
Title: Rethinking Mobile Block for Efficient Neural Models
Author:Jiangning Zhang et al. (腾讯优图、浙大、北大、武大)
Paper: https://arxiv.org/pdf/2301.01146
Github: https://github.com/zhangzjn/EMO
引言
本文重新思考了 MobileNetv2 中高效的倒残差模块 Inverted Residual Block 和 ViT 中的有效 Transformer 的本质统一,归纳抽象了 MetaMobile Block 的一般概念。受这种现象的启发,作者设计了一种面向移动端应用的简单而高效的现代反向残差移动模块 (Inverted Residual Mobile Block, iRMB),它吸收了类似 CNN 的效率来模拟短距离依赖和类似 Transformer 的动态建模能力来学习长距离交互。所提出的高效模型 (Efficient MOdel, EMO) 在 ImageNet-1K、COCO2017 和 ADE20K 基准上获取了优异的综合性能,超过了同等算力量级下基于 CNN/Transformer 的 SOTA 模型,同时很好地权衡模型的准确性和效率。
动机
近年来,随着对存储和计算资源受限的移动应用程序需求的增加,涌现了非常多参数少、FLOPs 低的轻量级模型,例如 Inceptionv3 时期便提出了使用非对称卷积代替标准卷积。后来 MobileNet 提出了深度可分离卷积 depth-wise separable convolution 以显着减少计算量和参数,一度成为了轻量化网络的经典之作。在此基础上,MobileNetv2 提出了一种基于 Depth-Wise Convolution (DW-Conv) 的高效倒置残差块(IRB),更是成为标准的高效模块代表作之一。然而,受限于静态 CNN 的归纳偏差影响,纯 CNN 模型的准确性仍然保持较低水平,以致于后续的轻量化之路并没有涌现出真正意义上的突破性工作。
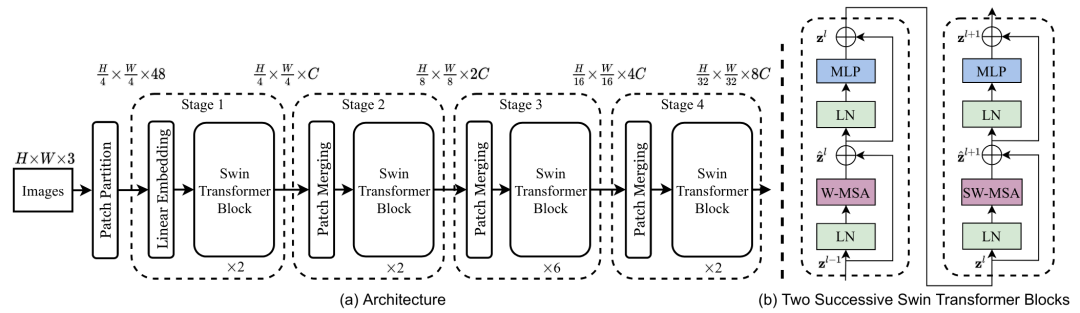
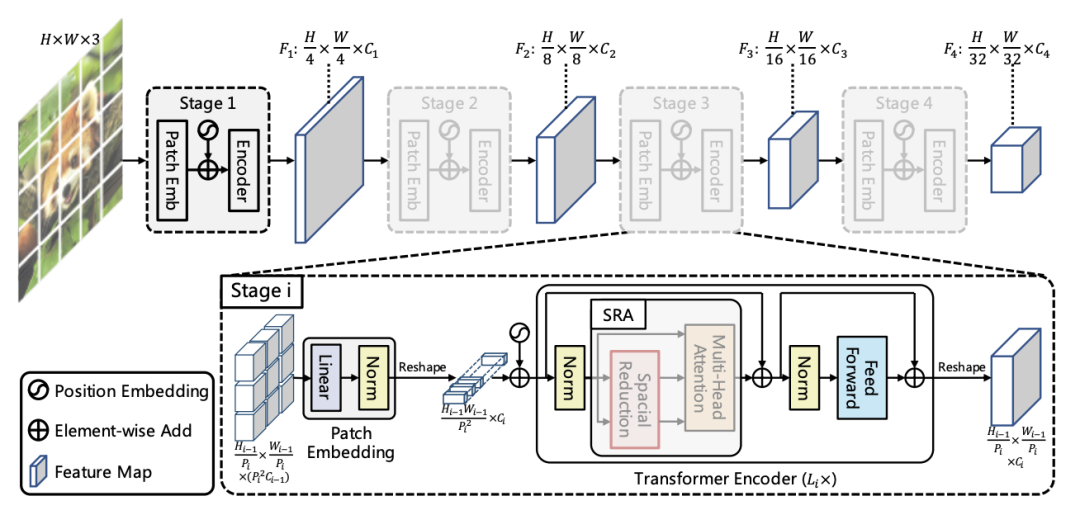
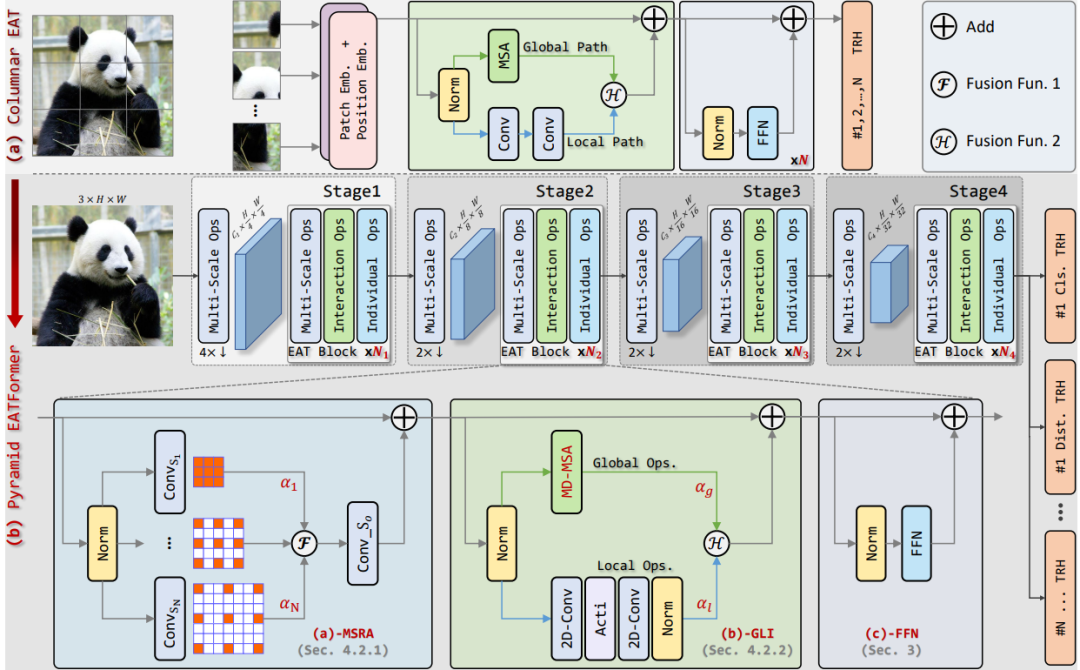
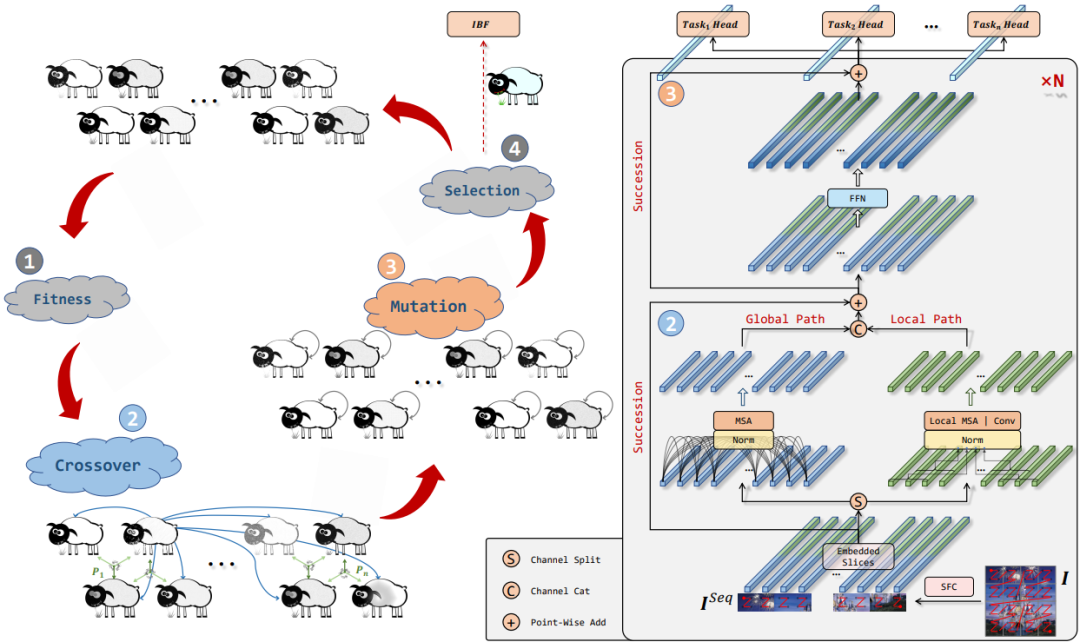
随着 Transformer 在 CV 领域的崛起,一时间涌现了许多性能性能超群的网络,如 Swin transformer、PVT、Eatformer、EAT等。得益于其动态建模和不受归纳偏置的影响,这些方法都取得了相对 CNN 的显着改进。然而,受多头自注意(MHSA)参数和计算量的二次方限制,基于 Transformer 的模型往往具有大量资源消耗,因此也一直被吐槽落地很鸡肋。
针对 Transformer 的这个弊端,当然也提出了一些解决方案:
-
设计具有线性复杂性的变体,如FAVOR+和Reformer等; -
降低查询/值特征的空间分辨率,如Next-vit、PVT、Cvt等; -
重新排列通道比率来降低 MHSA 的复杂性,如Delight;
不过这种小修小改还是难成气候,以致于后续也出现了许多结合轻量级 CNN 设计高效的混合模型,并在准确性、参数和 FLOPs 方面获得比基于 CNN 的模型更好的性能,例如Mobilevit、MobileViTv2和Mobilevitv3等。然而,这些方法通常也会引入复杂的结构,或者更甚者直接采用多个混合的模块如Edgenext和Edgevits,这其实是不利于优化的。
总而言之,目前没有任何基于 Transformer 或混合的高效块像基于 CNN 的 IRB 那样流行。因此,受此启发,作者重新考虑了 MobileNetv2 中的 Inverted Residual Block 和 Transformer 中的 MHSA/FFN 模块,归纳抽象出一个通用的 Meta Mobile Block,它采用参数扩展比 λ 和高效算子 F 来实例化不同的模块,即 IRB、MHSA 和前馈网络 (FFN)。
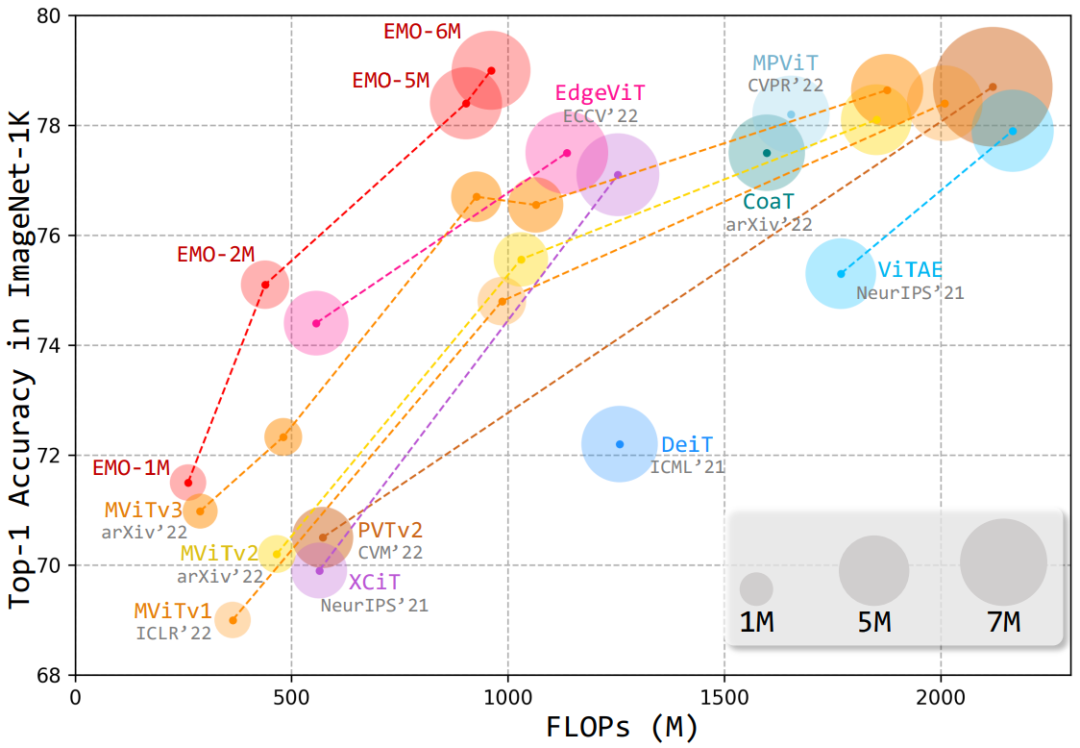
基于此,本文提出了一种简单高效的模块——反向残差移动块(iRMB),通过堆叠不同层级的 iRMB,进而设计了一个面向移动端的轻量化网络模型——EMO,它能够以相对较低的参数和 FLOPs 超越了基于 CNN/Transformer 的 SOTA 模型,如下图所示:
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢