
来自爱可可的前沿推介
Streaming Punctuation: A Novel Punctuation Technique Leveraging Bidirectional Context for Continuous Speech Recognition
P Behre, S Tan, P Varadharajan, S Chang
[Microsoft]
流标点:连续语音识别基于双向上下文的标点标记
要点:
-
提出一种用动态解码窗口对 ASR 输出标点标记或重标记的流方法,以提高跨场景的标点打标和分割精度; -
基于动态解码窗口对 ASR 输出进行流式的标点标记或重标记; -
解决了过度分割问题,改善了机器翻译下游任务结果,对各模型架构具有鲁棒性。
一句话总结:
提出的流方法提高了 ASR 标点和分割精度,减少了过度分割,改善了机器翻译结果,对各模型架构具有鲁棒性。
摘要:
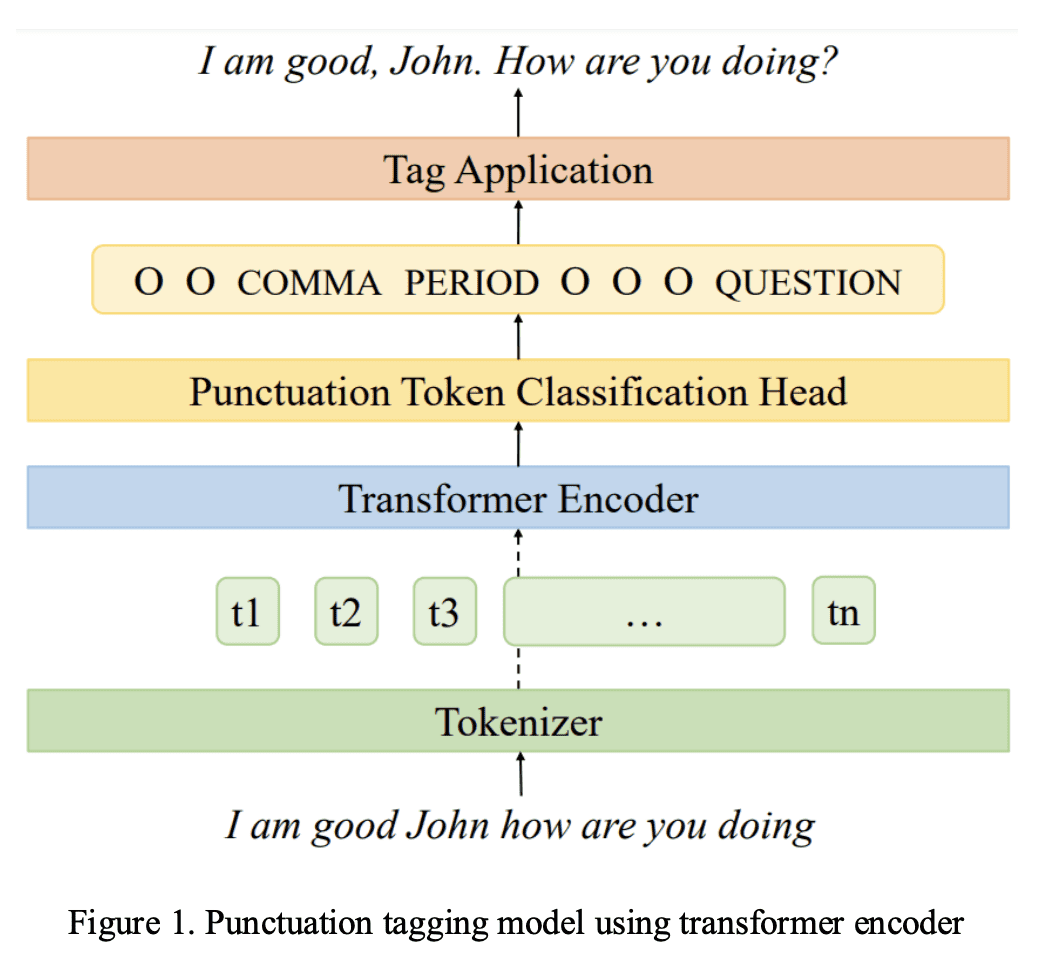
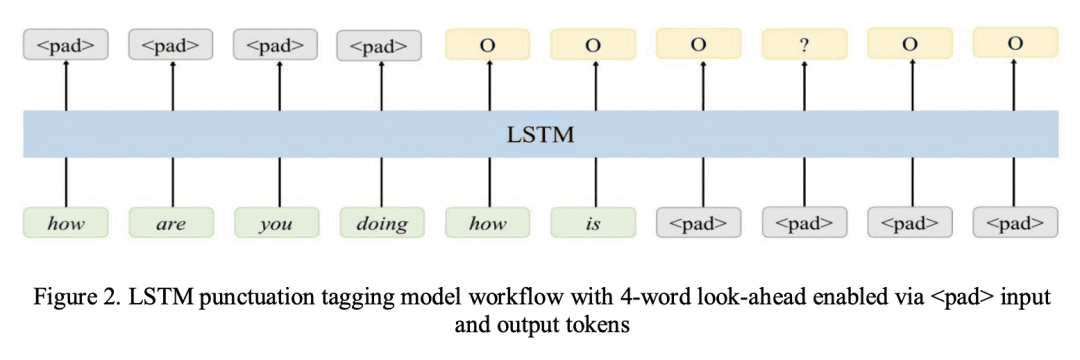
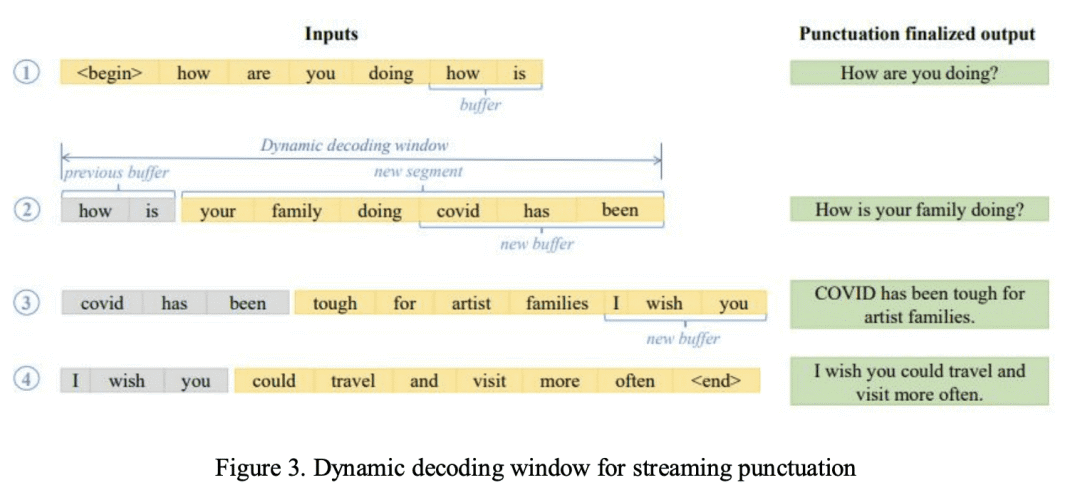
虽然英语语音识别单词错误率(WER)已经达到人类水平,但由于不规则的暂停模式或说话速度缓慢,语音输入和会议转录等连续语音识别场景仍然受到分割和标点符号问题的影响。Transformer 序列标记模型在捕获长双向上下文方面是有效的,这对自动标点标记至关重要。然而,自动语音识别(ASR)生产系统受到实时需求的限制,因此在做出标点决策时很难包含正确的上下文。ASR解码器生成的片段中的上下文可能有所帮助,但会限制连续语音会话的整体标点标记性能。本文提出一种用动态解码窗口对ASR输出进行标点标记或重标记的流方法,并测量其对跨场景标点和分割精度的影响。新系统解决了过度分割问题,将分割F0.5得分提高了13.9%。流标点在机器翻译(MT)下游任务中实现了0.66的平均BLEU得分提升。
While speech recognition Word Error Rate (WER) has reached human parity for English, continuous speech recognition scenarios such as voice typing and meeting transcriptions still suffer from segmentation and punctuation problems, resulting from irregular pausing patterns or slow speakers. Transformer sequence tagging models are effective at capturing long bi-directional context, which is crucial for automatic punctuation. Automatic Speech Recognition (ASR) production systems, however, are constrained by real-time requirements, making it hard to incorporate the right context when making punctuation decisions. Context within the segments produced by ASR decoders can be helpful but limiting in overall punctuation performance for a continuous speech session. In this paper, we propose a streaming approach for punctuation or re-punctuation of ASR output using dynamic decoding windows and measure its impact on punctuation and segmentation accuracy across scenarios. The new system tackles over-segmentation issues, improving segmentation F0.5-score by 13.9%. Streaming punctuation achieves an average BLEUscore improvement of 0.66 for the downstream task of Machine Translation (MT).
https://arxiv.org/abs/2301.03819
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢