
模型github: lvwerra/trl: Train transformer language models with reinforcement learning. (github.com)https://github.com/lvwerra/trl
这个项目是复现 ”Fine-Tuning Language Models from Human Preferences" by D. Ziegler et al一文的[paper, code](https://github.com/openai/lm-human-preferences),因为觉得它非常好用,所以跟着跑通这个项目,并加上自己的理解介绍给大家。
理论基础
什么是可控文本生成?
虽然GPT2已经能生成流畅的句子,但是在特定话题的控制和逻辑性上仍然和期望相去甚远。我们希望一个文本生成模型可以一贯地围绕一个话题进行续写,而不是漫无目的地续写下去,这就是可控文本生成的研究目标。
在特定的运用场景中,我们有时需要用文本生成的方式增广数据。这时候可控文本生成可以在保证标签不变的前提下产生出大量的“伪数据”。
而大模型如GPT3、chatGPT效果较好,但是并不开源,而且由于巨大的参数量,微调起来也是浩大的工程。所以大部分的可控文本生成研究还是围绕GPT2做文章。
强化学习和PPO
强化学习不同于监督学习。监督学习只是对给定的、封闭的训练-验证数据集做参数优化,再用优化后的参数指导模型做出正确的输出。而强化学习的特点表现在强化信号上,强化信号是对产生动作的好坏作一种评价 (通常为标量),因此模型在不断产出输出的同时也在不断获得针对该输出的反馈,用这个反馈来更新模型参数。只要反馈机制是合理的,那么强化学习就可以一直进行下去,而不会面临训练数据匮乏的问题。
PPO(近端策略优化,Proximal Policy Optimisation)是强化学习目前最有效的一种算法。和先前的强化学习算法相比,PPO它在每一步迭代中都会尝试计算新的策略,这样可以让损失函数最小化,同时还能保证与上一步迭代的策略间的偏差相对较小。
PPO 里面有两项:一项是优化的奖励,另一项是一个约束。约束是为了防止模型被微调得过于离谱,失去了原有的语言模型做流畅的文字生成的能力。
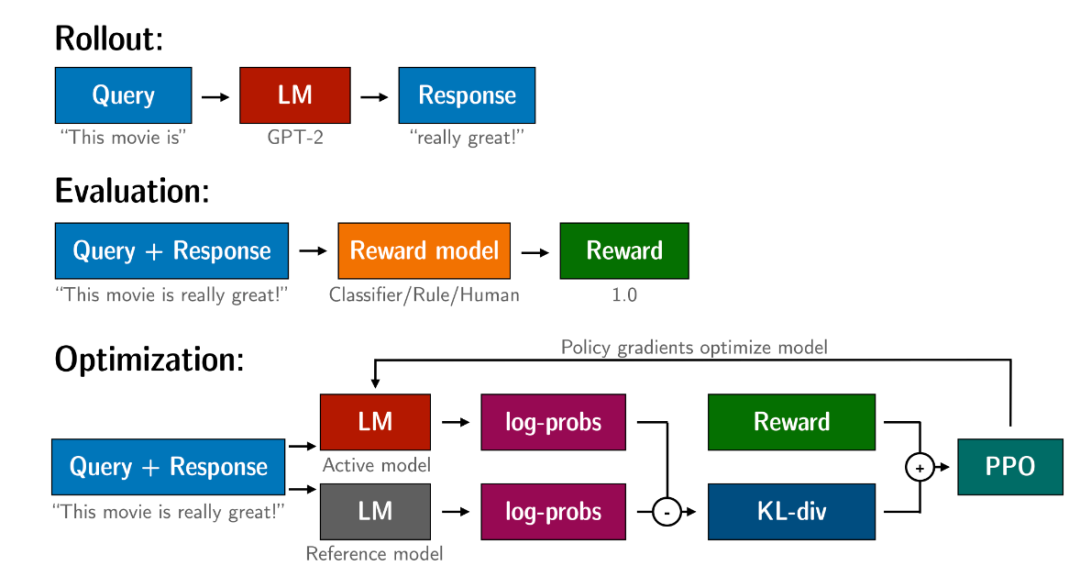
How it works?
用PPO算法优化GPT2大致分以下三个步骤:
-
续写:GPT2先根据当前权重,续写给出的句子。 -
评估:GPT2续写的结果会经过一个分类层,或者也可以采用人工的打分,重要的是最终产生出一个数值型的分数。 -
优化:上一步对生成句子的打分会用于更新序列中token的对数概率。除此之外,还需要引入一个新的奖惩机制:KL散度。这需要用一个参考模型(通常是微调前的预训练模型,如GPT2-base)计算微调模型的输出和参考模型的输出之间的KL散度,把它和之前步骤的打分加在一起作为奖励函数,目的是确保生成的句子不会过多地偏离参考语言模型。然后使用PPO算法进一步训练语言模型。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢