
【标题】Model-Based Reinforcement Learning with Multinomial Logistic Function Approximation
【作者团队】Taehyun Hwang, Min-hwan Oh
【发表日期】2022.12.27
【论文链接】https://arxiv.org/pdf/2212.13540.pdf
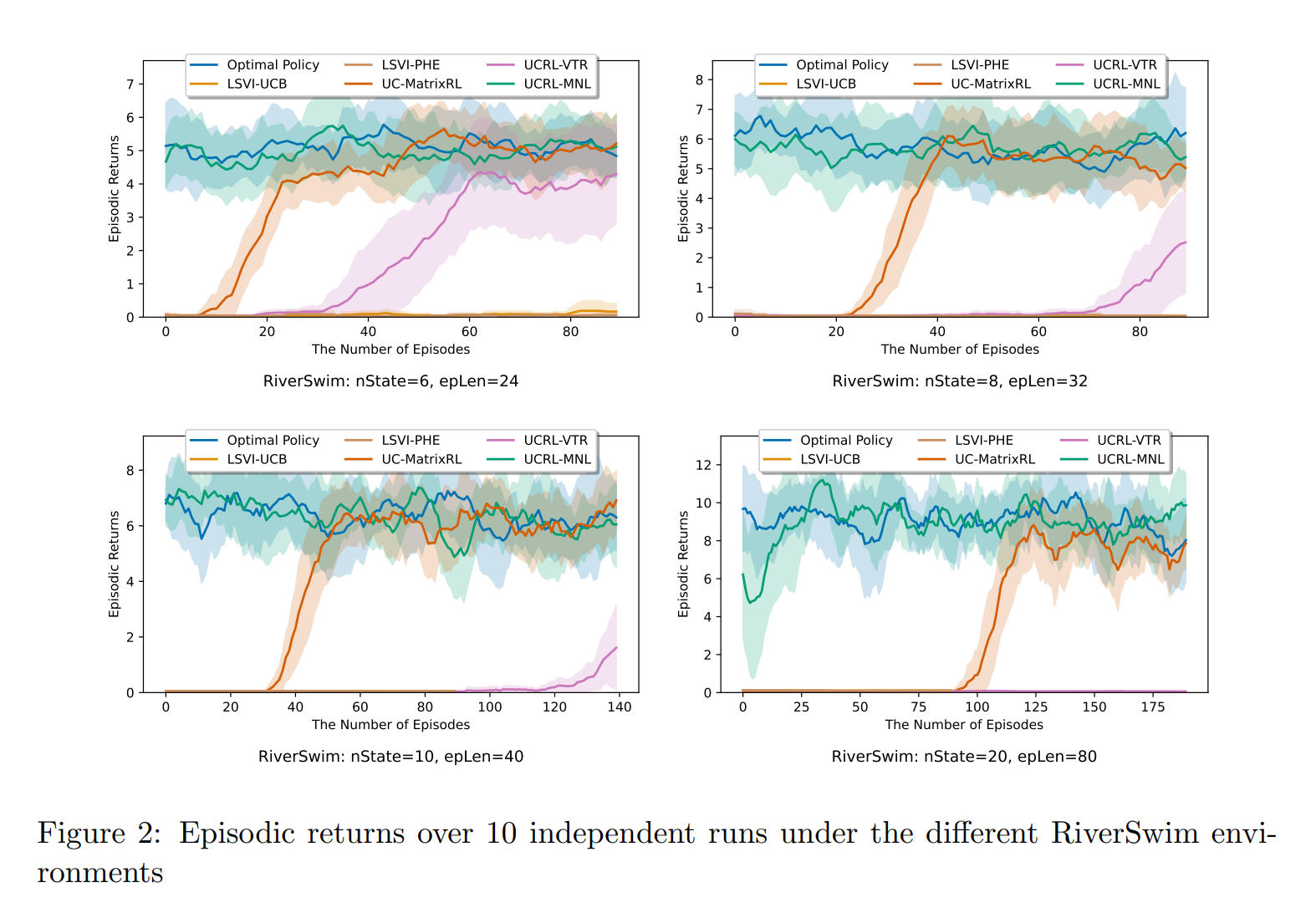
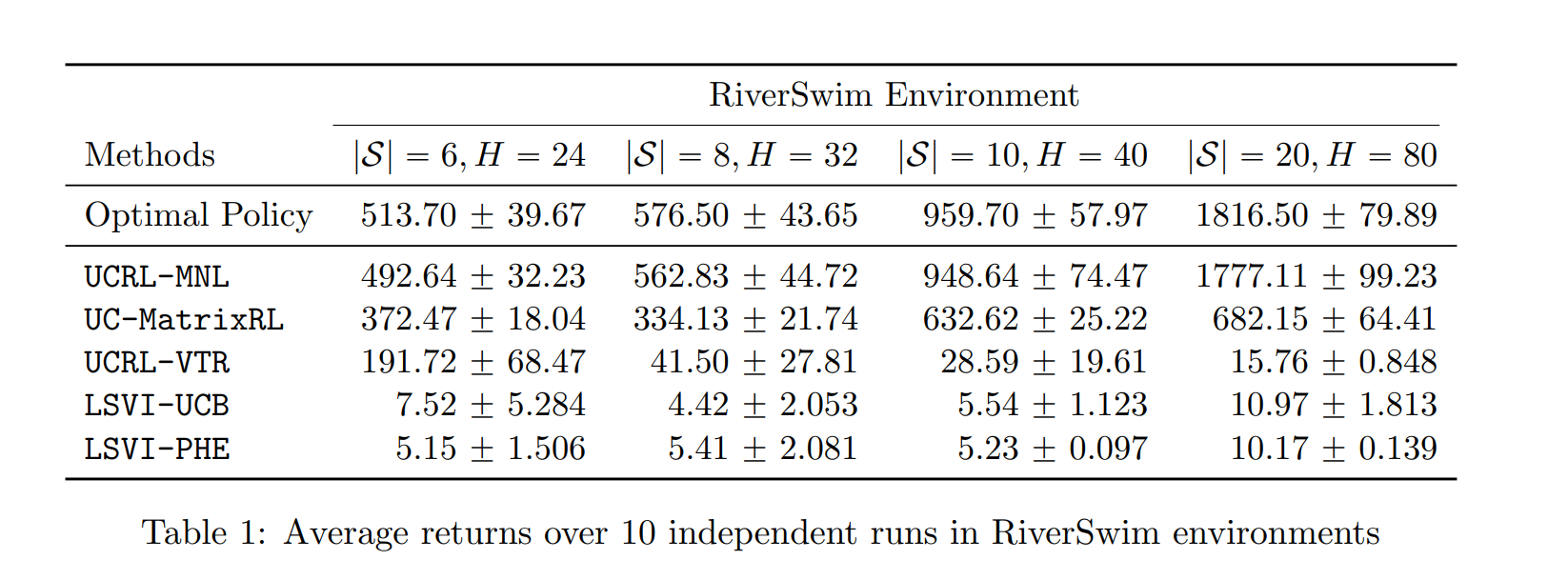
【推荐理由】本文研究了情景马尔可夫决策过程(MDP)的基于模型的强化学习(RL),其转移概率由具有状态和动作特征的未知转移核参数化。尽管最近在分析线性MDP设置中的算法方面取得了很大进展,但对更一般的过渡模型的理解非常有限。在本文中,作者为状态转移由多项式逻辑模型给出的MDP建立了一个可证明有效的RL算法。为了平衡勘探与开发的权衡,作者提出了一种基于置信上限的算法。文章表明,作者提出的算法实现了\( \tilde{\mathcal{O}}\left(d \sqrt{H^{3} T}\right) \)遗憾界限,其中\( d \)是过渡核的维度,\( H \)是视界,\( T \)是总步数。这是第一个基于模型的RL算法,具有多项式逻辑函数逼近和可证明保证。本文还对提出的算法进行了全面的数值评估,并表明它始终优于现有方法,从而实现了可证明的效率和实际的优越性能。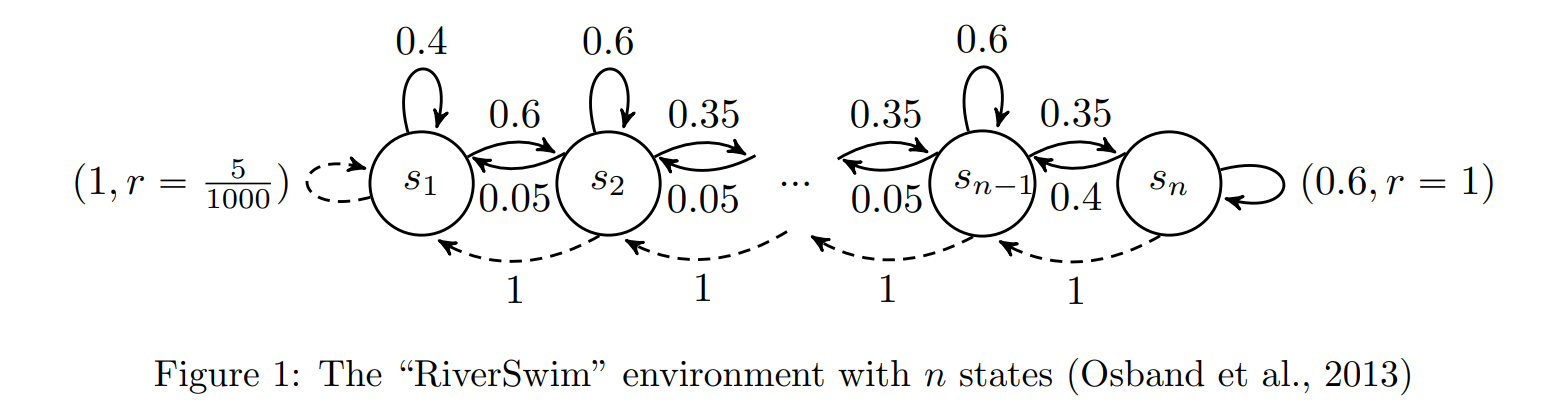
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢