
来自今天的爱可可AI前沿推介
[CV] Vision Transformers Are Good Mask Auto-Labelers
S Lan, X Yang, Z Yu, Z Wu, J M. Alvarez, A Anandkumar
[NVIDIA & Meta AI & Fudan University]
视觉 Transformer 是优秀的掩码自标记器
要点:
-
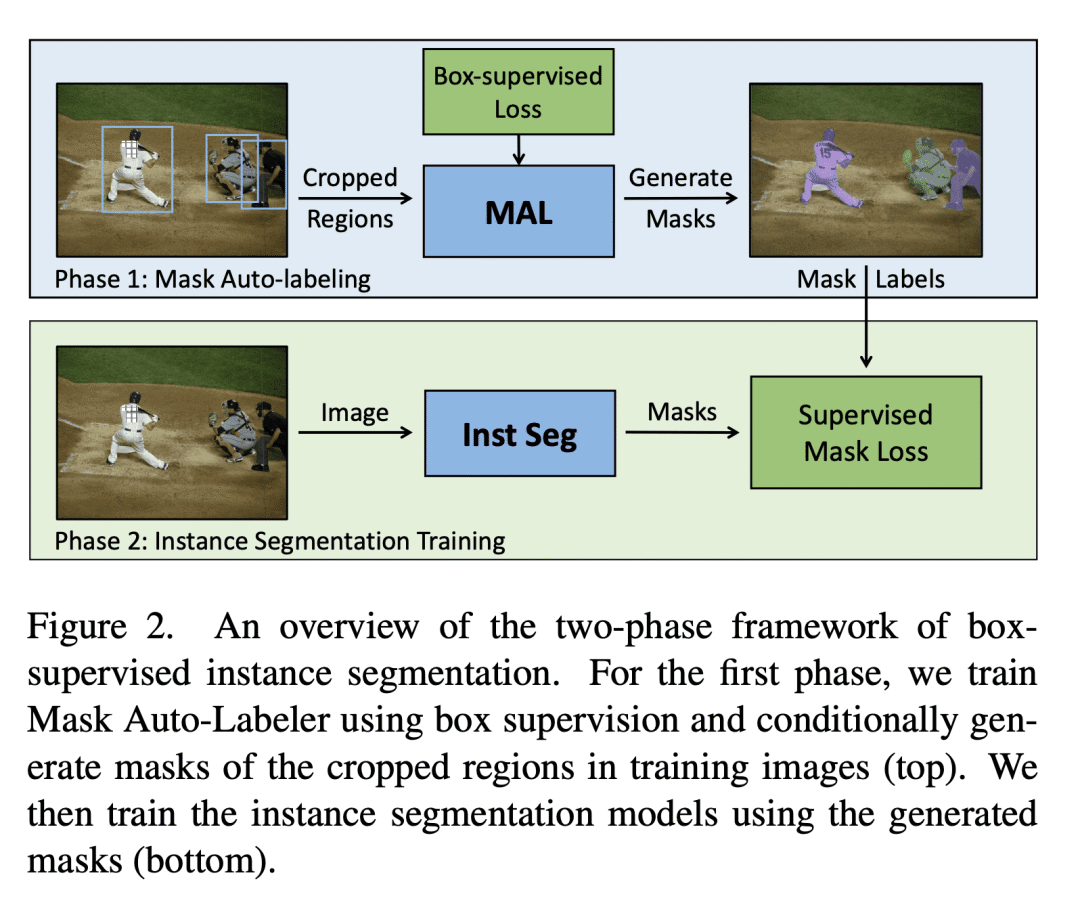
提出一种新的基于框监督的实例分割两阶段框架——掩码自标记器(MAL),简单且与实例分割模块设计无关; -
用视觉Transformers(ViTs)作为图像编码器会产生较强的自动标记效果; -
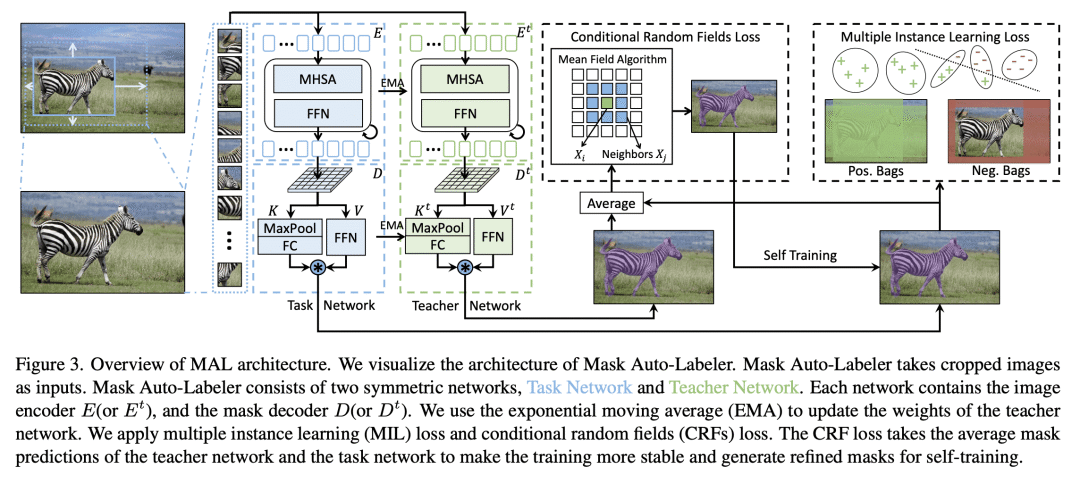
MAL的特定设计元素——例如基于注意力的解码器,基于框扩展的多实例学习和类别无关训练——对自动标记性能有重要影响。
一句话总结:
提出一种新的基于框监督的实例分割的两阶段框架MAL,利用视觉 Transformer 生成高质量的掩码伪标记,确定了增强MAL性能的关键设计元素,缩小了框监督和全监督方法之间的差距,可以达到几乎人类水平的表现,并能很好地泛化到未见过的新类别。
摘要:
提出了一种基于Transformer的高质量掩码自标注框架掩码自标记器(MAL),只用框标注进行实例分割。MAL将框裁剪图像作为输入,并有条件地生成其掩码伪标签。视觉Transformer是优秀的掩码自标注器。所提出方法显著减少了自动标记与人工标记之间关于掩码质量的差距。用MAL生成的掩码训练的实例分割模型可以接近与其全监督对应模型的性能相匹配,保留了高达 97.4% 的全监督模型性能。最佳模型在COCO实例分割上(test-dev 2017)达到 44.1% mAP,显著优于最先进的框监督方法。定性结果表明,MAL生成的掩码在某些情况下甚至比人工标注更好。
We propose Mask Auto-Labeler (MAL), a high-quality Transformer-based mask auto-labeling framework for instance segmentation using only box annotations. MAL takes box-cropped images as inputs and conditionally generates their mask pseudo-labels.We show that Vision Transformers are good mask auto-labelers. Our method significantly reduces the gap between auto-labeling and human annotation regarding mask quality. Instance segmentation models trained using the MAL-generated masks can nearly match the performance of their fully-supervised counterparts, retaining up to 97.4% performance of fully supervised models. The best model achieves 44.1% mAP on COCO instance segmentation (test-dev 2017), outperforming state-of-the-art box-supervised methods by significant margins. Qualitative results indicate that masks produced by MAL are, in some cases, even better than human annotations.
论文链接:https://arxiv.org/abs/2301.03992

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢