
作者:Kunal Suri、Atul Singh、Prakhar Mishra、等
推荐理由:本文研究语言模型替代知识图谱解决特定领域的问题,并通过实验证明了如何使用基于特定领域数据的语言模型来替换涉及识别同义词的任务的知识图谱;论文题目略微夸张、但值得提醒思考:语言模型与知识图谱在方案选择时的优劣势取舍。
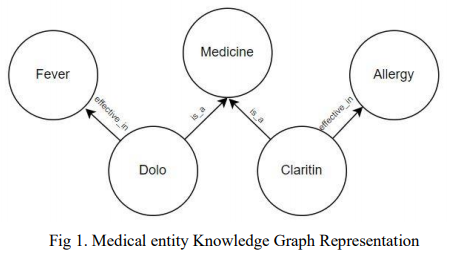
简介:医疗保健领域会生成大量非结构化和半结构化文本。自然语言处理 (NLP) 已被广泛用于处理这些数据。基于深度学习的 NLP,尤其是 BERT 等大型语言模型 (LLM) 已获得广泛认可,并广泛用于许多应用程序。语言模型是单词序列的概率分布。对大量数据的自监督学习自动生成基于深度学习的语言模型。BioBERT 和 Med-BERT 是为医疗保健领域预训练的语言模型。医疗保健使用典型的 NLP 任务(如问题回答、信息提取、命名实体识别和搜索)来简化和改进流程。然而,为了确保结果的稳健应用,NLP 从业者需要对其进行规范化和标准化。实现规范化和标准化的主要方法之一是使用知识图谱。知识图捕获特定领域的概念及其关系,但创建它们非常耗时,并且需要领域专家的手动干预,这可能证明是昂贵的。SNOMED CT(医学系统化命名法——临床术语)、统一医学语言系统 (UMLS) 和基因本体论 (GO) 是医疗保健领域中流行的本体论。SNOMED CT 和 UMLS 捕捉疾病、症状和诊断等概念,而 GO 是世界上最大的基因功能信息来源。医疗保健一直在处理有关不同类型的药物、疾病和程序的信息爆炸。本文认为,使用知识图并不是解决该领域问题的最佳解决方案。我们展示了在医疗保健领域使用 LLM 的实验,以证明语言模型提供与知识图谱相同的功能,从而使知识图谱变得多余。

论文下载:https://arxiv.org/ftp/arxiv/papers/2301/2301.03980.pdf
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢