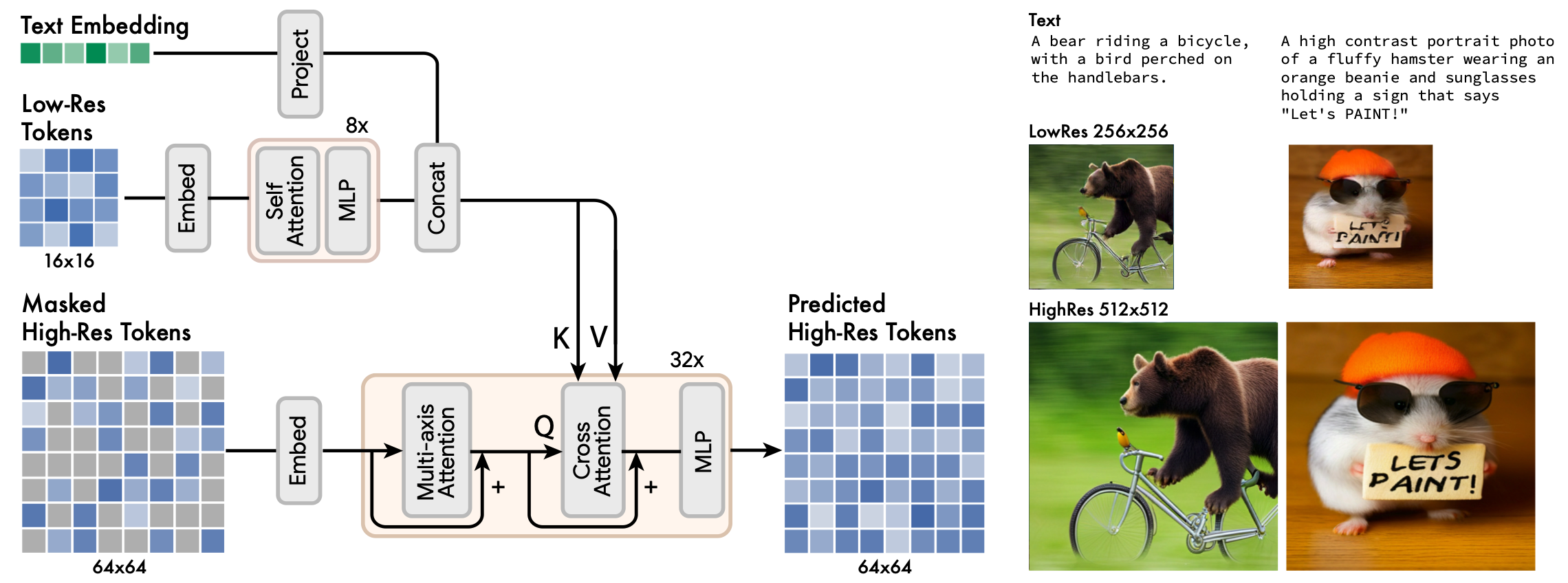
上图展示了以低分辨率和文本token为条件超级分辨率模型的架构,以及超分辨率模型带来的改进的两个例子。
本文发现,直接预测512×512的分辨率会导致模型专注于低层次的细节而不是大规模的语义。因此使用一个级联模型是有益的:首先是一个生成16×16潜像图(对应256×256的图像)的基础模型,然后是一个超级分辨率模型,将基础潜像图上采样为64×64潜像图(对应512×512的图像)。超级分辨率模型是在基础模型训练完成后进行训练的。
本文的基础模型是一个遮蔽transformer,其中输入是预测的T5嵌入和图像token。这里不对所有文本嵌入进行遮蔽,并随机屏蔽一部分不同的图像token,用一个特殊的掩码token代替它们。然后将图像token线性地映射到所需的Transformer输入/隐藏大小的图像输入嵌入中,同时学习二维位置嵌入。transformer架构,包括自注意力层、交叉注意力和MLP来提取特征。在输出层,MLP被用来将每个遮蔽的图像嵌入转换为一组对数,并应用交叉熵损失训练。然而,对于推理来说,遮蔽预测是以迭代的方式进行的,这大大提高了质量。
低分辨率的token被传递到一系列的自注意力Transformer层中,由此产生的输出嵌入与从条件文本提示中提取的文本嵌入相连接。在这之后,交叉注意力从这些连接的嵌入应用到被遮蔽的高分辨率token,并通过损失函数学习预测这些被遮蔽的token。超级分辨率模型学会了将低分辨率的隐空间"翻译 "成高分辨率的隐空间,然后通过高分辨率的VQGAN进行解码,得到最终的高分辨率图像。

上图展示了使用Muse的图像编辑实例。这些实例是在真实的输入图像上进行的,没有进行微调,所有编辑过的图像都是以512×512的分辨率生成的。
以inpainting和outpainting为例,将输入图像转换为一组token,遮蔽掉对应于局部区域的token,然后以未遮蔽的token和文本提示为条件,对遮蔽的token进行采样。在采样过程中为对应token遮蔽出适当的区域,使用平行采样算法对低分辨率的token进行遮蔽。最后以这些低分辨率的token为条件,用同样的抽样算法对高分辨率的token进行采样。
创新点
1. 本文提出了一个最先进的文本-图像生成模型,它取得了出色的FID和CLIP分数(图像生成质量、多样性和与文本提示的一致性的定量测量)。
2. 由于使用了量化的图像token和并行解码,本文的模型明显比同类模型快。
3. 本文的架构实现了开箱即用的零样本编辑功能,包括inpainting, outpainting等。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢