
Transformer模型自发布后,很快就成了自然语言处理和计算机视觉领域在有监督学习设置下的主流神经架构。虽然Transformer的热潮已经开始席卷强化学习领域,但由于RL本身的特性,例如需要进行独特的特征、架构设计等,当前Transformer与强化学习的结合并不顺利,其发展路线也缺乏相关论文进行贯穿性地总结。
最近来自清华大学、北京大学、腾讯的研究人员联手发表了一篇关于Transformer与强化学习结合的调研论文,系统性地回顾了在强化学习中使用Transformer的动机和发展历程。
论文链接:https://arxiv.org/pdf/2301.03044.pdf
这篇调研论文的目的是介绍Transformers in Reinforcement Learning领域(TransformRL)。
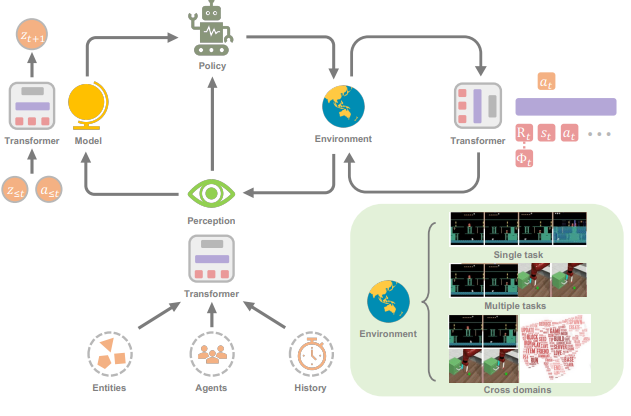
尽管Transformer已经被认为是目前大多数SL研究的基础模型,但它在RL社区的探索仍然较少。事实上,与SL领域相比,在RL中使用Transformer作为函数近似器需要解决一些不同的问题:
1. RL智能体的训练数据通常是当前策略的函数,这在Transformer学习的过程中会引起不平稳性(non-stationarity)。
2. 现有的RL算法通常对训练过程中的设计选择高度敏感,包括网络架构和容量等。
3. 基于Transformer的架构经常受到高计算和内存成本的影响,也就是说训练和推理起来既慢又贵。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢