
来自今天的爱可可AI前沿推介
[CL] Why do Nearest Neighbor Language Models Work?
F F. Xu, U Alon, G Neubig
[CMU]
结合最近邻(检索)的语言模型为何有效?
要点:
-
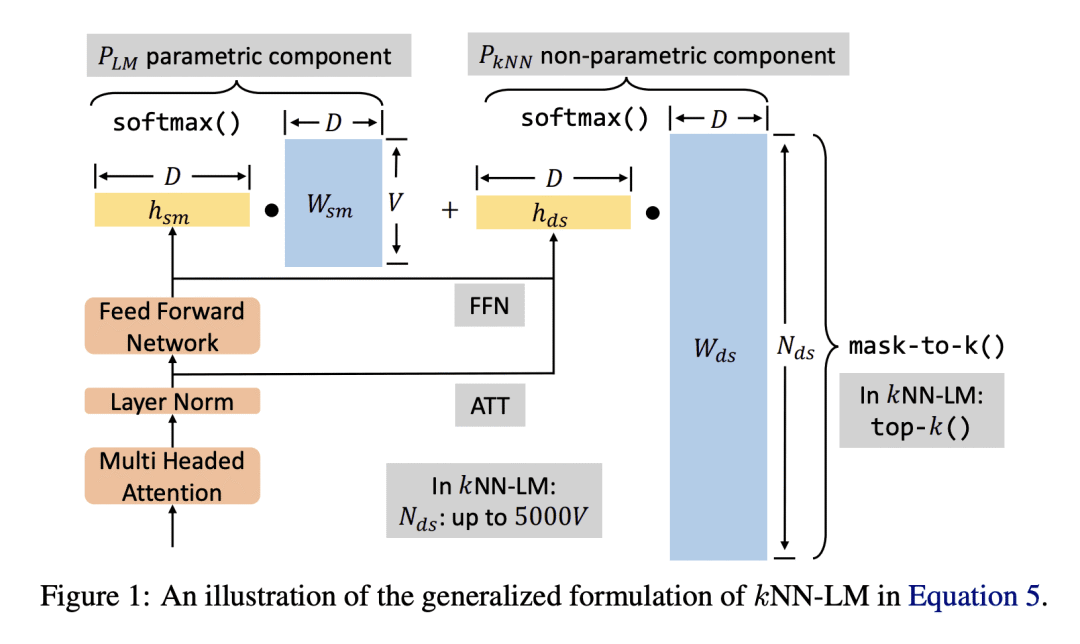
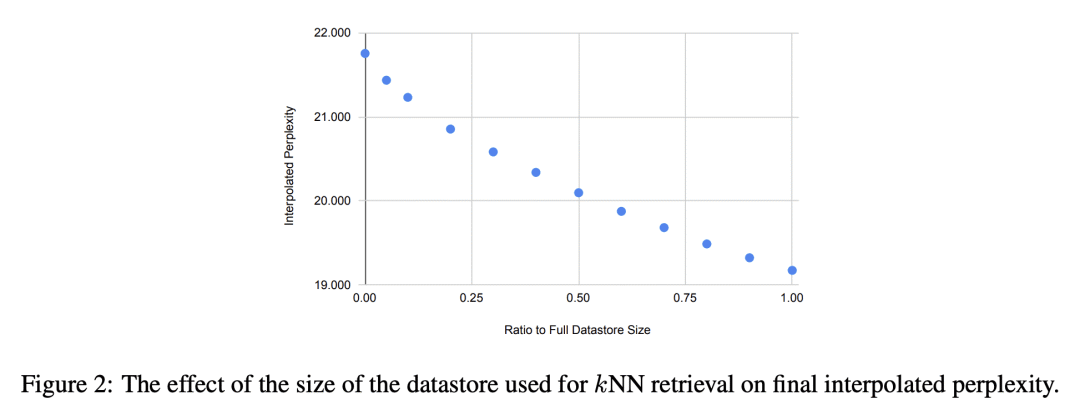
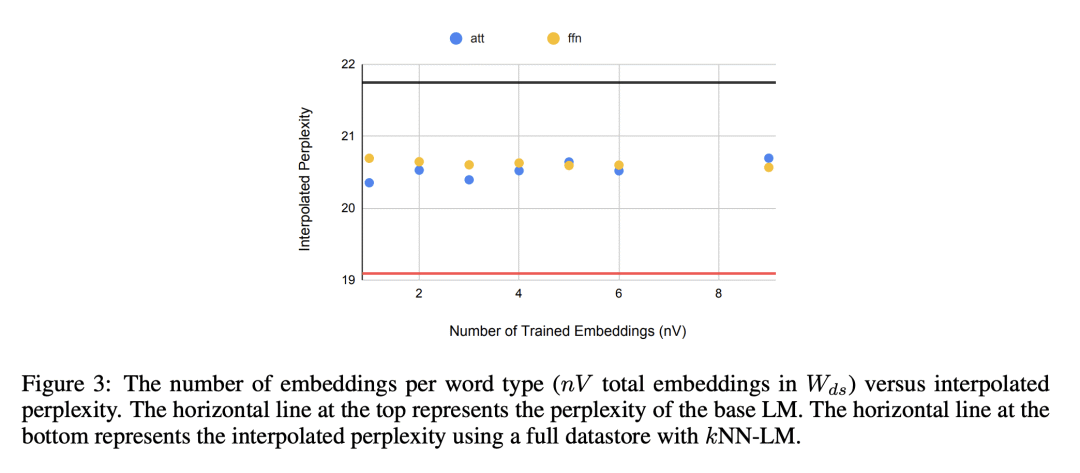
确定了 k-近邻语言模型(kNN-LM)优于标准参数语言模型的三个主要原因:不同的输入表示,近似 k-NN 搜索和 k-NN 分布的softmax温度的重要性; -
证明这些见解可以被纳入标准参数语言模型的体系结构或训练过程中,以提高其性能而无需显式的检索组件; -
探究了 k-NN-LM 性能和效率之间的权衡,提出一种矩阵运算,可以代替kNN搜索,同时保留超过一半的困惑度改进。
一句话总结:
彻底调查了 k-NN-LM 为什么在检索基础语言模型训练所用的相同训练数据的样本时,也能提高困惑度,并确定三方面主要因素对其成功至关重要。探究了 k-NN-LM 性能和效率之间的权衡,提出一种解决方案,在保持性能的同时提高效率。
摘要:
语言模型(LM)通过逐步计算已看到的上下文的表示,来计算文本的概率,并使用该表示来预测下一词。目前,大多数 LM 会利用紧挨着的上个上下文的神经网络来计算这些表示。然而,最近的检索增强 LM 已经显示出在标准神经LM的基础上有所改进,通过除了标准参数预测之外,还从大型数据存储器中获取信息来实现。本文开始理解为什么检索增强语言模型,特别是为什么k-NN语言模型(kNN-LM)比标准参数 LM 更好,即使 k-NN 组件从LM最初训练的相同训练集中检索样本时也是如此。为了达到这一目的,本文仔细分析了 kNN-LM 与标准 LM 不同的各个维度,并一一调查这些维度。在经验上,确定了 kNN-LM 比标准 LM 更好的三个主要原因:使用不同的输入表示来预测下一 Token,近似 kNN 搜索和 kNN 分布的 softmax 温度的重要性。本文将这些见解纳入标准参数 LM 的模型架构或训练过程中,在不需要显式的检索组件的情况下改善了结果。
Language models (LMs) compute the probability of a text by sequentially computing a representation of an already-seen context and using this representation to predict the next word. Currently, most LMs calculate these representations through a neural network consuming the immediate previous context. However recently, retrieval-augmented LMs have shown to improve over standard neural LMs, by accessing information retrieved from a large datastore, in addition to their standard, parametric, next-word prediction. In this paper, we set out to understand why retrieval-augmented language models, and specifically why k-nearest neighbor language models (kNN-LMs) perform better than standard parametric LMs, even when the k-nearest neighbor component retrieves examples from the same training set that the LM was originally trained on. To this end, we perform a careful analysis of the various dimensions over which kNN-LM diverges from standard LMs, and investigate these dimensions one by one. Empirically, we identify three main reasons why kNN-LM performs better than standard LMs: using a different input representation for predicting the next tokens, approximate kNN search, and the importance of softmax temperature for the kNN distribution. Further, we incorporate these insights into the model architecture or the training procedure of the standard parametric LM, improving its results without the need for an explicit retrieval component. The code is available at this https URL.
论文链接:https://arxiv.org/abs/2301.02828
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢