
BERT、GPT3 等预训练语言大模型已经被证明在 NLP 领域可以取得非常好的效果。随着近两年多模态领域的研究逐渐成熟,越来越多的研究者开始关注多模态预训练大模型,例如最初的 ViLBERT 以及后来 OpenAI 提出的 CLIP,再到近期可以以统一范式支持各种模态任务的 OFA,它们都在各种模态的下游任务中取得了相当不错的效果。
但是,前沿开源大模型在工业界应用中存在诸多挑战,例如语言不匹配、领域契合度低、任务有差异等。今天分享的主题是多模态预训练模型的轻量适配技术探索。
-
多模态大模型现状与应用挑战 -
多模态大模型的语言适配 -
多模态大模型的领域适配 -
多模态大模型的优化目标适配 -
应用案例
01
多模态大模型现状与应用挑战
首先和大家分享下多模态大模型现状与应用挑战。
近年来多模态开源预训练大模型在各式各样的下游任务中都取得了不错的效果,这使得业界都开始尝试将这些大模型应用都自己的业务场景中。以 CLIP 为例,目前已经出现了针对各种下游场景的模型变式,使 CLIP 可以适用于一个具体任务中。
目前,前沿开源多模态预训练大模型在工业界应用存在以下三个挑战:
-
开源大模型与应用任务的语言不匹配,无法直接应用
-
开源大模型与应用任务领域契合度低(例如通用大模型难以直接应用到电商等下游任务),难以带来明显效果
-
开源大模型的优化目标与应用任务有差异,需要较多下游标注数据

针对上述三个问题,接下来分享的内容也将分为三大命题,介绍开源多模态预训练大模型的适配技术:
-
开源大模型的语言适配技术,解决大模型与应用场景语言不一致问题
-
开源大模型的领域适配技术,解决大模型与应用场景领域契合度低的问题
-
开源大模型的优化目标适配技术,解决大模型的优化目标与应用任务有差异的问题
02
多模态大模型的语言适配
先和大家分享多模态大模型的语言适配技术。

学术界的多模态大模型,例如 CLIP、OFA 等都是面向英语场景的,而它们难以直接运用到中文业务场景。目前针对上述问题有两个解决方案:使用多语言多模态大模型;基于目标语言的多模态数据进行大模型预训练。例如M3P就是一个典型的多语言多模态大模型,华为的 Wukong 是一个基于大规模中文预料的多模态大模型。但是,这些方案的训练成本高,难以持续 Follow 学界大模型进展,进而无法将这些大模型有效地利用于业务场景。
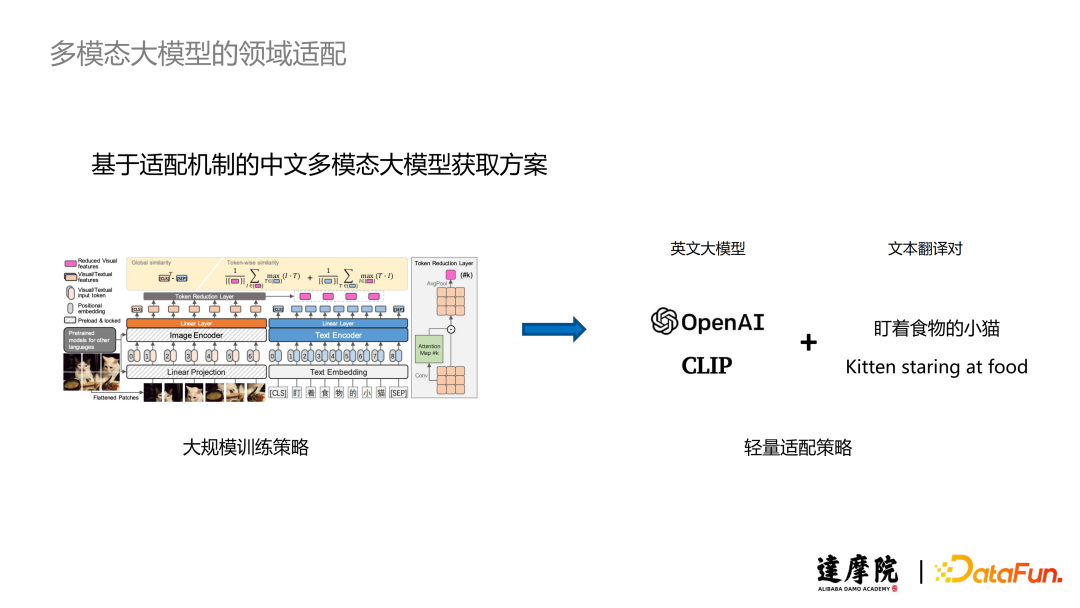
我们的目标是找到一个轻量的适配方案来解决多模态大模型的语言不匹配问题。之前的大规模训练策略并没有利用到视觉与语言的解耦性质,所以我们可以在训练过程中只针对文本进行适配,例如在使用 CLIP 时我们可以利用中英语的文本翻译对来得到一个可以在中文场景下直接使用的 CLIP 模型。

基于这一想法,我们设计了基于 Adapter 机制的语言适配链路。我们重点关注两点:首先,我们只需要面向文本端进行适配,避免视觉侧的额外训练;其次,我们通过 Adapter 机制可以避免少量数据导致的训练不充分问题,提高训练效率。
具体地,我们将一个英语 Encoder 换为一个中文 Encoder 后,它输出的向量可以和英语 Encoder 输出的向量尽可能保持一致,使得后续在经过 Cross-model Transformer 进行 Fusion 以及与视觉 Embedding 进行对齐的过程中带来的性能损失尽量小。
总而言之,我们的训练目标是逼近两个向量的距离。在训练过程中我们并没有选择重新预训练一个语言模型,而是使用了预训练完毕的 Chinese BERT 和一个可学习的 Adapter,通过 Adapter 将 Chinese BERT 输出的向量映射到英语 Encoder 的表示空间中。这样做既可以很有效地避免少量数据导致的 Encoder 训练不充分问题,又可以利用 Adapter 参数量较少的优点大幅缩短训练时间。Adapter 的网络结构由堆叠的 Transformer Layer 和两个 Down 和 Up 的映射层组成。为了参数的有效性在实验过程中 Transformer Layer 一般设定为 1 层或者 2 层即可。
我们设计了精度损失实验来验证我们设计的方案的有效性。我们采用Zero-Shot 的方式,在原始 CLIP 模型的基础上,分别使用少量的精翻英文版本的数据、原始中文版本的数据在 CLIP 与 CLIP 模型+中文 Adapter 上进行实验。实验结果表明,若使用精翻版本的数据,CLIP 模型的准确率可以达到 56%,而使用原始中文版本数据 CLIP 的准确率则仅为 18%。这说明了 CLIP 模型确实无法处理中文数据。
此外,当我们使用适配之后的中文版本 CLIP 之后,模型 Zero-Shot 的准确率达到了 55%,这说明我们的轻量适配方案对精度的损失极其有限,进而证明 Adapter 适配方案可以让多模态大规模预训练模型应用到真实业务场景中去。
进一步,我们使用学术界多个跨语言多模态大模型,在 COCO-CN Text2img 的检索 Benchmark 进行 Zero-Shot 实验。M3P 的 mR 指标在 32.3,Wukong 的 mR 指标达到了 72.2,而使用 Adapter 进行中文适配的 CLIP 模型的mR指标达到了 73.5,超越了专门在中文数据集上训练的 Wukong 模型。不可否认的是,Adapter 方案优秀的效果一定程度上归因于 CLIP 模型的高质量预训练,但是使用 Adapter 机制后,CLIP 在中文场景下的表现并不会有大幅度的下降,所以这证明了 Adapter 机制的有效性。
03
多模态大模型的领域适配
这一节将会分享我们在多模态大模型的领域适配方向收获的工作成果。

当前多模态大模型主要是在通用领域进行训练,但是这会导致它们在特定的业务场景(如电商、客服场景等)下获得的收益并不明显。这一问题的研究在学术界已经存在了一定时间,主要的解决方案是基于特定领域收集大规模数据进行模型的训练,获得一个领域下的预训练大模型,代表作为阿里巴巴的 FashionBERT。可是这一方法的数据收集成本非常高、训练成本很高。在电商场景下我们可能可以收集到足够多的数据来进行大模型的训练,但在一些小众场景下收集上百万、上千万的数据相当困难。
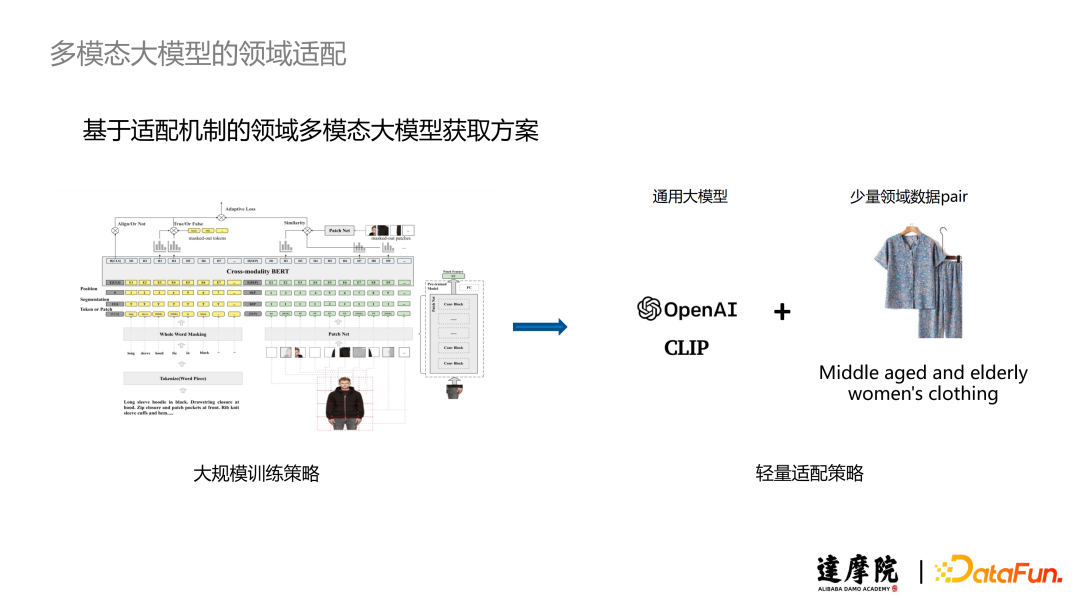
有了之前语言适配的经验,我们考虑是否可以找到一个轻量的适配方案,使得多模态大模型从通用领域迁移至一个特定领域。在我们看来,虽然我们大模型学习到的通用领域的知识难以直接满足特定的业务场景,但是这些通用知识可以有效地帮助我们更快速地学习特定领域的知识。基于这一想法,我们选择使用通用大模型加上少量的领域数据对来获取一个面向特定领域的大模型。
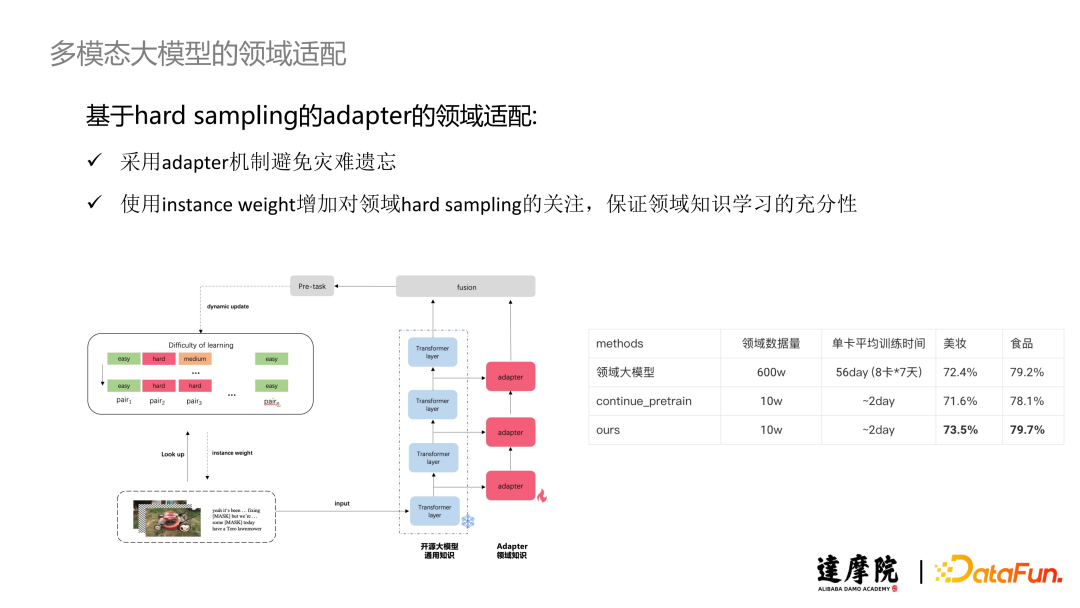
我们提出了基于 Hard Sampling 的 Adapter 的领域适配链路。在这个方案中,我们沿用了语言适配方案的想法,采用了 Adapter 机制避免灾难性遗忘的问题。此外,我们在数据采样中考虑判断一个数据对是否为一个 Hard Sample,使用 Instance Weight 增加对领域 Hard Sampling 的关注,保证那些模型很难预测正确的样本被充分训练,保证领域知识学习的充分性。在上图中展示了增加了 Adapter 机制的模型结构图,Transformer Layer 可以看作是负责表示通用知识(参数 Frozen),而 Adapter 负责学习领域知识,通过二者的结合得到一个综合向量表征。此外,我们还设计了一个类似 Memory Bank 的结构来记录每个数据对的难易程度,如果这个 Pair 很容易被开源大模型区分,那么我们认为这是一个“简单”的 Pair,否则我们就判定它是一个较困难的 Pair。在训练过程中,我们会基于较难的 Pair 更高的采样权重。
在对比实验中,我们与两个 Baseline 进行比较:使用大规模领域数据进行端到端的预训练大模型和使用持续学习进行训练的大模型。前者我们使用的领域数据量为 600 万,利用了 8 卡训练了 7 天(单卡 56天),在美妆和食品领域下分别取得了 72.4% 和 79.2% 的准确率;后者使用了 10 万的领域数据,单卡训练时间约为两天,在美妆和食品领域下分别取得了 71.6% 和 78.1% 的准确率,与领域大模型相比有一定的性能下降。出现这一现象的原因是持续学习的灾难遗忘问题和少量数据训练存在的领域知识学习不充分的问题。利用我们提出的基于 Hard Sampling 的 Adapter 领域适配机制,在同样使用 10 万的小样本数据,经过单卡约 2 天的训练,在美妆和食品领域下分别取得了 73.5% 和 79.7% 的准确率,超过了使用 600 万数据训练的领域大模型的效果。这归因于:采用 Hard Sampling 机制保证领域知识被充分学习;有效地利用了通用知识,结合通用知识和领域知识可以使得模型带来一定程度的性能增益。
04
多模态大模型的优化目标适配
最后来分享一下我们在多模态大模型的优化目标适配的方向得到的经验与成果。

Prompt Learning 在 NLP 领域应用广泛,它主要去解决下游任务的优化目标与大模型预训练的优化目标不一致的问题。例如,在文本分类任务中,如果我们直接使用预训练的 MLM 则无法最大程度利用大模型的知识,使得文本分类的效果,尤其是小样本下难以达到最优。Prompt Leanring 利用 Prompt,将文本分类任务转化成生成任务的形式,使得任务贴合语言模型预训练时的优化目标。在 NLP 小样本任务上,Prompt Learning 收益显著。
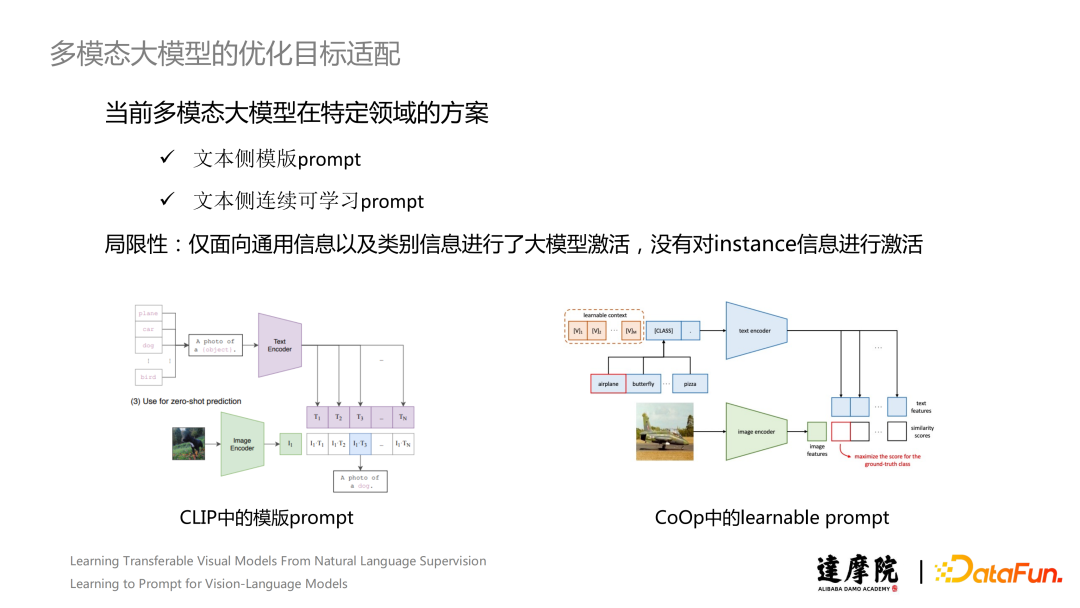
在多模态大模型中也有工作使用 Prompt Learning 机制来进行优化目标适配。例如,在 CLIP 原文中,作者在 Text Encoder 端加入 Prompt,让下游分类任务更好适配到预训练阶段的跨模态对齐任务。目前,常规的 Prompt Learning 的方案共有两种:文本侧模板 Prompt 和文本侧连续可学习 Prompt。可学习 Prompt 提出的初衷是考虑到离散 Prompt 需要使用大量时间进行精调,效果波动较大,而且预先设定的离散 Prompt 不具有灵活性,难以得到一个令人满意的效果。但是,这两种方法存在一定的局限性。这两个方法仅面向通用信息以及类别信息进行了大模型激活,并没有考虑对 Instance 信息进行激活。
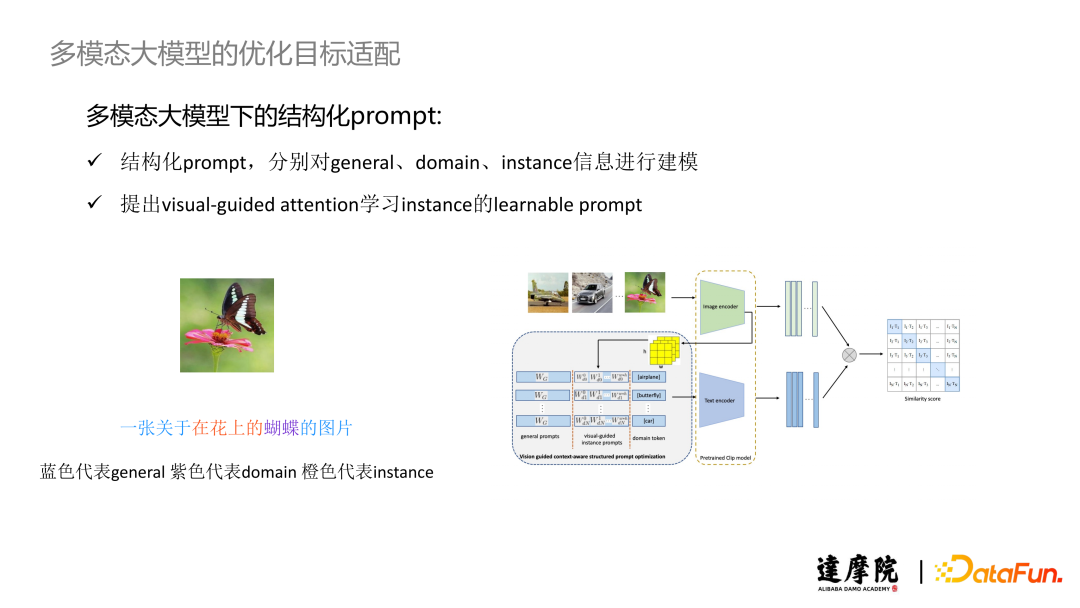
考虑到上述问题,我们提出了结构化 Prompt,分别对 General、Domain、Instance 信息进行建模。例如上图左侧展示的蝴蝶,我们认为“一张关于…的图片”是 General 信息,“蝴蝶”代表 Domain 信息,“在花上”代表 Instance 信息。此外,我们使用 Visual-Guided Attention 机制学习 Instance 的可学习 Prompt。上图右侧展示了我们的模型结构,框中第一列是 General Prompt,第二列是 Visual-Guided Attention 机制学习的 Instance Prompt,第三列是 Domain Prompt。
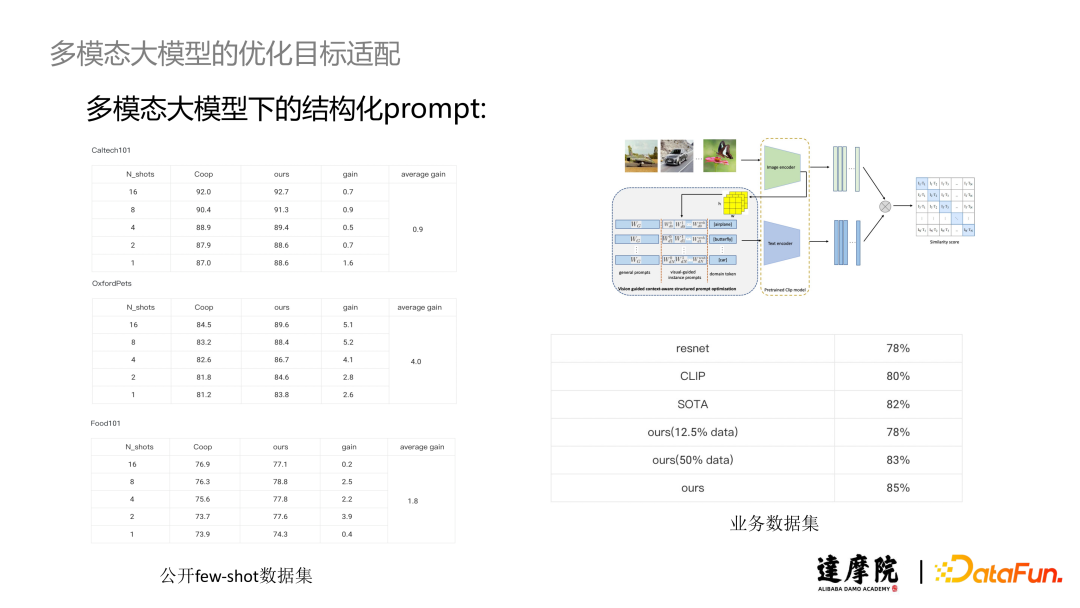
为了验证我们提出的结构化 Prompt 的有效性,我们首先在图像分类的小样本数据下进行了实验。实验结果表明,在不同的分类场景下,无论是使用 1 Shot 还是 N shot 训练,我们的方案总是可以相较 Coop 得到正向的收益。我们也将结构化 Prompt 方案应用与实际的业务场景中。我们仅仅使用 12.5% 的数据就可以达到与 Resnet 同样的准确度,仅仅用 50% 的数据就可以达到甚至超越 SOTA 的效果,在全量数据下更是达到了高于 SOTA 方法 3 个百分点的效果。
05
Q&A环节
Q1:在领域适配机制中,使用的adapter的参数量大约是多少?
A1:Adapter 的参数量不大,我们通常只会使用 1~2 层的 Transformer Layer 加上两个线性层即可,模型中使用的大规模多模态预训练模型的参数都是被 Frozen 住的。
Q2:Domain 和 Instance 信息是怎样区分的?
A2:Domain 信息主要是图像分类任务中的类别标签对应的信息,如例子中展示的蝴蝶;“在花上”是 Instance 信息,这是因为不是所有含有蝴蝶的图片都有“在花上”这一视觉属性,因为我们将其看作为 Instance 特有的信息。
Q3:Adapter 机制可以在生命科学领域进行使用吗?
A3:我认为语言适配和领域适配方案可以取得成功的一个原因是大规模预训练模型中包含的语言以及视觉的通用知识可以在不同语言、不同领域中进行迁移和使用。如果生命科学领域的大规模预训练模型所包含的底层知识可以在不同领域间具有通用性,那么 Adapter 机制就可能可以使用。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢