

论文连接:https://arxiv.org/abs/2211.13654
代码连接:https://github.com/zhengchen1999/CAT
导读
Transformer模型在图像复原领域取得令人瞩目的成绩。不过考虑到Transformer过高的计算复杂度,部分工作尝试使用局部窗口注意力来限制自注意力的作用范围。但是这些方法缺少窗口之间的直接交互,限制了模型长程依赖的建模。针对这个问题,本文提出交叉聚合Transformer(Cross Aggregation Transformer,CAT),使用新颖的Rwin-SA与Axial-Shift操作,在不增加计算复杂度的情况下,提高窗口间的信息聚合。同时提出LCM模块,实现全局与局部信息的耦合。我们将CAT模型应用于3个经典的图像复原任务:图像超分辨率、压缩伪影去除、真实图像去噪,均取得最佳的性能。
背景
图像复原是一个长期的低级视觉任务,旨在从低质量的图片(LQ),恢复出对应的高质量图片(HQ)。根据退化类型的不同,可以分为多个子任务,例如图像超分辨率,图像去噪,图像去模糊等。目前主流的复原算分是通过深度神经网络模型进行端到端的图像重构。
1 图像复原
基于卷积神经网络(CNN)的模型,在图像复原任务中取得出色的表现,并取代传统方法(例如基于滤波),成为该领域的主流。大量的模型被提出用于改进复原效果 [1, 2, 3, 4],这些方法借助残差学习、密集连接等技术,来尽可能的提高CNN模型的深度,从而更多的高频信息。同时空间与通道注意力机制也被引入到模型中,使网络能够更加关注特征图中的特定信息。
2 视觉Transformer
Transformer模型首先在自然语言处理(NLP)中被提出,其核心为自注意力机制(self-attention,SA)。与卷积相比,自注意力具有动态权重,并且能够建模长距离依赖关系。考虑到Transformer在NLP中取得的性能,部分工作将Transformer引入到视觉领域 [6, 7],并且在多个高级视觉任务中取得最佳的性能。这些工作主要关注于降低Transformer的计算复杂度并提升模型性能。例如使用窗口注意力机制并通过Shift操作增加窗口交互,或者提出交叉形式的窗口。
同时,在低级视觉任务,如图像复原领域,目前也提出部分工作,尝试用Transformer替换传统的CNN模型。SwinIR [8] 使用窗口划分图像,并在每个图像上分别执行注意力操作,同时也采用Shift操作增加窗口交互。Restormer [9] 则在特征图的通道维度计算交叉协方差。这些方法都能实现与图像大小成线性的计算复杂度,并在一定程度上保留Transformer长距离建模能力,从而优于基于CNN的模型。
方法
在本节中,我们首先介绍本文模型的整体架构。然后是核心模块的三个创新点:矩形窗口注意力机制(rectangle- window self-attention,Rwin-SA)、轴向位移操作(axial-shift)以及局部补充模块(locality complementary module,LCM)。
1 模型架构
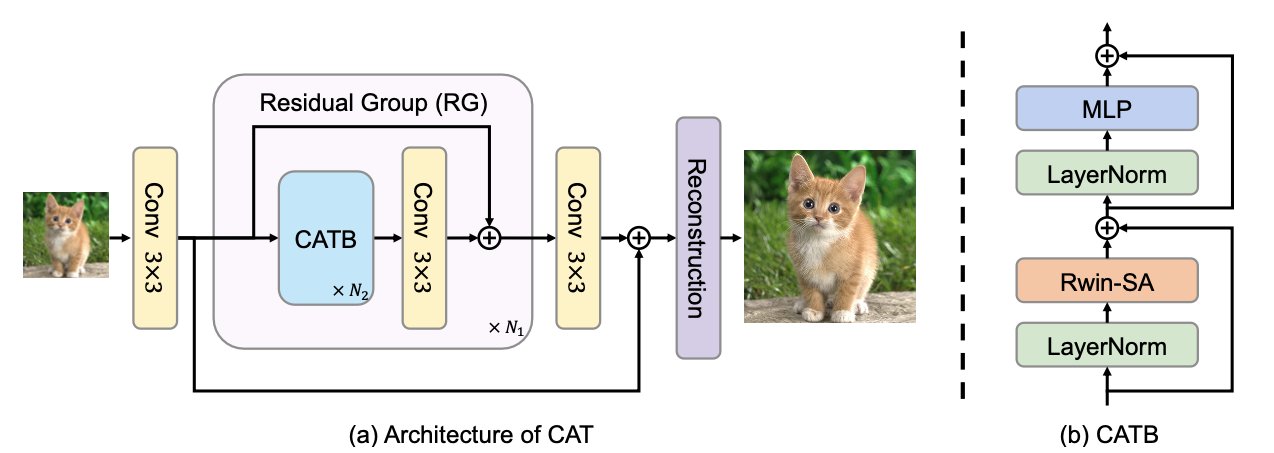
本文提出的交叉聚合Transformer(Cross Aggregation Transformer,CAT)如图片1所示。对于大小为 H×W×C 的低质量图片 \( I_{LQ} \) ,首先通过一个 3×3 卷积进行处理,提取出处低级特征 。接着通过由 个残差组(Residual Group)与一个 卷积组成的深度特征提取模块,获得深度特征 \( F_{DF} \) 。每一个残差组都由 \( N_2 \) 个交叉聚合Transformer块(CATB)和一个 卷积组成,并使用残差连接。CATB的结构如图片1 (b)所示,这也是本文的核心模型,在下文将对其进行详细介绍。最后 F0 与\( F_{DF} \) 相加并通过重构模型恢复出对应的高质量图片 \( I_{HQ} \) 。
值得注意的是,针对不同的复原任务,我们只需要使用不同的重构模块。在图像超分辨率任务中,重构模块由2个 3×3 卷积和一个上采样模块组成,而在压缩伪影去除任务中,重构模块只由卷积组成。此外,对于真实图像去噪,本文参考Restormer,使用U-Net架构并结合我们提出的CATB,构成相应模型。
2 交叉聚合Transformer块(CATB)
CATB是本文的核心模型,使用一种新颖的矩形窗口注意力机制(Rwin-SA)和轴向位移操作(Axial-Shift),以及通过局部补充模块(LCM)耦合全局与局部特征。
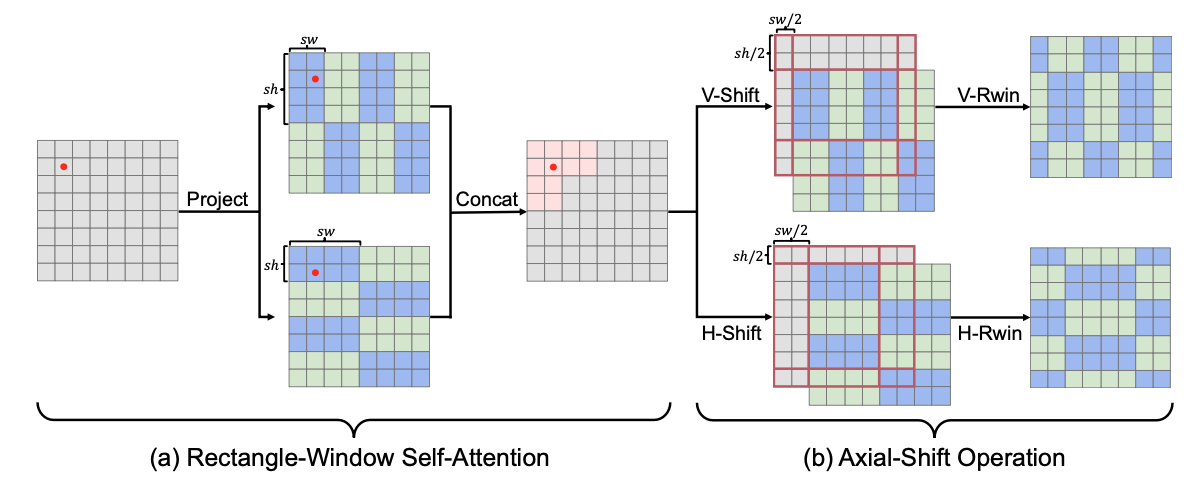
矩形窗口注意力(Rwin-SA) 如图片2 (a),本文提出的Rwin-SA,同样适用窗口对特征图进行划分,这里我们用蓝色与绿色区分相邻窗口。但是与之前的工作不同,我们使用的是矩形窗口(长为 \( s_h \) ,宽为 )而不是方形窗口,并考虑到矩形窗口长-宽特性,我们将其分为水平矩形与垂直矩形两种形式。通过将特征图沿通道维度拆分为两组,并分别应用两种矩形窗口进行划分,执行注意力操作后,再沿着通道维度进行合并,从而能够在不增加计算复杂度的情况下,有效提升感受野,聚合不同窗口的信息特征。可以看到,在中间特征图中,对于红色点,其感受区域为粉色方格组成,明显大于蓝色与绿色窗口。对于每一个窗口,注意力的计算公式如下:
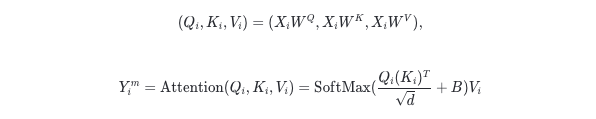
这里 i 代表第 i 个窗口,一共有 \( \frac{H×W}{sh×sw} \) 窗口。此外,如果将矩形窗口的其中一条边延长至与特征图宽度相同,那么划分的窗口则变为一条沿着水平或垂直轴的条带,这与一般的矩形窗口相比,能获得更多的交互空间。为了区分这两种划分,我们将常规矩形窗口命名为regualr-Rwin,而对于条带式的矩形窗口,则命名为axial-Rwin。
轴向位移操作(Axial-Shift) 为了进一步扩大窗口之间的交互,本文提出轴向位移操作,该操作充分考虑到不同矩形窗口的特性,同样分为水平(H-Shift)与垂直(V-Shift)两种。如图2 (b),轴向位移操作将窗口分别向下和向左移动 sh\ 和 sw\2 像素长度,从而使得不同窗口划分之间,出现交错。在实际应用当中,我们将特征图沿左下方向循环移动,并使用掩码机制来避免非相邻像素之间的错误交互。
局部补充模块(LCM) 由于Transformer侧重于建模长距离依赖关系,而CNN的归纳偏差(平移不变性、局部性)对于图像复原任务同样重要。这些特性能够提取出部分局部特征(如物体的边、角等)。为了将CNN与Transformer想结合,我们提出了LCM模块。LCM模块由一个平行与Rwin-SA的深度卷积(depth-wise)组成,同时直接作用于自注意力中的值特征 (即公式 (1)中的 ,按照窗口重新合并,大小为 H×W×C )。
交叉聚合Transformer块(CATB) 结合以上三点,本文提出的CATB如图片1 (b)所示,由Rwin-SA与多层感知器(MLP)组成,并使用层归一化(LN),具体公式如下:
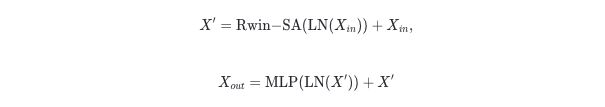
实验
1 实验设置
本文依据传统实验设置,对于图像超分辨率任务,使用DIV2K和Flickr2K进行训练,并在Set5、Set14、B100、、Urban100和Manga109上进行测试,放大比例为2、3、4。在此任务中,我们提出两个模型CAT-A和CAT-R,分别使用上述介绍的axial-Rwin和regual-Rwin。对于压缩伪影去除,使用DIV2K、Flickr2K、BSD500、WED进行训练,在Classic5和LIVE1进行测试,压缩等级为10、20、30、40。在此任务中,我们使用CAT(CAT-A)。对于真实图像去噪,本文在SIDD上训练,并在SIDD和DND上测试。在此任务中,我们同样适用CAT(CAT-A)。以上所有测试,均适用PSNR和SSIM来测量复原效果。
2 消融实验

通过实验对比,我们可以发现,我们提出的Rwin-SA和Axial-Shift,与传统的方向窗口和Shift操作相比,在不增加计算复杂度(FLOPs)的情况下,性能明显提升。同时LCM模型,在CAT-A和CAT-R模型上均能提升性能,同时对复杂度的影响很小。此外,增大窗口大小也能明显提升模型性能,但是考虑到计算复杂度的影响,我们也不能无限制的提高窗口大小。
3 结果对比
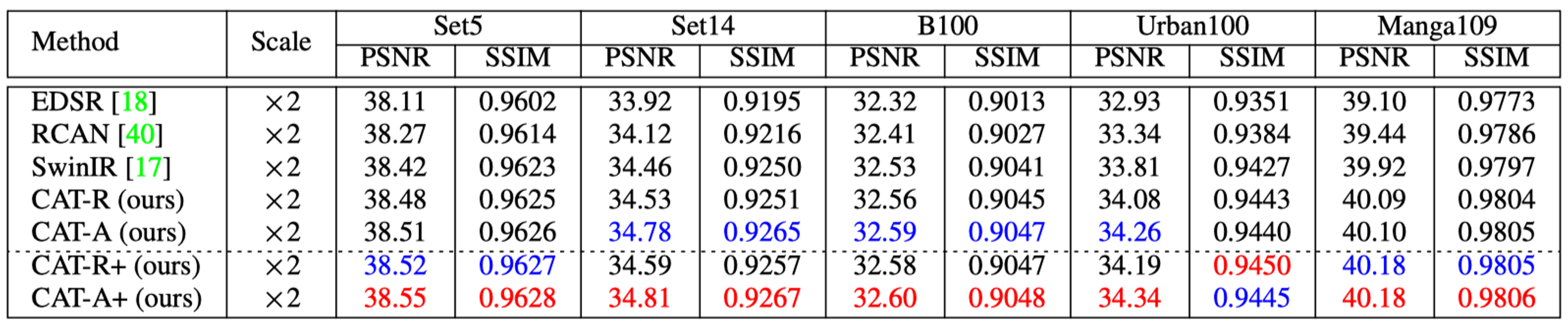
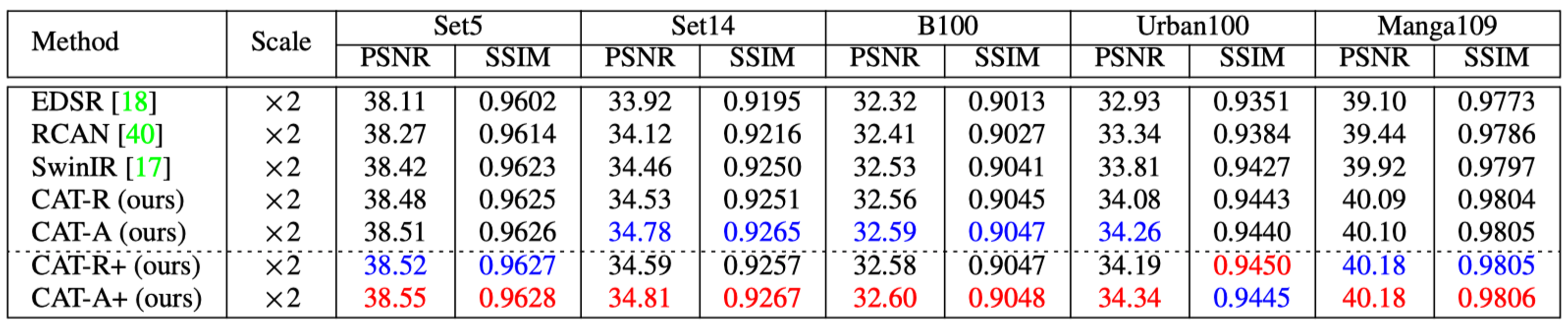
图像超分辨率 由于篇幅问题,这里只展示部分结果,更多详细对比数据,可以参考论文。可以看到,本文提出的CAT-A与CAT-R,与目前主流的模型对比,均取得最佳性能。
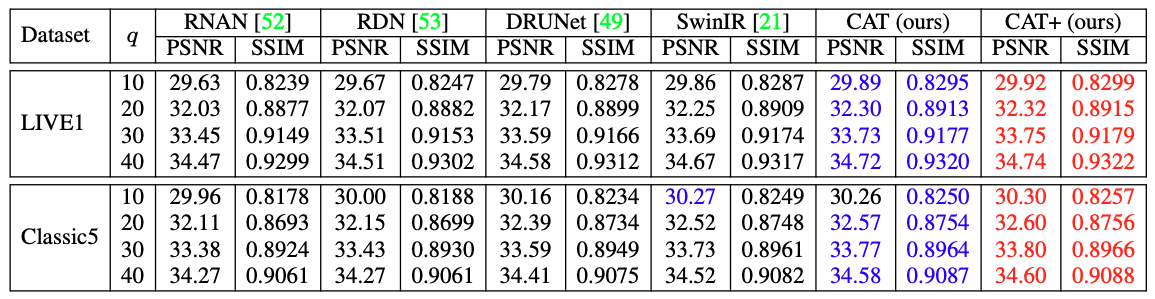
压缩伪影去除 与目前主流模型对比,本文提出的CAT模型,在除了Classic5-q=10的测试数据上略低于SwinIR,其他结果均取得最佳性能。
真实图像去噪 在去噪任务上,我们提出的模型,与目前最有性能模型Restormer相比,性能相似,同时模型复杂度更低。
以上这些实验,均表明本文提出方法的有效性。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢