

仅需4行文字即可生成视频

这是谷歌去年10月份便发布的一个文本转视频(Text-to-Video)模型:Phenaki,只需一段提示词,分分钟可以生成长达两分钟的视频。

打字就能生成的视频
与以往AI生成的视频不同,Phenaki最大的特点便是有故事、有长度。例如:在火星上,宇航员走过一个水坑,水里倒映着他的侧影;他在水旁起舞;然后宇航员开始遛狗;最后他和小狗一起看火星上看烟花。

而在谷歌更早发布Phenaki之际,还展示了向Phenaki输入一个初始帧以及一个提示词,便可以生成一段视频的能力。例如给定这样一张静态图:

然后再给它Phenaki简单“投喂”一句:白猫用猫爪触摸摄像机。效果就出来了:

还是基于这张图,把提示词改成“一只白猫打哈欠”,效果就成这样了:

但除了Phenaki之外,谷歌当时还一道发布过Imagen Video,能够生成1280*768分辨率、每秒24帧的高清视频片段。

它基于图像生成SOTA模型Imagen,展示出了三种特别的能力:
- 能理解并生成不同艺术风格的作品,水彩、像素甚至梵高风格
- 能理解物体的3D结构
- 继承了Imagen准确描绘文字的能力
更早的,Meta也发布了Make-A-Video,不仅能够通过文字转换视频,还能根据图像生成视频,比如:
- 将静态图像转成视频
- 插帧:根据前后两张图片生成一段视频
- 根据原视频生成新视频
简单来说,Phenaki相较于以往的生成视频模型,它更注重时间长度任意性和连贯性。Phenaki之所以能够生成任意时间长度的视频,很大程度上要归功于新的编码器-解码器架构:C-ViViT。
它是ViViT的一个因果变体,能够将视频压缩为离散嵌入。
要知道,以往获取视频压缩,要么就是编码器不能及时压缩视频,导致最终生成的视频过短,例如VQ-GAN,要么就是编码器只支持固定视频长度,最终生成视频的长度不能任意调节,例如VideoVQVAE。
但C-ViViT就不一样了,它可谓是兼顾了上面两种架构的优点,能够在时间和空间维度上压缩视频,并且在时间上保持自回归的同时,还可以自回归生成任意长度的视频。
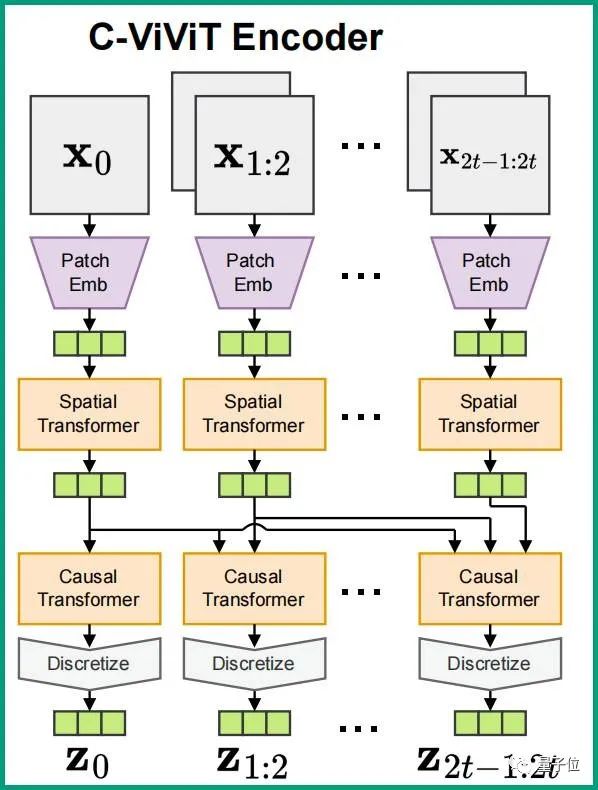
C-ViViT可以使模型生成任意长度的视频,那最终视频的逻辑性又是怎么保证的呢?
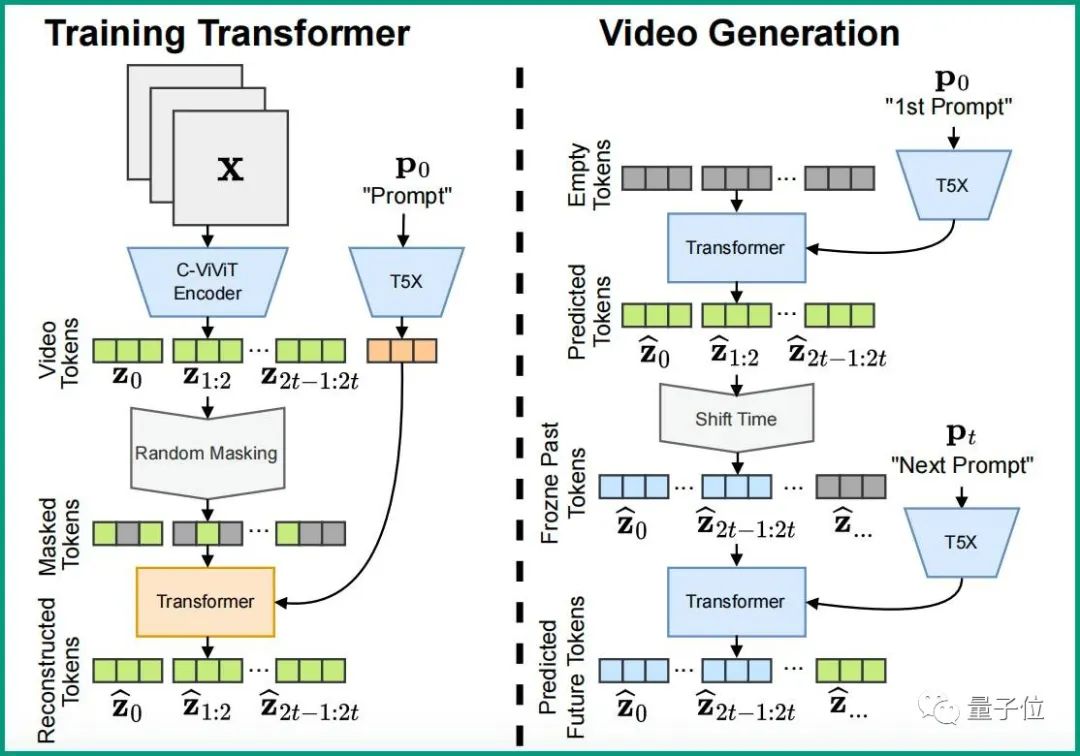
这就得靠Phenaki另外一个比较重要的部分:双向Transformer。
在这其中,为节省时间,采样步骤是固定的,并且在处理文本提示的过程中,能同时预测不同的视频token。
这样一来,结合前面提到的,C-ViViT能够在时间和空间维度上压缩视频,压缩出来的token是具有时间逻辑性的。
也就是说,在这些token上经过掩码训练的Transformer也具备时间逻辑性,最终生成的视频在连贯性自然也就有了保证。
如果还想了解更多关于Phenaki的东西,可以戳这里查看。
Phenaki:
https://phenaki.github.io
https://hub.baai.ac.cn/view/21503
参考链接:
[1] https://phenaki.video/
[2] https://phenaki.research.google/
[3] https://twitter.com/AiBreakfast/status/1614647018554822658
[4] https://twitter.com/EvanKirstel/status/1614676882758275072
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢