
作者:Judith Yue Li , Aren Jansen , Qingqing Huang ,等
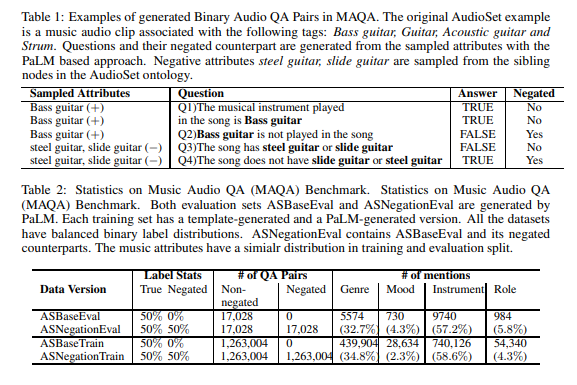
简介:本文研究音乐领域的二进制音频QA基准,以探索最先进的理解否定的多模态模型;本文提出的基准,填补了多模态环境中缺乏以否定为中心的评估基准的空白。多模态学习可以受益于预训练大型语言模型 (LLM) 的表示能力。然而,最先进的基于 transformer 的 LLMs 通常忽略自然语言中的否定,并且没有现有的基准来定量评估多模态 transformers 是否继承了这个弱点。在这项研究中,作者提出了一种新的多模式问答(QA)基准,该基准改编自 AudioSet 中标记的音乐视频(Gemmeke 等人,2017 年),目的是系统地评估多模式转换器是否可以执行复杂推理以将新概念识别为否定以前学过的概念。作者表明:无论模型大小如何,使用标准微调方法,多模态变换器仍然无法正确解释否定。然而,作者的实验表明,使用否定的 QA 示例增强原始训练任务分布可以使模型可靠地推理否定。为此,作者描述了一种新颖的数据生成过程,该过程会提示 540B 参数 PaLM 模型自动生成否定 QA 示例作为易于访问的视频标签的组合。生成的示例包含更多自然语言模式,与基于模板的任务增强方法相比,收益显著。
论文下载:https://arxiv.org/pdf/2301.03238.pdf
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢