

越来越多的工作证明了预训练语言模型(PLM)中蕴含着丰富的知识,针对不同的任务,用合适的训练方式来撬动 PLM,能更好地提升模型的能力。在 Text-to-SQL 任务中,目前主流的生成器是基于语法树的,需要针对 SQL 语法进行设计。
近期,网易互娱 AI Lab 联合广东外语外贸大学和哥伦比亚大学基于预训练语言模型 T5 的预训练方式,提出了两阶段的多任务预训练模型 MIGA。MIGA 在预训练阶段引入三个辅助任务,并将他们组织成统一的生成任务范式,可以将所有的 Text-to-SQL 数据集统一进行训练;同时在微调阶段,MIGA 针对多轮对话中的错误传递问题进行 SQL 扰动,提升了模型生成的鲁棒性。
目前对于 Text-to-SQL 的研究,主流的方法主要是基于 SQL 语法树的 encoder-decoder 模型,可以确保生成的结果一定符合 SQL 语法,但是需要针对 SQL 语法进行特殊设计。最近也有一些关于 Text-to-SQL 的研究是基于生成式语言模型,可以很方便地继承预训练语言模型的知识和能力。
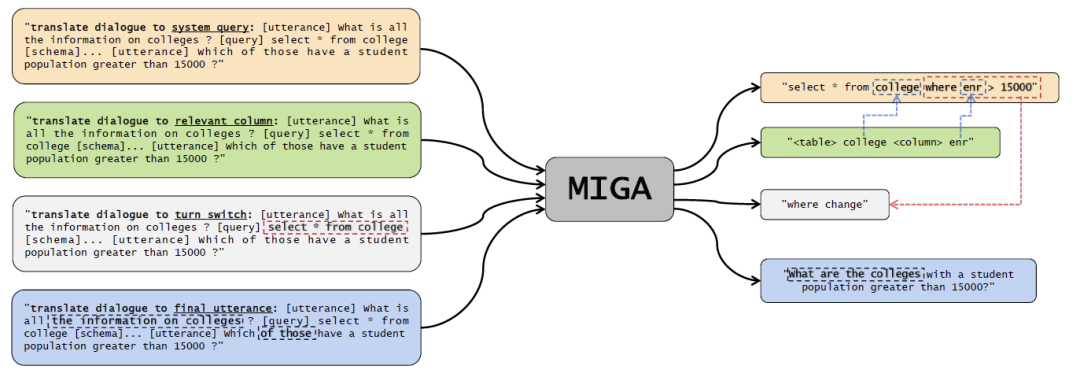
为了降低对基于语法树的依赖,更好地挖掘预训练语言模型的能力,该研究在预训练 T5 模型的框架下,提出了一个两阶段的多任务 Text-to-SQL 预训练模型 MIGA (MultI-task Generation frAmework)。
MIGA 分为两阶段的训练过程:
-
在预训练阶段,MIGA 使用与 T5 相同的预训练范式,额外提出了三个与 Text-to-SQL 相关的辅助任务,从而更好地激发预训练语言模型中的知识。该训练方式可以将所有的 Text-to-SQL 的数据集进行统一,扩充了训练数据的规模;而且也可以灵活地去设计更多有效的辅助任务,进一步发掘预训练语言模型的潜在知识。
-
在微调阶段,MIGA 针对多轮对话和 SQL 中容易存在的错误传递问题,在训练过程中对历史 SQL 进行扰动,使得生成当前轮次的 SQL 效果更加稳定。
MIGA 模型在两个多轮对话 Text-to-SQL 公开数据集上表现优于目前最好的基于语法树的模型,相关研究已经被 AAAI 2023 录用。

论文地址:https://arxiv.org/abs/2212.09278
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢