
来自爱可可的前沿推介
论文:Optimistic Meta-Gradients/乐观元梯度
链接: https://arxiv.org/abs/2301.03236
作者:S Flennerhag, T Zahavy, B O'Donoghue, H v Hasselt, A György, S Singh
[DeepMind]
要点:
-
证明了基于梯度的元学习与凸优化之间的联系;
-
证明了单任务设置下元学习的收敛速度;
-
证明了元学习中需要乐观才能实现加速;
-
为 Bootstrapped Meta-Gradients(BMG) 方法提供了第一个收敛证明。
一句话总结
研究了凸优化与元学习之间的关系,证明了元学习中需要乐观才能实现加速,为 BMG 方法提供了第一个收敛证明。
摘要
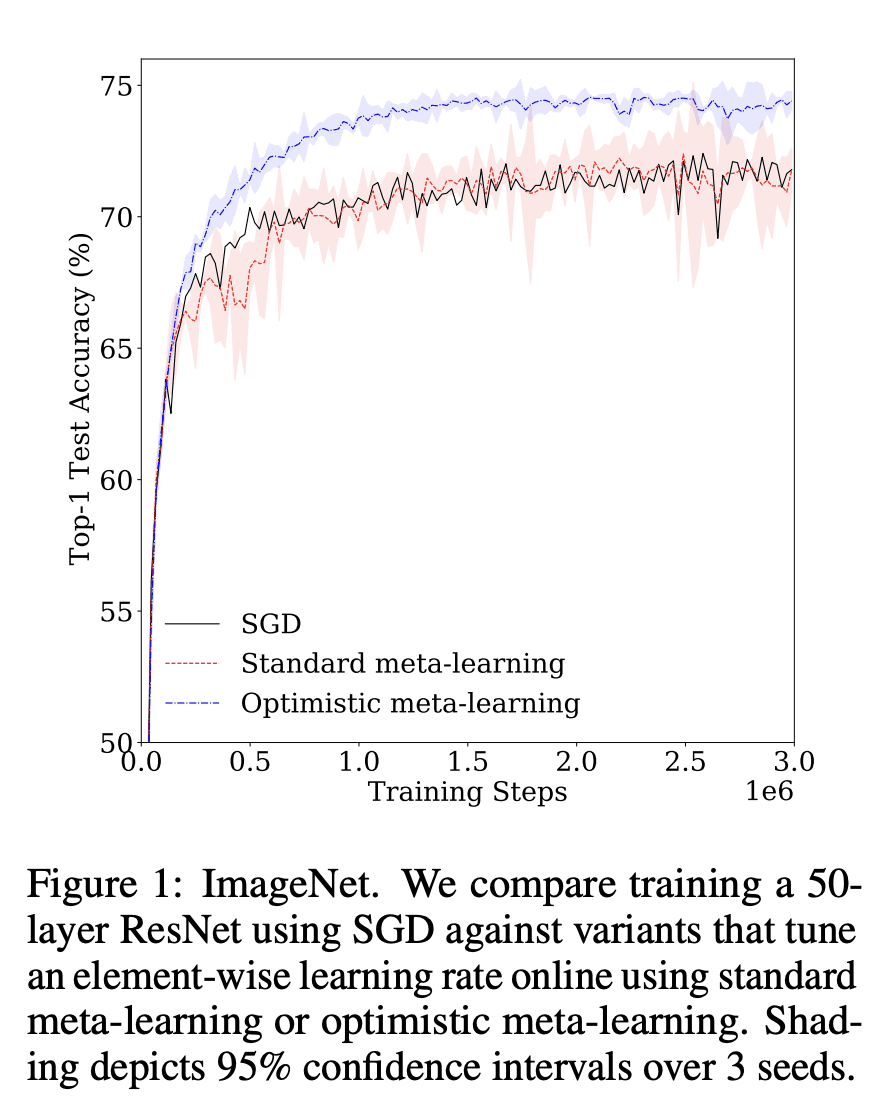
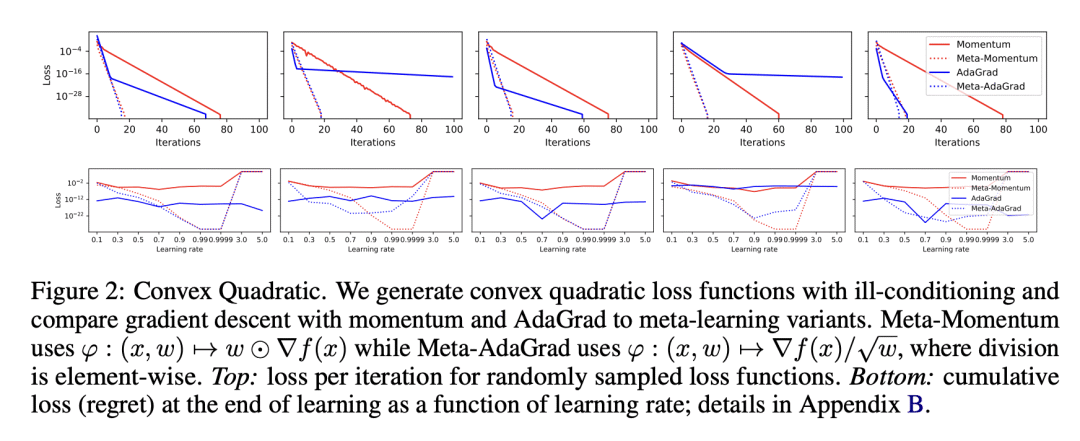
本文研究了基于梯度的元学习与凸优化之间的联系。基于动量的梯度下降是元梯度的一种特例,基于最近的优化结果,本文证明了单任务设置下元学习的收敛速度。虽然元学习更新规则可以在常数因子范围内提供更快的收敛,但这还不足以实现加速。相反,需要某种形式的乐观。本文表明,通过 Bootstrapped Meta-Gradients(BMG) 可以捕获元学习中的乐观,提供了对其内在机制的更深入的见解。
We study the connection between gradient-based meta-learning and convex op-timisation. We observe that gradient descent with momentum is a special case of meta-gradients, and building on recent results in optimisation, we prove convergence rates for meta-learning in the single task setting. While a meta-learned update rule can yield faster convergence up to constant factor, it is not sufficient for acceleration. Instead, some form of optimism is required. We show that optimism in meta-learning can be captured through Bootstrapped Meta-Gradients (Flennerhag et al., 2022), providing deeper insight into its underlying mechanics.
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢