
作者:Manh-Duy Nguyen , Binh T. Nguyen , Cathal Gurrin
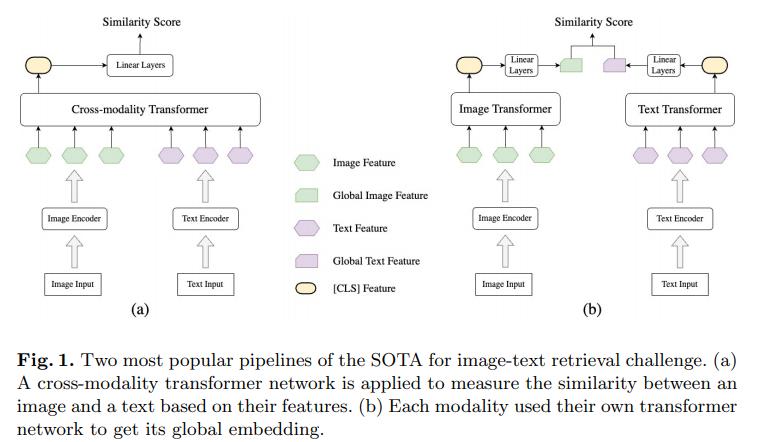
简介:本文研究一个简单的基于图的图文检索融合框架,有助于只使用1个GPU进行训练,为许多中小型初创企业不具备许多GPU的行业中的应用开辟了可能性。许多模型已经被提出用于视觉和语言任务,特别是图像文本检索任务。此挑战中的所有最先进 (SOTA) 模型都包含数亿个参数。他们还在一个大型外部数据集上进行了预训练,该数据集已被证明可以显着提高整体性能。提出一个具有新颖架构的新模型并在具有许多 GPU 的海量数据集上对其进行集中训练以超越许多已经可以在互联网上使用的 SOTA 模型并不容易。在本文中,作者提出了一个紧凑的基于图的框架,名为 HADA,它可以结合预训练模型来产生更好的结果,而不是从头开始构建。首先,作者创建了一个图结构,其中节点是从预训练模型中提取的特征以及连接它们的边。图结构用于捕获每个预训练模型的信息并将其融合在一起。然后应用图神经网络更新节点之间的连接以获得图像和文本的代表性嵌入向量。最后,作者使用余弦相似度将图像与其相关文本进行匹配,反之亦然,以确保较短的推理时间。实验表明:尽管 HADA 包含少量可训练参数,但就 Flickr30k 数据集中的评估指标而言,它可以将基线性能提高 3.6% 以上。此外,所提出的模型没有在任何外部数据集上进行训练,并且由于参数数量少,不需要很多 GPU 而只需要 1 个即可进行训练。
论文下载:https://arxiv.org/pdf/2301.04742.pdf
源码下载:https://github.com/m2man/HADA
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢