
来自今天的爱可可AI前沿推介
[CV] Diffused Heads: Diffusion Models Beat GANs on Talking-Face Generation
M Stypułkowski, K Vougioukas...
[University of Wrocław & Imperial College London & Wrocław University of Science and Technology]
Diffused Heads: 超越GAN的说话脸生成扩散模型
要点:
-
提出 Diffused Heads,基于扩散模型的说话脸生成方案 ; -
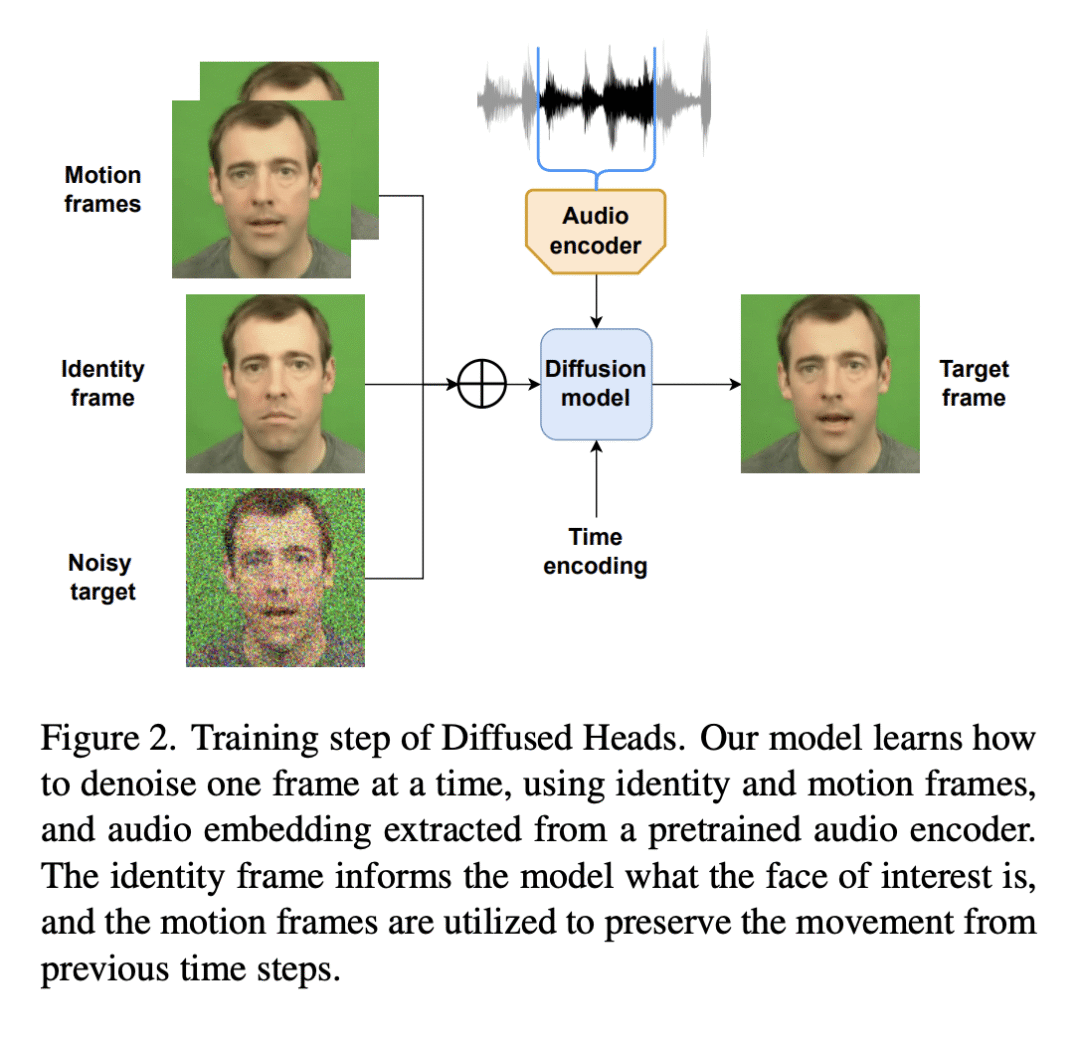
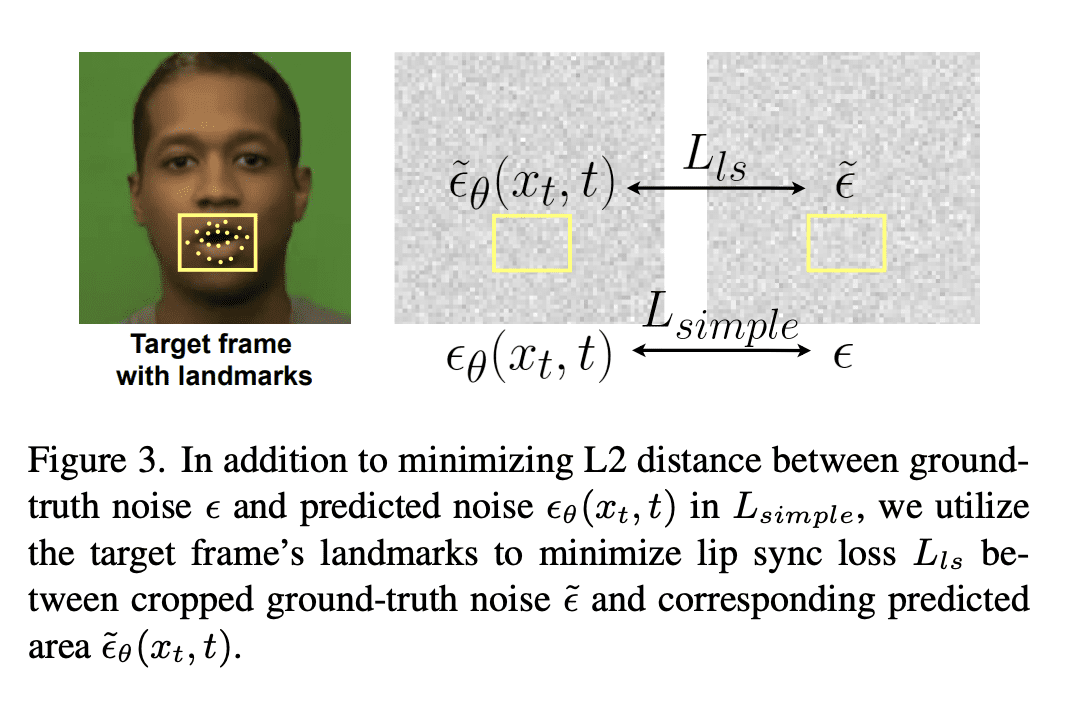
用运动帧和音频嵌入丰富了扩散模型,以保持生成图像的一致性; -
该方法在泛化方面是鲁棒的,在身份帧和录音的源上是不变的。
一句话总结:
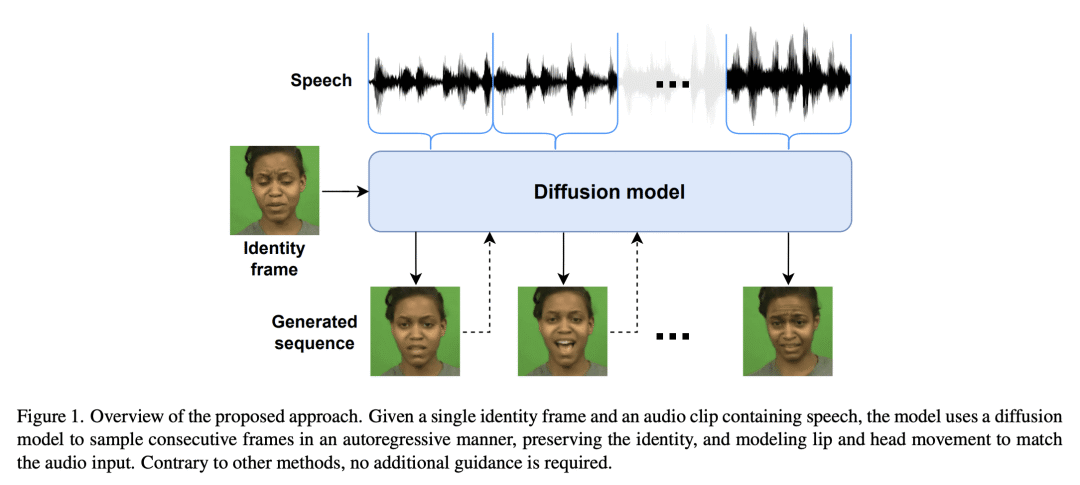
提出 Diffused Heads,一种基于帧的说话脸生成方法,可用于合成难辨真假的视频,只需要一个身份帧和包含语音的音频序列。
摘要:
在缺少其他参考视频指导的情况下,说话脸生成很难产生头部动作和自然的面部表情。基于扩散的生成模型的最新发展允许更现实和稳定的数据合成,在图像和视频生成方面的性能超过了其他生成模型。本文提出一种自回归扩散模型,只需要一个身份图像和音频序列,即可生成一个逼真的说话头部视频。该解决方案能产生头部运动、眨眼等面部表情,并保留给定的背景。在两个不同的数据集上评估该模型,在两个数据集上都取得了最先进的结果。
Talking face generation has historically struggled to produce head movements and natural facial expressions without guidance from additional reference videos. Recent developments in diffusion-based generative models allow for more realistic and stable data synthesis and their performance on image and video generation has surpassed that of other generative models. In this work, we present an autoregressive diffusion model that requires only one identity image and audio sequence to generate a video of a realistic talking human head. Our solution is capable of hallucinating head movements, facial expressions, such as blinks, and preserving a given background. We evaluate our model on two different datasets, achieving state-of-the-art results on both of them.
论文链接:https://arxiv.org/abs/2301.03396
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢